Authors:
(1) Nicholas I-Hsien Kuo, Corresponding Author from Centre for Big Data Research in Health, Faculty of Medicine, University of New South Wales, Sydney, NSW, Australia (n.kuo@unsw.edu.au);
(2) Blanca Gallego, Centre for Big Data Research in Health, Faculty of Medicine, University of New South Wales, Sydney, NSW, Australia;
(3) Louisa R Jorm, Centre for Big Data Research in Health, Faculty of Medicine, University of New South Wales, Sydney, NSW, Australia.
Content Overview
- Abstract and Introduction
- Methods
- Results
- Discussion
- Conclusion and References
Abstract. Access to real clinical data is often restricted due to privacy obligations, creating significant barriers for healthcare research. Synthetic datasets provide a promising solution, enabling secure data sharing and model development. However, most existing approaches focus on data realism rather than utility – ensuring that models trained on synthetic data yield clinically meaningful insights comparable to those trained on real data. In this paper, we present Masked Clinical Modelling (MCM), a framework inspired by masked language modelling, designed for both data synthesis and conditional data augmentation. We evaluate this prototype on the WHAS500 dataset using Cox Proportional Hazards models, focusing on the preservation of hazard ratios as key clinical metrics. Our results show that data generated using the MCM framework improves both discrimination and calibration in survival analysis, outperforming existing methods. MCM demonstrates strong potential to support survival data analysis and broader healthcare applications.
1. Introduction
Access to real clinical data in healthcare is often restricted due to privacy guidelines and regulations, creating challenges for reproducibility and generalisability in clinical research [1,2]. Consequently, there is growing interest in realistic synthetic datasets that allow research while protecting patient confidentiality. While synthetic healthcare data generation has advanced, much of the focus has been on visual and statistical realism, often neglecting utility – the ability of models trained on synthetic data to produce results consistent with those trained on real data. Few studies have assessed the utility of synthetic datasets for survival analysis [3], a key method used in clinical research, including clinical trials and observational studies. This method often uses Cox Proportional Hazards (CoxPH) models [4] to estimate hazard ratios (HRs), which quantify the impact of variables on time-to-event outcomes like disease remission or death.
To address this gap, we propose Masked Clinical Modelling (MCM), a novel framework inspired by masked language modeling, as used in models like BERT [5]. MCM supports both data synthesis and conditional data generation, enabling data augmentation as well. Data synthesis creates realistic datasets for secure sharing, while data augmentation generates targeted data for specific subgroups (e.g., patients of certain sex and age), addressing dataset imbalances. This paper evaluates the MCM prototype using the well-established WHAS500 dataset [6].
2. Methods
2.1. The WHAS500 Dataset
The WHAS500 dataset is a subset of the broader Worcester Heart Attack Study (WHAS) [6], a long-term, population-based study aimed at understanding the incidence and survival outcomes following acute myocardial infarction. WHAS500 consists of 500 patients and is widely used for time-to-event analysis. To evaluate the performance of our MCM prototype, we focused on the following key features:
• Demographics: Age and sex.
• Measurements: Body mass index (BMI) and systolic blood pressure (SBP).
• Chronic Conditions: History of atrial fibrillation (AF) and congestive heart failure (CHF).
The baseline is a male patient with average BMI, normal SBP, and no history of AF or CHF. The primary endpoint is death. See detailed variable descriptions in [7].
