
For decades, technical documentation was written for one audience: a human reader. Now, a more demanding, often overlooked reader sits on the other side of the screen: the Large Language Model (LLM).
The shift from Docs-as-Code to AI-Ready Documentation is the single greatest challenge facing technical writers today. Why? Because the way LLMs consume text stochastically, as discrete "chunks" of tokens, is fundamentally different from how a human reads a page.
Your formatting, structure, and linguistic choices are either fueling an intelligent Retrieval-Augmented Generation (RAG) system or leaving it with useless, orphaned pieces of context.
This article breaks down the architectural and stylistic mandate required to bridge this gap, ensuring your reStructuredText, AsciiDoc, and DITA XML source files are engineered for both human comprehension and seamless AI ingestion.
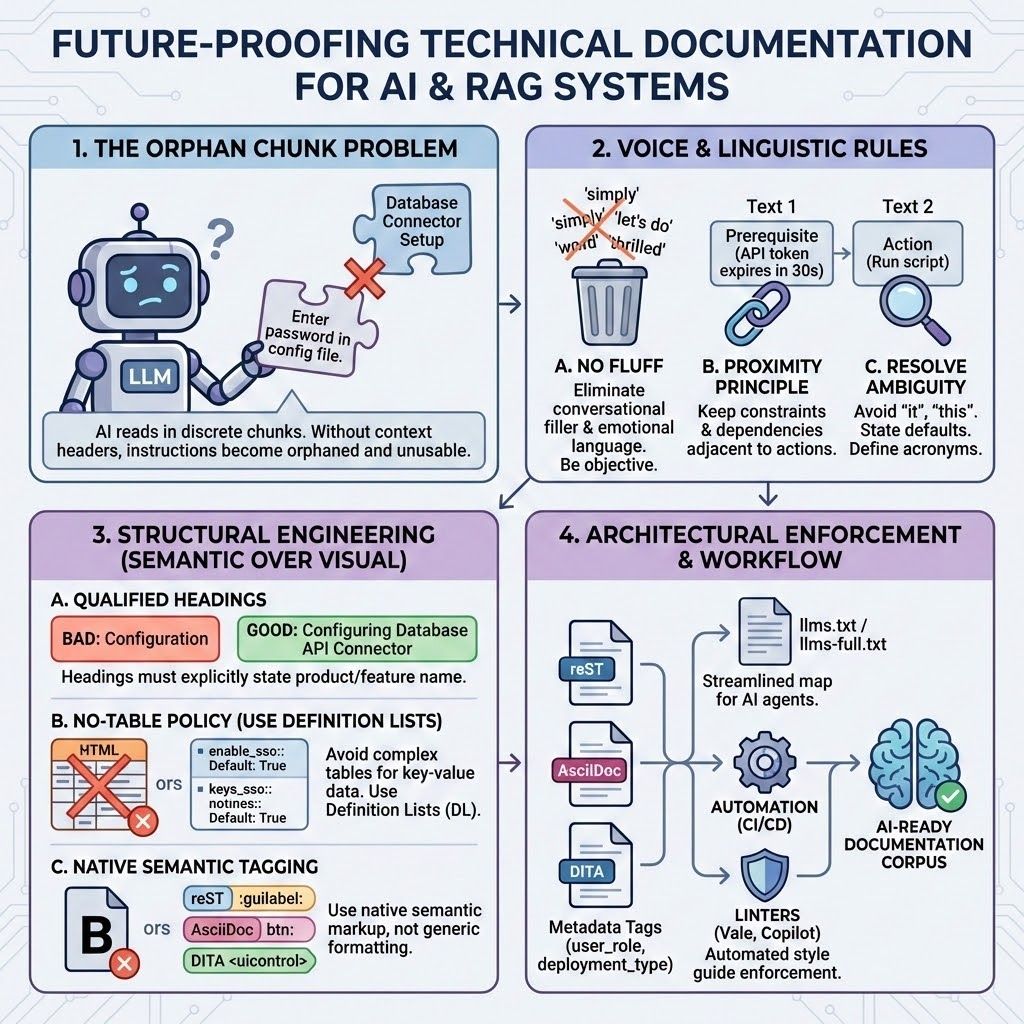
Understanding the AI's Reading Problem: The Orphan Chunk
AI systems do not read your entire document; they segment it into small, vectorized chunks based on token limits or logical boundaries. The core failure point of legacy documentation is the Orphan Chunk Problem.
Test Scenario: A RAG system retrieves a chunk that contains an instruction like, "Enter the password in the configuration file." But if the critical header "Database Connector Setup" was left behind in the previous chunk, the AI has no context. It doesn't know which configuration file to modify.
The Solution: Documentation must shift from conversational context to explicit, self-contained context at the chunk level.
Voice and Linguistic Rules for the LLM
To combat the Orphan Chunk and maximize semantic density, your language must be strictly objective and concise.
