Table of Links
3.2 Measuring Learning with Coding and Math Benchmarks (target domain evaluation)
3.3 Forgetting Metrics (source domain evaluation)
4 Results
4.1 LoRA underperforms full finetuning in programming and math tasks
4.2 LoRA forgets less than full finetuning
4.3 The Learning-Forgetting Tradeoff
4.4 LoRA’s regularization properties
4.5 Full finetuning on code and math does not learn low-rank perturbations
4.6 Practical takeaways for optimally configuring LoRA
Appendix
D. Theoretical Memory Efficiency Gains with LoRA for Single and Multi-GPU Settings
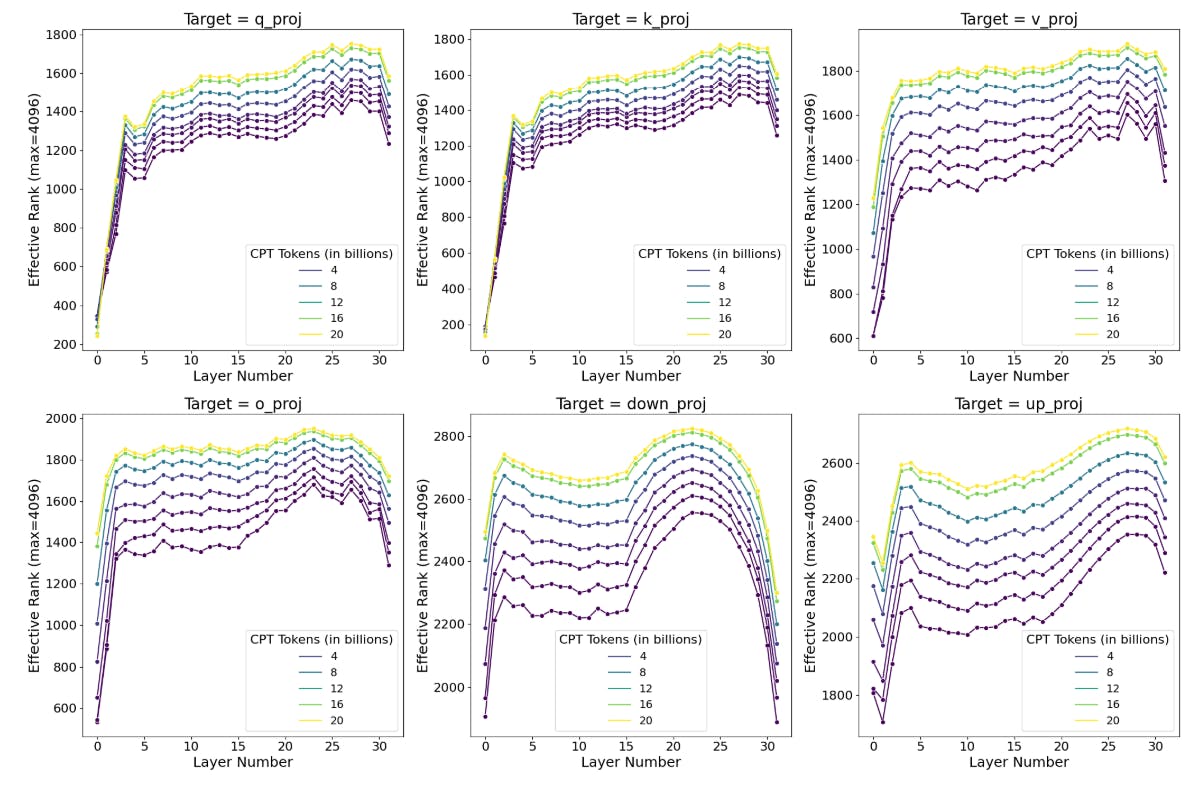
4.5 Full finetuning on code and math does not learn low-rank perturbations
Next, we ask when during training does the perturbation become high rank, and whether it meaningfully varies between module types and layers. We estimate the rank needed to explain 90% of the variance in the matrix. The results appear in Figure 7. We find that: (1) The earliest checkpoint at 0.25B CPT tokens exhibits ∆ matrices with a rank that is 10-100X larger than typical LoRA ranks; (2) the rank of ∆ increases when trained on more data; (3) MLP modules have higher ranks compared to attention modules; (4) first and last layers seem to be lower rank compared to middle layers.
4.6 Practical takeaways for optimally configuring LoRA
Though optimizing LoRA hyperparameters does not close the gaps with full finetuning, some hyperparamater choices are substantially more effective than others, as we highlight below.
4.6.1 LoRA is highly sensitive to learning rates
4.6.2 Choice of target modules matters more than rank
With the best learning rates at hand, in Fig. 9, we proceed to analyze the effect of rank (r = 16, 256) and target modules. We find that “All” > “MLP” > “Attention” and that though the effects of rank are more subtle, r = 256 > r = 16. We therefore conclude that targeting “All” modules with a relatively low rank (e.g., r = 16) provides a good tradeoff between performance and accuracy.
All in all, we recommend using LoRA for IFT and not CPT; identifying the highest learning rate that enables stable training; targeting “All” modules and choosing rank according to memory constraints, with 16 being a good choice; exploring training for at least four epochs.
Authors:
(1) Dan Biderman, Columbia University and Databricks Mosaic AI (db3236@columbia.edu);
(2) Jose Gonzalez Ortiz, Databricks Mosaic AI (j.gonzalez@databricks.com);
(3) Jacob Portes, Databricks Mosaic AI (jportes@databricks.com);
(4) Mansheej Paul, Databricks Mosaic AI (mansheej.paul@databricks.com);
(5) Philip Greengard, Columbia University (pg2118@columbia.edu);
(6) Connor Jennings, Databricks Mosaic AI (connor.jennings@databricks.com);
(7) Daniel King, Databricks Mosaic AI (daniel.king@databricks.com);
(8) Sam Havens, Databricks Mosaic AI (sam.havens@databricks.com);
(9) Vitaliy Chiley, Databricks Mosaic AI (vitaliy.chiley@databricks.com);
(10) Jonathan Frankle, Databricks Mosaic AI (jfrankle@databricks.com);
(11) Cody Blakeney, Databricks Mosaic AI (cody.blakeney);
(12) John P. Cunningham, Columbia University (jpc2181@columbia.edu).
This paper is