Table of Links
-
Method
-
Experiments
-
Performance Analysis
Supplementary Material
- Details of KITTI360Pose Dataset
- More Experiments on the Instance Query Extractor
- Text-Cell Embedding Space Analysis
- More Visualization Results
- Point Cloud Robustness Analysis
Anonymous Authors
- Details of KITTI360Pose Dataset
- More Experiments on the Instance Query Extractor
- Text-Cell Embedding Space Analysis
- More Visualization Results
- Point Cloud Robustness Analysis
3.3 Fine Position Estimation
Following the coarse stage, we aim to refine the location prediction within the retrieved cells. Based on the matching-free network [42], we introduce the query instance extractor to mitigate the dependency on ground-truth instances as input. Moreover, we propose a relative position-aware cross-attention module to incorporate spatial relation information in the position estimation process.

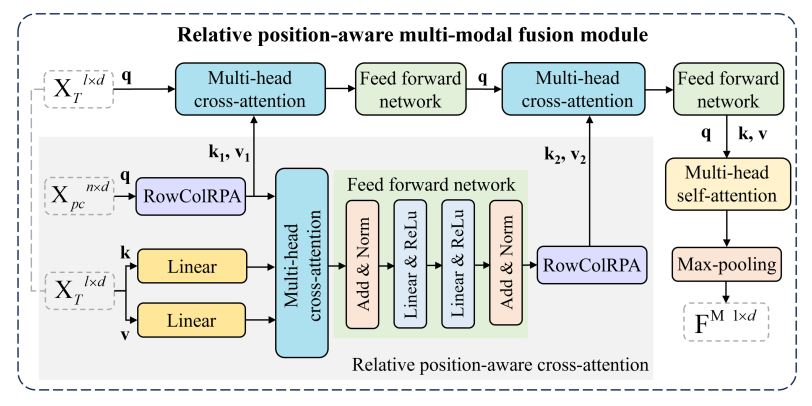
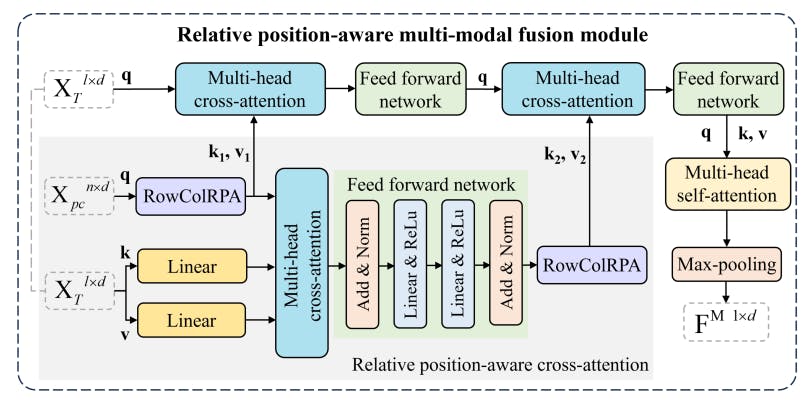
Relative position-aware cross-attention (RPCA). Within the multi-modal fusion module, we introduce the RPCA to integrate spatial relation information with the text-cell features, as shown in Fig. 5. The multi-modal fusion module consists of two crossattention modules and one RPCA module. The two cross-attention modules are configured with the text feature serving as the query and the point cloud feature as both key and value. The RPCA takes the point cloud feature as query and the text feature as key and value. To prepare the point cloud feature for RPCA, it first passes through a RowColRPA module, which crafts the query for RPCA and also generates the key and value (k1, v1) for the first cross-attention. Concurrently, the text feature undergoes two linear layers to get the key and value. Following the cross-attention operation, an additional RowColRPA is applied to create the key and value (k2, v2) for the second cross-attention. This design incorporates spatial relation features within the multi-modal fusion process.
3.4 Training Objectives


Authors:
(1) Lichao Wang, FNii, CUHKSZ (wanglichao1999@outlook.com);
(2) Zhihao Yuan, FNii and SSE, CUHKSZ (zhihaoyuan@link.cuhk.edu.cn);
(3) Jinke Ren, FNii and SSE, CUHKSZ (jinkeren@cuhk.edu.cn);
(4) Shuguang Cui, SSE and FNii, CUHKSZ (shuguangcui@cuhk.edu.cn);
(5) Zhen Li, a Corresponding Author from SSE and FNii, CUHKSZ (lizhen@cuhk.edu.cn).
This paper is
[story continues]
tags