2.2. Masked Clinical Modelling
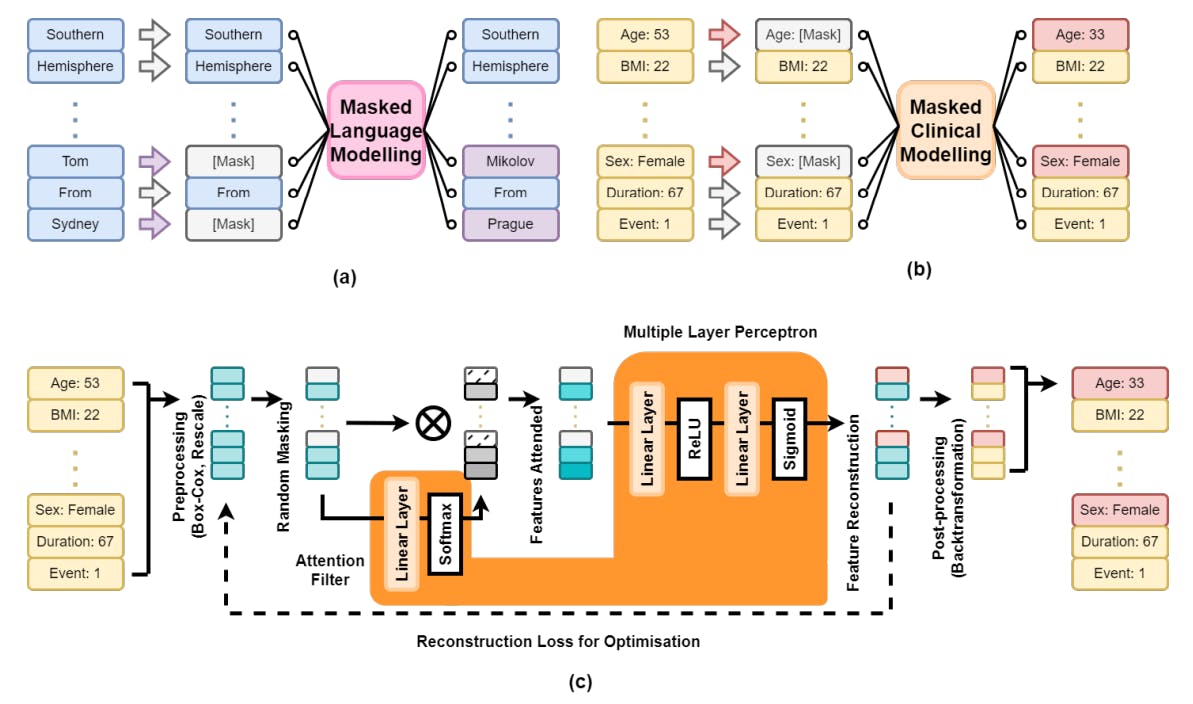
Figure 1 provides an overview of our Masked Clinical Modelling (MCM) framework. In subfigure (a), masked language modelling hides random words in a sentence, predicting the missing words using context. Subfigure (b) adapts this to MCM, where a patient’s clinical data x with N features is randomly masked (e.g., age, sex), and the model reconstructs the missing information from the remaining data. Subfigure (c) shows the engineering pipeline: pre-processing transforms x → v via Box-Cox transformation [8] to normalise numeric variables and rescale all features to [0,1]. After masking, the data is passed to the model.

This approach supports both data synthesis and augmentation. For synthesis, parts of an existing dataset are masked and reconstructed. For augmentation, patient profiles with specific traits can be generated. For example, to generate 300 patients aged 50–55 with follow-up times of 240–300 days, we create a data frame with 300 rows, sample the desired values from uniform distributions, and pass the incomplete data to MCM for completion. This enables the generation of clinically relevant data for downstream tasks.
We present a prototype MCM model with a two-layer MLP and 64 hidden dimensions. Due to space constraints, selected results are presented in the Results section, with a more detailed analysis planned for future work. Upon acceptance, all code will be made publicly available via GitHub.
