Table of Links
A. Mathematical Formulation of WMLE
C Qualitative Bias Analysis Framework and Example of Bias Amplification Across Generations
D Distribution of Text Quality Index Across Generations
E Average Perplexity Across Generations
F Example of Quality Deterioration Across Generations
2 Background and Related Work
Bias Amplification. Bias amplification in machine learning models has been seriously studied in the context of visual recognition tasks. For example, Zhao et al. (2017) found that Conditional Random Fields can exacerbate social biases present in the training data. This study proposed an in-process mitigation approach, employing Lagrangian Relaxation to enforce constraints that ensure the model’s bias performance remains closely aligned with the biases in the training data. Following this, Mehrabi et al. (2022) proposed the concept of bias amplification in feedback loops, where biased models not only amplify the bias present in their training data but also interact with the world in ways that generate more biased data for future models. Xu et al. (2023); Zhou et al. (2024) examined bias amplification in recommendation models, showing how these models reinforce their understanding of mainstream user preferences from training data, leading to an overrepresentation of such preferences in historical data and neglecting rarely exposed items—similar to the concept of sampling error discussed in (Shumailov et al., 2024). Additionally, Wyllie et al. (2024); Taori and Hashimoto (2022) demonstrated that classifiers trained on synthetic data increasingly favor specific class labels over successive generations. Likewise, Ferbach et al. (2024); Chen et al. (2024) observed bias amplification in generative models such as Stable Diffusion, characterized by the overrepresentation of features from the training dataset. Moreover, we conducted a comprehensive review of the literature on model collapse which we put in Appendix L.
Political Biases. LLMs become a new form of "media" that people rely on for global news (Maslej et al., 2024), attracting significant research attention to political biases. Rettenberger et al. (2024b); Shumailov et al. (2024); Feng et al. (2024) explored the bias through voting simulations within the spectrum of German political parties, consistently finding a left-leaning bias in models like GPT-3 and Llama3-70B. Similarly, for the U.S. political landscape, Rotaru et al. (2024); Motoki et al. (2024) identified a noticeable left-leaning bias in ChatGPT and Gemini when tasked with rating news content, evaluating sources, or responding to political questionnaires.
3 Theoretical Framework
In this section, we formalize the conditions under which bias amplification occurs during recursive training on synthetic data. This framework is designed to intuitively illustrate the primary causes of bias amplification. Next, we demonstrate bias amplification and the theorem using Weighted Maximum Likelihood Estimation (WMLE).
3.1 The Conditions for Bias Amplification



The absence of such constraints allows bias amplification when bias projection is present. Based on these findings, we establish the following:
Theorem 1 (Condition for Bias Amplification). Bias amplification, a self-reinforcing process where a model trained on synthetic data amplifies the preexisting biases from previous training, leading to an increased bias in the data it generates for future training, occurs if both bias projection and constraint deficiency are present. It occurs only if there is bias projection in at least one parameter dimension and constraint deficiency is present.
Alongside understanding the causes of bias amplification, this also implies that bias amplification can occur even without model collapse. Specifically, statistical approximation and functional expressivity errors[1]—common causes of model collapse (Shumailov et al., 2024)—are unrelated with bias projection and constraint deficiency. This is further supported by our experiments in Sections 3.2 and 5.
