TL;DR —
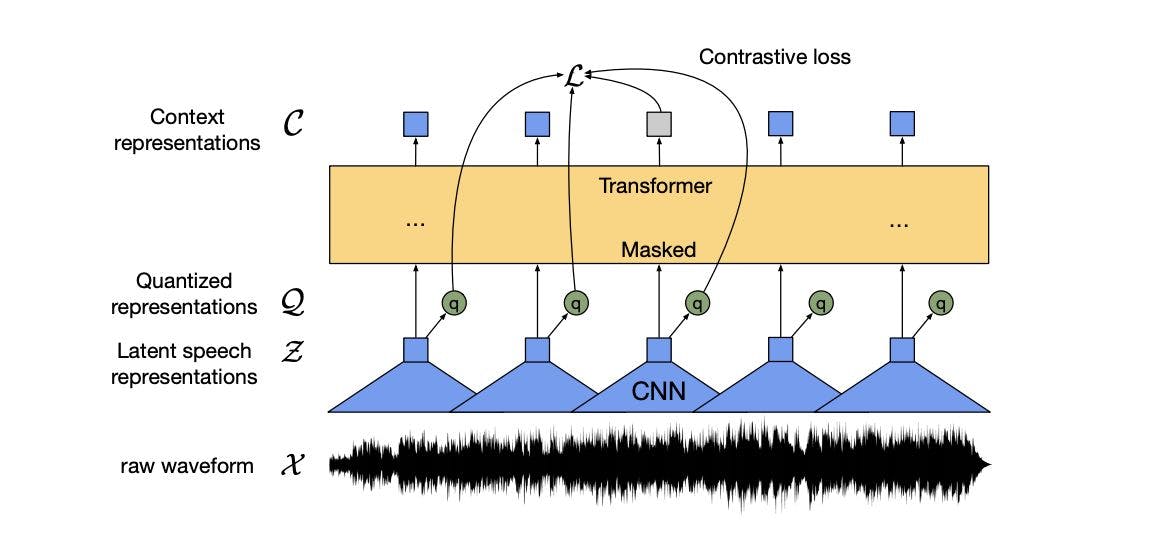
Facebook’s wav2vec 2.0 allows you to pre-train transcription systems using audio only — with no corresponding transcription — and then use just a tiny transcribed dataset for training. The LibriSpeech dataset is the most commonly used audio processing dataset in speech research. In this blog, we share how we worked with wAV2vec with great results. We show the transcription for one audio sample in the dev-clean dataset. In this example, the ASR has inserted an “a”, identified “John” as “Jones” and deleted the word “are” from the ground truth.
[story continues]
Written by
@zilunpeng
fin tech company
Topics and
tags
tags
speech-to-text-recognition|speech-recognition|machine-learning|artificial-intelligence|python|pytorch|speech-recognition-in-python|hackernoon-top-story
This story on HackerNoon has a decentralized backup on Sia.
Transaction ID: GtiU-hKara5Up_zsplzfsoBtANQ56HVgKyKmn93pjDQ