3. Results
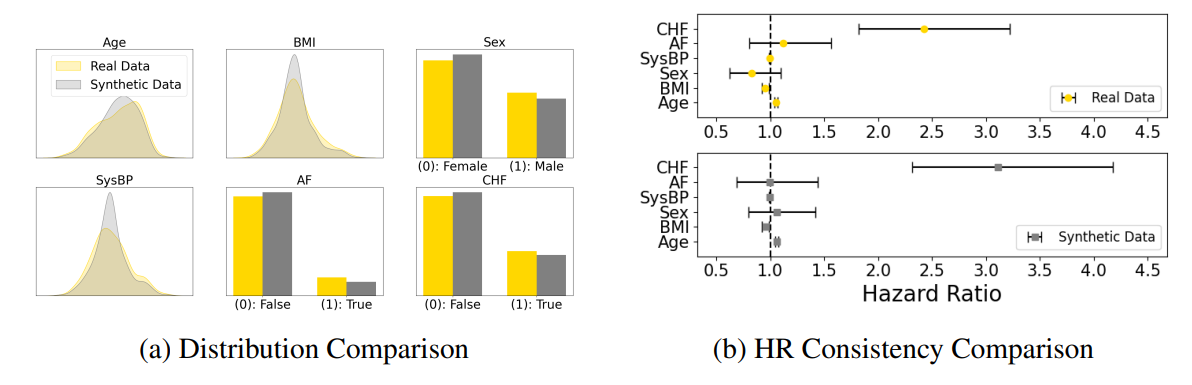
In Figure 2, we show how MCM generates synthetic data that closely mirrors the ground truth. After masking 75% of the real data, the model reconstructed the missing values. Subfigure (a) compares numeric distributions and binary variables, showing a strong match between real and synthetic data. To evaluate clinical utility, we trained a CoxPH model on both datasets, and compared the hazard ratios (HRs). Subfigure (b) demonstrates strong HR alignment, indicating that the synthetic data conserves meaningful correlations for downstream analysis.
We explore how synthetic data can augment ground truth to enhance the performance of a downstream CoxPH model, focusing on two key metrics: discrimination, measured by Harrell’s C-index [9] (higher is better, perfect discrimination is 1), and calibration, assessed by deviation from a perfect slope of 1 (lower is better). Results, summarised in Table 1, are based on a 5x2 cross-validation [10], with mean (SD) reported. Baseline comparisons include CoxPH models trained solely on real data and those augmented with synthetic data from SMOTE [11], VAE [12], MICE [13], and our MCM method. SMOTE detects minority classes and generates data through linear interpolation; VAE reconstructs data using a neural network with sampled latent features; and MICE imputes missing data using Bayesian ridge regression after masking [14]. All synthetic data are added to the training data for each cross-validation fold.
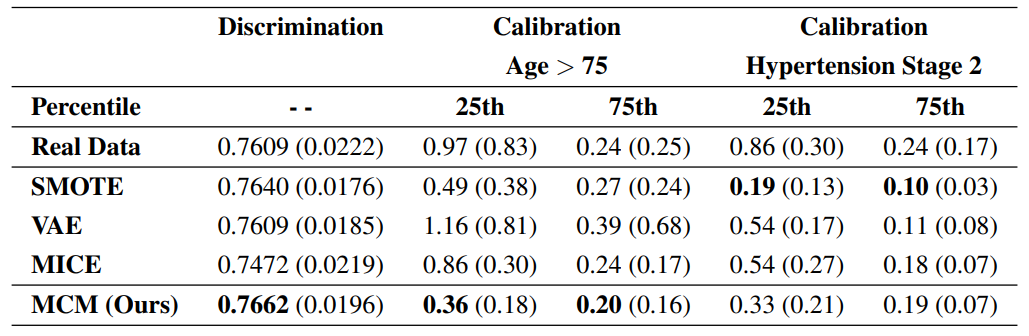
For discrimination, VAE, MICE, and MCM each generated 500 novel synthetic patients. MICE and MCM reconstructed data by randomly masking 50% of features; and SMOTE synthesised 70 additional patients from the minority class. Our MCM method produced the greatest improvement in the C-index, raising the score from 0.7609 to 0.7662. SMOTE provided slight improvement, VAE showed no effect, and MICE degraded the model’s performance.
For calibration, we stratified patients into two cohorts: 216 individuals aged over 75 and 276 with hypertension stage 2 (SBP > 140 mmHg). Calibration was computed at the 25th and 75th percentiles of time-to-event durations to evaluate synthetic data’s impact on risk prediction for high- and low-risk patients. VAE, MICE, and MCM conditionally generated 5 times the data for the stratified cohort; and SMOTE was employed to rebalance the underlying distributions. With real data alone, CoxPH showed poor calibration at the 25th percentile, with slope misalignments of 0.97 for the over-75 cohort and 0.86 for hypertension. MCM significantly reduced misalignments to 0.36 and 0.33, respectively. At the 75th percentile, where CoxPH performed well, MCM further improved calibration. MICE performed reasonably across scenarios, VAEs were good for hypertension but underperformed for the over-75 cohort, and SMOTE yielded mixed results.