3.2 Weighted Maximum Likelihood Estimation (WMLE)

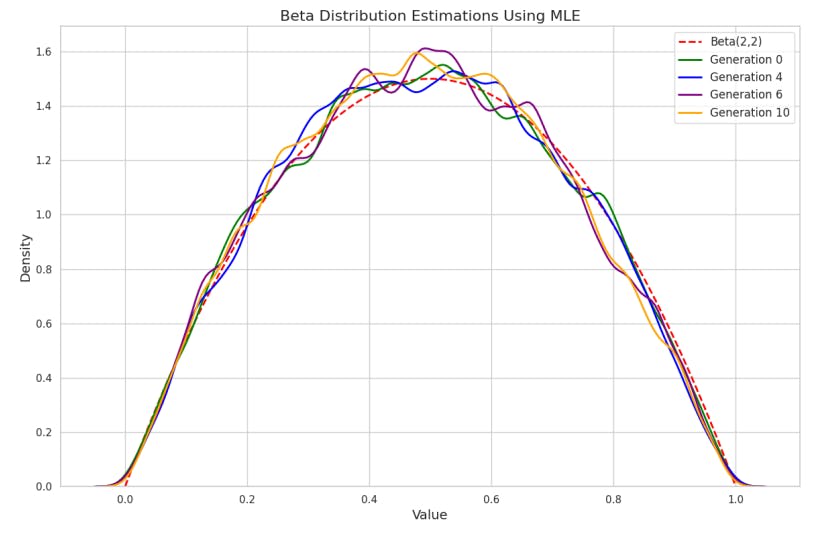
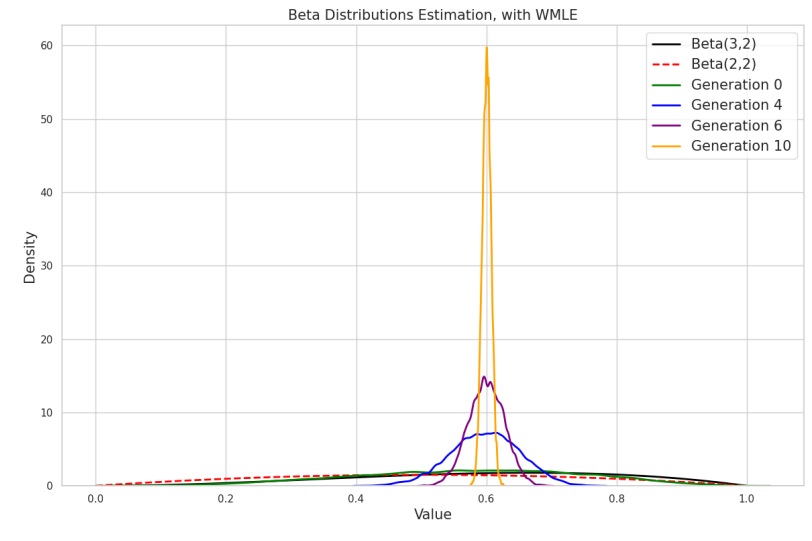
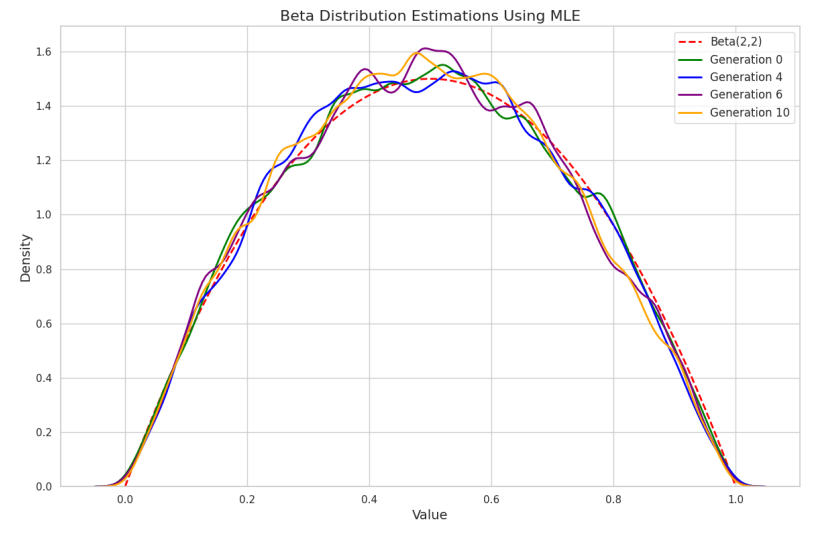
Results: As depicted in Figure 1, the estimated distributions progressively shift towards the mean of the biased Beta(α = 3, β = 2) distribution, at x = 0.6, becoming increasingly peaked with each generation. This behavior exemplifies bias amplification. The distortion arises from two sources: bias projection, where the estimation process emphasizes data regions where the ’biased’ pre-trained distribution assigns higher probability; and constraint deficiency, where WMLE lacks mechanisms to counteract the bias introduced by the weights, allowing the bias to be amplified over generations. For comparison, Figure 2 shows the results using standard MLE without weighting. The estimated distributions remain consistent across generations, accurately capturing the true Beta(2, 2) distribution. This indicates that without the influence of biased pre-trained pdf and the weighted learning process, bias amplification does not occur.
Authors:
(1) Ze Wang, Holistic AI and University College London;
(2) Zekun Wu, Holistic AI and University College London;
(3) Jeremy Zhang, Emory University;
(4) Navya Jain, University College London;
(5) Xin Guan, Holistic AI;
(6) Adriano Koshiyama.
This paper is available on arxiv under CC BY-NC-SA 4.0 license.
[story continues]
tags