TL;DR —
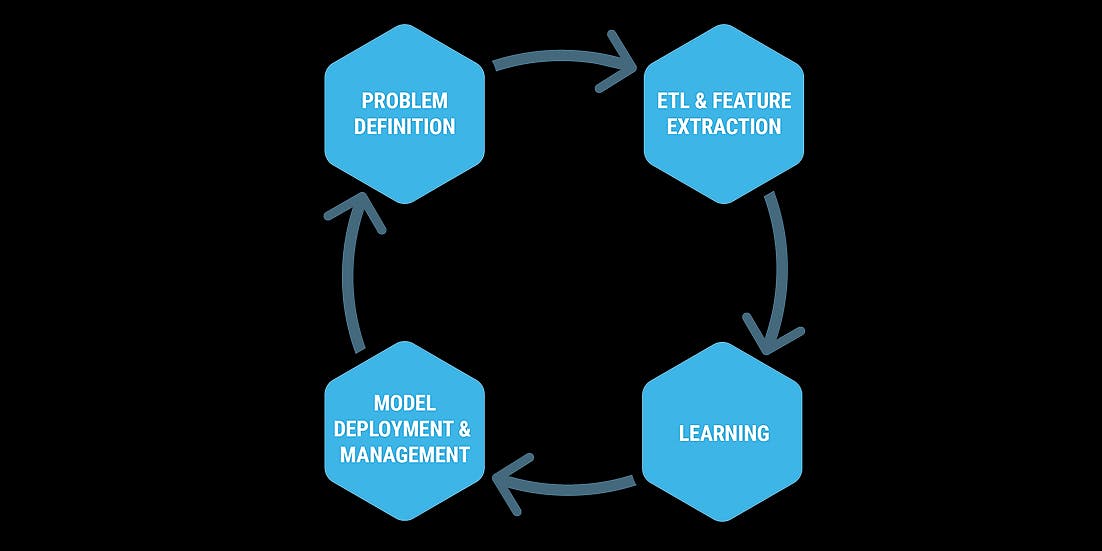
Working on a data science project is almost always equivalent to an amazing clutter in the working directory. Data scientists would most likely have the following materials dumped in their project working directory: Python/R scripts, data sets, journal articles, references, notebooks, scripts, notebooks and other references. The directory heirarchy is organized as repo/src/python/main/R, repo/source/py/lib (for utilities), repo/s/lib/main (for scala codes) An ansible-playbooks are created to automated repeatitive tasks.
[story continues]
Written by
@rick-bahague
Free & Open Source Advocate. Data Geek - Big or Small.
Topics and
tags
tags
datascience|git|datascience-workflow|latest-tech-stories|declutter-directories|working-directories|version-control|declutter-data-science
This story on HackerNoon has a decentralized backup on Sia.
Transaction ID: sWm5xVuieUlzWr9OFzD2LbPoqLbWoX3XZyu1aY0DPy0