4. Discussion
MCM introduces a novel approach to synthetic and augmented survival data generation. By adapting masked language modeling, it ensures both realism and utility by preserving key clinical metrics like HRs. Applied to the WHAS500 dataset, MCM demonstrated improved discrimination and calibration for survival analysis, outperforming SMOTE, VAE, and MICE in CoxPH tasks. Its conditional generation capability presents potential to minimise risks of identity disclosure and attribution (i.e., discovering something new about an individual) [15] in synthetic data by enriching datasets with more individuals having uncommon combinations of characteristics.
5. Conclusion
MCM balances data realism and utility, making it valuable for generating synthetic datasets that retain clinical insights. By preserving HR consistency, MCM supports data sharing in clinical research and education.
References
[1] N.I. Kuo, M.N. Polizzotto, S. Finfer, F. Garcia, A. Sonnerborg, M. Zazzi, M. Bohm, R. Kaiser, L. Jorm, and S. Barbieri, The Health Gym: Synthetic health-related datasets for the development of reinforcement learning algorithms, Scientific Data 9 (2022), 1–24.
[2] N.I. Kuo, O. Perez-Concha, M. Hanly, E. Mnatzaganian, B. Hao, M. Di Sipio, G. Yu, J. Vanjara, I.C. Valerie, et al., Enriching data science and health care education: Application and impact of synthetic data sets through the Health Gym project, JMIR Medical Education 10 (2024), e51388.
[3] A. Norcliffe, B. Cebere, F. Imrie, P. Lio, and M. Van der Schaar, SurvivalGAN: Generating time-toevent data for survival analysis, International Conference on Artificial Intelligence and Statistics (2023), 10279–10304.
[4] D.R. Cox, Regression models and life-tables, Journal of the Royal Statistical Society: Series B (Methodological) 34 (1972), 187–202.
[5] J. Devlin, BERT: Pre-training of deep bidirectional transformers for language understanding, arXiv preprint arXiv:1810.04805 (2018).
[6] R.J. Goldberg, J.M. Gore, J.S. Alpert, and J.E. Dalen, Incidence and case fatality rates of acute myocardial infarction (1975–1984): The Worcester Heart Attack Study, American Heart Journal 115 (1988), 761–767.
[7] D.W. Hosmer Jr, S. Lemeshow, and S. May, Applied Survival Analysis: Regression Modelling of Time-to-Event Data, John Wiley & Sons, 2008.
[8] G.E.P. Box and D.R. Cox, An analysis of transformations, Journal of the Royal Statistical Society: Series B (Statistical Methodology) 26 (1964), 211–243.
[9] F.E. Harrell, R.M. Califf, D.B. Pryor, K.L. Lee, and R.A. Rosati, Evaluating the yield of medical tests, JAMA 247 (1982), 2543–2546.
[10] T.G. Dietterich, Approximate statistical tests for comparing supervised classification learning algorithms, Neural Computation 10 (1998), 1895–1923.
[11] N.V. Chawla, K.W. Bowyer, L.O. Hall, and W.P. Kegelmeyer, SMOTE: Synthetic minority oversampling technique, Journal of Artificial Intelligence Research 16 (2002), 321–357.
[12] D.P. Kingma and M. Welling, Auto-encoding variational Bayes, International Conference on Learning Representations (2014).
[13] S. Van Buuren and K. Groothuis-Oudshoorn, MICE: Multivariate imputation by chained equations in R, Journal of Statistical Software 45 (2011), 1–67.
[14] D.J.C. MacKay, Bayesian interpolation, Neural Computation 4 (1992), 415–447.
[15] K. El Emam, L. Mosquera, and J. Bass, Evaluating identity disclosure risk in fully synthetic health data: model development and validation, Journal of Medical Internet Research 22 (2020), e23139.
This paper is available on ArXiv under CC 4.0 license.
[story continues]
tags