The "No Fluff" Policy
Extraneous words dilute the semantic weight of critical instructions for AI attention mechanisms.
- Eliminate Conversational Filler: Never use phrases like "let's do something," "simply," or "It's that simple." These provide no objective value to the LLM.
- Bad: To quickly get started, simply navigate to the settings page. It's that simple!
- Good: Navigate to the Settings page.
- Avoid Emotional/Qualitative Language: Keep the focus on verifiable, objective information. Avoid terms like "We were thrilled," "It worked beautifully," or "The result was terrible."
The Proximity Principle
The relationship between prerequisite information and an action is often lost across chunk boundaries.
- Rule: Keep all constraints, prerequisites, and dependencies immediately adjacent to the implementation guidance.
- Bad (Separated Context): (Paragraph 1) Note that the API token expires in 30 seconds... (Paragraph 5) Run the authentication script.
- Good (Proximity Applied): Authentication Script: Ensure your API token is generated. Tokens expire in 30 seconds. Run the authentication script.
Resolve All Ambiguity
LLMs cannot infer unstated information or resolve ambiguous pronouns across chunk boundaries.
- Rule: Avoid using "it" or "this" without a clear, explicit reference.
- Rule: State defaults explicitly (e.g., "The timeout defaults to 30s if not set").
- Rule: Define acronyms when they are first introduced (e.g., Large Language Model (LLM)).
Structural Engineering: Semantic Over Visual
The way you structure your content must prioritize semantic discoverability over visual presentation.
Qualified Headings Mandate
Generic headings are the number one cause of orphaned chunks. They tell the LLM what the section is but not what product it is about.
- Rule: Headings must explicitly state the product or feature name.
- Bad: Configuration
- Good: Configuring the Database API Connector
The "No-Table" Policy (Use Definition Lists)
Complex HTML tables often lose their key-value relationships when translated into the plain text consumed by LLMs, resulting in uninterpretable data.
- Rule: Avoid using tables for configuration parameters, API endpoints, or CLI flags.
- Solution: Format this critical data using Definition Lists (DL), which directly bind a key to its value across all Docs-as-Code formats:
- reST:
enable_ssofollowed by**Default:** True and **Description:**... - AsciiDoc:
enable_sso::followed by attributes. - DITA XML: The strictly-typed
<dl>,<dlentry>,<dt>, and<dd>elements.
- reST:
Enforce Native Semantic Tagging
Generic formatting (like **bold** or <u>underline</u>) is meaningless to a parsing algorithm. You must rely on the native semantic roles of your markup.
|
Format |
Generic Bold Tag |
AI-Ready Semantic Role |
Example |
|---|---|---|---|
|
reStructuredText |
**Click Submit** |
|
|
|
AsciiDoc |
*Click Submit* |
|
|
|
DITA XML |
|
|
|
Architectural Enforcement and Workflow
Style guides are useless without enforcement. Implement these standards to ensure your AI-Ready documentation architecture is sustainable.
Metadata-Aware Chunking
Enriching your source files with metadata enables RAG systems to pre-filter chunks, reducing the chance of retrieval failure. Every document should define the user_role and deployment_type.
- reST/Sphinx: Use the
.. meta::directive at the top of the file. - AsciiDoc: Define Document Attributes directly below the title (e.g.,
:user_role: System Administrator). - DITA XML: Leverage the
<othermeta>tag within the <prolog> element.
When a user queries "API setup for admins," the RAG system instantly filters for chunks matching user_role: System Administrator, dramatically improving precision.
Implementing the llms.txt Standard
The /llms.txt file format is an emerging standard to provide AI agents with a streamlined, structured map of your entire documentation corpus, bypassing the need for complex web parsing.
-
llms.txt: A markdown index file mapping core documentation links. -
llms-full.txt: A concatenated, plain-text/markdown corpus of all technical documentation for bulk ingestion.
Tools like sphinx-llms-txt for reStructuredText and DITA-OT Markdown Transtypes for DITA XML can automate the generation of these files during your normal CI/CD build process.
Automated Enforcement with Linters
To ensure every Pull Request adheres to the standard, integrate automation directly into your developer workflow:
- GitHub Copilot System Prompt: By setting up a
.github/copilot-instructions.mdfile, you can train Copilot to act as an automated technical editor, flagging generic headings, conversational filler, and non-semantic formatting before the code is merged. - Vale Linter: Use the Vale Linter to create custom YAML rules (like
GenericHeadings.ymlandConversationalFiller.yml) that programmatically enforce your style guide during CI/CD. Vale supports reST, AsciiDoc, and DITA XML natively, allowing it to ignore code blocks while policing your prose.
By adopting these principles, you move beyond merely writing for a screen and begin engineering a documentation corpus that is resilient, semantically rich, and ready for the next generation of AI-driven tools.
[story continues]
tags