Grading is the bottleneck of education. Teachers spend hundreds of hours manually reviewing descriptive answers, checking diagrams, and deciphering handwriting. It’s subjective, exhausting, and prone to inconsistency.
While Multiple Choice Questions (MCQs) are easy to automate, Descriptive and Diagrammatic answers have always been the "final boss" for EdTech.
Most existing solutions rely on simple keyword matching (TF-IDF) or basic BERT models, which fail to understand context or evaluate visual diagrams. In this guide, we are going to build a system that solves this using Retrieval-Augmented Generation (RAG) and Multimodal AI.
We will architect a solution that:
- Ingests textbooks to create a "Ground Truth" knowledge base.
- Uses Local LLMs (Mistral via Ollama) to generate model answers.
- Uses Semantic Search to grade text.
- Uses CLIP to grade student diagrams.
Let’s build.
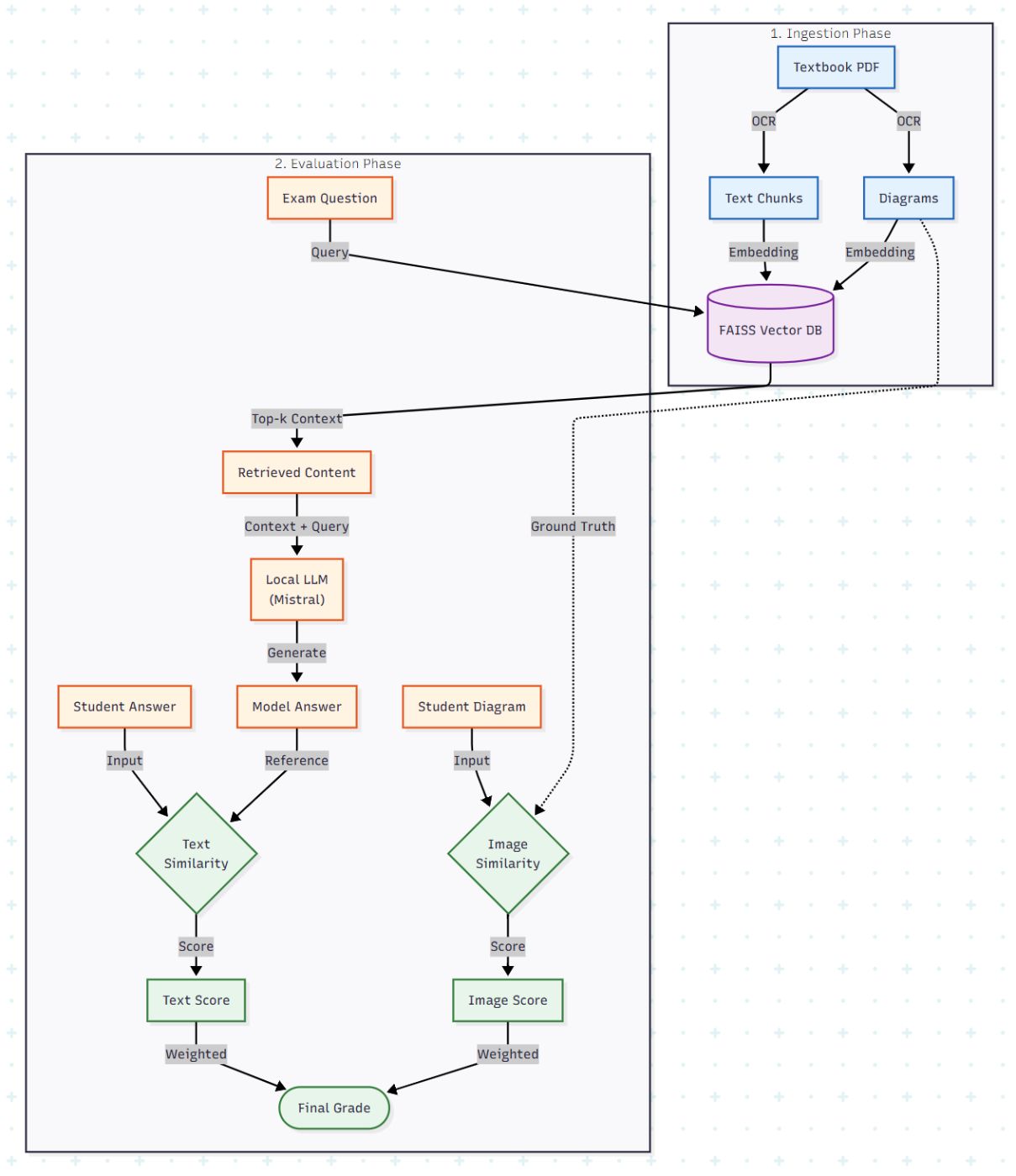
The Architecture: A Dual-Pipeline System
We are building a pipeline that handles two distinct data types: Text and Images. We cannot rely on the LLM's internal knowledge alone (hallucination risk), so we ground it in a Vector Database created from the course textbooks.
Here is the high-level data flow:
The Tech Stack
- LLM Runtime: Ollama (running Mistral 7B)
- Orchestration: LangChain
- Vector DB: FAISS (CPU optimized)
- Embeddings (Text): thenlper/gte-base or all-MiniLM-L6-v2
- Embeddings (Image): OpenAI CLIP (ViT-B-32)
- OCR: PaddleOCR (for extracting labels from diagrams)
Phase 1: The Knowledge Base (Ingestion)
First, we need to turn a static PDF textbook into a query-based database. We don't just want text; we need to extract diagrams and their captions to grade visual questions later.
The Extraction Logic
We use pdfplumber for text and PaddleOCR to find diagram labels.
import pdfplumber
from paddleocr import PaddleOCR
def ingest_textbook(pdf_path):
ocr = PaddleOCR(use_angle_cls=True, lang='en')
documents = []
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
# 1. Extract Text
text = page.extract_text()
# 2. Extract Images (Pseudo-code for brevity)
# In production, use fitz (PyMuPDF) to extract binary image data
images = extract_images_from_page(page)
# 3. OCR on Images to get Captions/Labels
for img in images:
result = ocr.ocr(img, cls=True)
caption = " ".join([line[1][0] for line in result[0]])
# Associate diagram with text context
documents.append({
"content": text + "\n [DIAGRAM: " + caption + "]",
"type": "mixed"
})
return documents
Once extracted, we chunk the text (500 characters with overlap) and store it in FAISS.
Phase 2: Generating the "Perfect" Answer (RAG)
To grade a student, we first need to know what the correct answer looks like. We don't rely on a teacher's answer key alone; we generate a dynamic model answer from the textbook to ensure it matches the curriculum exactly.
We use LangChain to retrieve the relevant context and Mistral to synthesize the answer.
from langchain.chains import RetrievalQA
from langchain_community.llms import Ollama
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
# 1. Setup Embeddings & Vector Store
embeddings = HuggingFaceEmbeddings(model_name="thenlper/gte-base")
vectorstore = FAISS.load_local("textbook_index", embeddings)
# 2. Setup Local LLM via Ollama
llm = Ollama(model="mistral")
# 3. Create RAG Chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(search_kwargs={"k": 3}),
return_source_documents=True
)
def generate_model_answer(question):
# Optimize prompt for academic precision
prompt = f"""
You are a science teacher. Answer the following question based ONLY on the context provided.
Question: {question}
Answer within 50-80 words.
"""
result = qa_chain.invoke(prompt)
return result['result']
Phase 3: Grading the Text (Semantic Similarity)
Now we compare the Student's Answer against the Model's Answer.
We avoid exact keyword matching because students phrase things differently. Instead, we use Cosine Similarity on sentence embeddings.
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2')
def grade_text_response(student_ans, model_ans):
# Encode both answers
embedding_1 = model.encode(student_ans, convert_to_tensor=True)
embedding_2 = model.encode(model_ans, convert_to_tensor=True)
# Calculate Cosine Similarity
score = util.pytorch_cos_sim(embedding_1, embedding_2)
return score.item() # Returns value between 0 and 1
Note: In our experiments, a raw similarity score of 0.85+ usually correlates to full marks. We scale the scores: anything above 0.85 is a 100%, and anything below 0.4 is a 0%.
Phase 4: Grading the Diagrams (CLIP)
This is the hardest part. How do you grade a hand-drawn diagram of a "Neuron" or "Flower"?
We use CLIP (Contrastive Language-Image Pre-Training). CLIP understands the semantic relationship between images. We compare the embedding of the student's drawing (or uploaded image) against the embedding of the "Gold Standard" diagram from the textbook.
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import torch
# Load CLIP
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def grade_diagram(student_img_path, textbook_img_path):
image1 = Image.open(student_img_path)
image2 = Image.open(textbook_img_path)
# Process images
inputs = processor(images=[image1, image2], return_tensors="pt", padding=True)
# Get Embeddings
outputs = model.get_image_features(**inputs)
# Normalize
outputs = outputs / outputs.norm(p=2, dim=-1, keepdim=True)
# Calculate Similarity
similarity = (outputs[0] @ outputs[1].T).item()
return similarity
Phase 5: The Final Grading Algorithm
Finally, we aggregate the scores based on the question type. If a question requires both text and a diagram, we apply weights.
The Logic:
- Length Check: If the student's answer is too short (<30% of expected length), apply a penalty.
- Weighted Scoring: Final Score = (Text_Score * 0.7) + (Diagram_Score * 0.3)
- Thresholding:
|
Similarity Score |
Grade Percentage |
|---|---|
|
> 0.85 |
100% (Full Marks) |
|
0.6 - 0.85 |
50% (Half Marks) |
|
0.25 - 0.6 |
25% |
|
< 0.25 |
0% |
def calculate_final_grade(text_sim, img_sim, max_marks, has_diagram=False):
if has_diagram:
# 70% weight to text, 30% to diagram
combined_score = (text_sim * 0.7) + (img_sim * 0.3)
else:
combined_score = text_sim
# Apply Thresholds
if combined_score > 0.85:
marks = max_marks
elif combined_score > 0.6:
marks = max_marks * 0.5
elif combined_score > 0.25:
marks = max_marks * 0.25
else:
marks = 0
return round(marks, 1)
Results and Reality Check
We tested this on CBSE Class 10 Science papers.
- Time Saved: Manual grading took ~20 minutes per paper. The AI took 5-6 minutes.
- Accuracy: The system achieved high alignment with human graders on descriptive answers.
- Challenge: CLIP struggles if the student's diagram is rotated or poorly lit. The text grader can sometimes be too lenient if the student uses the right keywords but in the wrong order.
Conclusion
We have moved beyond simple multiple-choice scanners. By combining RAG for factual grounding and CLIP for visual understanding, we can build automated grading systems that are fair, consistent, and tireless.
This architecture isn't just for schools, it applies to technical interviews, certification exams, and automated compliance checking.
Ready to build? Start by installing Ollama and getting your vector store running. The future of education is automated.
[story continues]
tags