
If you think “tiering” started with SSD caches and cloud storage classes… congratulations: you’ve been successfully marketed to.
Hierarchical Storage Management (HSM) has been doing the same core job for decades:
Keep “hot” data on fast, expensive media… push “cold” data to slower, cheaper media… and make the user mostly forget you exist—until recall latency reminds them you do.
What changed over 50-ish years isn’t the idea. It’s the media, the interfaces, the scale, and the **ways vendors try to rename the same thing so procurement feels like it’s buying “innovation.” 😄
What is HSM, really?
Hierarchical Storage Management (HSM) is the storage world’s oldest magic trick: make expensive storage look bigger by quietly moving data to cheaper tiers—without breaking the namespace. Users see the same files. Admins see fewer “disk full” tickets. Everyone pretends recall latency isn’t real until someone double-clicks a 400 GB file that’s been living its best life on deep archive.
At its core, HSM is policy-driven data placement across a storage hierarchy, with some kind of recall path when data is accessed again. Historically that hierarchy was “fast disk → slower disk → tape/optical.” In modern stacks it’s often “hot → cool → cold → archive,” sometimes spanning on-prem, object, and cloud.
The five moving parts of classic HSM (and why each matters)
1) A primary tier: where “now” lives
This is the storage that must behave like storage:
- fast disk, SSD, high-perf NAS, scratch, or a parallel file system
- low latency and high throughput
- optimized for active workflows
This tier is not where you want decades of “just in case” to accumulate.
2) Secondary tiers: where “later” lives
HSM is only interesting if there’s a cheaper place to put cold data:
- capacity disk pools
- object storage
- tape libraries
- optical or other long-retention media
These tiers trade performance for economics (cost/GB, power, density, longevity). The whole HSM game is deciding what belongs where and when.
3) A policy engine: the brains (and the source of most arguments)
Policies decide what moves and why. Classic inputs look like:
- age/recency (mtime, atime, “last referenced”)
- size (large files are prime migration candidates)
- path/project (everything under /project/foo/ follows the foo rules)
- ownership (user/group-based policies)
- temperature (hot/warm/cold heuristics)
Modern policy engines add:
- tags/metadata (object systems)
- workflow signals (job completed, project closed)
- compliance state (retention, legal hold)
- cost signals (retrieval charges, egress exposure)
A good policy engine doesn’t just migrate data—it prevents you from migrating the wrong data and learning about it in production.
4) A recall mechanism: how the illusion stays intact
This is the “don’t break users” component.
In file-centric HSM, recall is often enabled by:
- stub files / placeholders that preserve name, size, timestamps, permissions, etc.
- file system hooks/events so “open()” triggers stage-back automatically
- throttling/queuing so one scan doesn’t recall the planet
In object-centric HSM/lifecycle, recall may look like:
- restore/rehydrate jobs
- copies into a hot bucket/work area
- temporary access windows
- explicit workflow steps instead of “transparent recall”
Either way, recall is where HSM becomes real. Migration is easy. Getting it back safely, predictably, and at scale is the hard part.
5) A migration engine: the muscle and the traffic cops
This is what actually moves bytes and keeps the system from melting down:
- movers (data transfer processes/hosts)
- queues and prioritization
- parallel streams
- bandwidth throttles
- media managers (especially for tape/robotics)
- retry logic, auditing, and state tracking
If you’ve ever seen a recall storm, you already know: the migration engine isn’t just a copier. It’s the difference between “smooth tiering” and “incident ticket with your name on it.”
What HSM is not (because people keep using the word wrong)
HSM is not backup
Backupis about recoverability after loss/corruption.
HSM is about space and cost optimization through relocation.
Some systems combine them, but the intent is different:
- HSM moves data out of primary to free space (and expects recall to work)
- Backup makes additional copies for recovery (and doesn’t assume the primary copy disappears)
If your “HSM” deletes primary data but you have no independent recovery story, that’s not HSM—that’s faith-based IT.
HSM is not caching
Caching copies hot blocks/data closer to compute while leaving the authoritative copy in place. HSM typically relocates entire files/objects to a different tier based on policy.
Caching says: “keep a fast copy nearby.”
HSM says: “this doesn’t belong on expensive storage anymore—move it.”
They can coexist (and often should), but they solve different problems.
The simplest way to think about HSM
HSM is a governed lifecycle for data placement:
- decide what’s hot vs cold
- move cold data to cheaper tiers
- preserve access semantics as much as practical
- control recall so it’s predictable
- track state so you can prove where data is and why
Old HSM did that with stubs and tape robots.
Modern HSM does it with lifecycle rules, object metadata, and restore workflows.
Same job. New interface. Same operational booby traps.
HSM vs ILM: same family, different job titles
People mix up Hierarchical Storage Management (HSM) and Information Lifecycle Management (ILM) because vendors spent two decades using both terms as interchangeable marketing confetti. They’re related, but they are not the same thing.
Think of it like this:
- HSM is a mechanism. It moves data between tiers.
- ILM is a program. It decides what the organization should do with data over time—and proves it did it.
SNIA’s framing is useful here: ILM is an ongoing strategy that aligns the value of information with policies, processes, and supporting infrastructure across the information lifecycle—not a single box you buy and plug in.
The lifecycle view: ILM starts before storage gets involved
ILM begins at the moment data is created or acquired and continues until final disposition. That lifecycle typically includes:
- Creation/Ingest (how it enters the org, what metadata/tags exist)
- Active use (who can access it, performance requirements)
- Collaboration/Sharing (distribution, replication, copies, versions)
- Protection (backup, snapshots, replication, integrity/fixity)
- Long-term retention (records, archives, research collections)
- Governance (legal holds, privacy rules, access controls)
- Disposition (deletion, destruction, transfer, reclassification)
HSM usually shows up in the middle of that story as the “move it to cheaper storage” execution layer—not as the policy authority deciding what’s kept, for how long, and under what legal constraints.
Practical translation (the one you actually use in architecture meetings)
HSM = the machinery (execution layer)
HSM is the set of technical capabilities that make tiering real:
- Tiering / placement across disk, object, tape, cloud classes
- Migration and purge rules to free primary storage
- Recall / restore workflows (stub recall, rehydrate, restore jobs)
- Movers and queues (throughput, throttling, prioritization)
- Media management (tape libraries, volume catalogs, robotics control)
- State tracking (resident/offline, restore in progress, pinned, etc.)
HSM answers: “Where does this data live today, and how do we move it?”
ILM = the governance layer (intent + accountability)
ILM is the framework that ties data handling to business and legal requirements:
- Retention schedules (keep 7 years, keep forever, keep until case closes)
- Compliance and auditability (prove it wasn’t altered; prove deletion)
- Legal holds (freeze disposition and sometimes freeze movement)
- Classification (public, internal, restricted, sensitive)
- Risk and cost management (what storage class is acceptable, retrieval tolerances)
- Disposition (defensible deletion, transfer, or preservation)
- Policy ownership (who approves, who changes, who signs off)
ILM answers: “What must happen to this data over its life, and can we prove it?”
Where people go wrong: buying “ILM” as if it’s a product
A lot of vendors sold “ILM” as a feature bundle. The problem is that ILM isn’t a feature, it’s a cross-cutting system of:
- organizational policy (records management, legal, security)
- operational processes (approvals, audits, exceptions, incident handling)
- tooling (metadata/tagging, analytics, movement engines, retention enforcement)
You can buy components that support ILM, but the “ILM” part is the coordination and accountability—and no vendor ships that preconfigured to match your regulatory obligations and internal politics. (If they claim they do, they’re selling you optimism.)
How they fit together in a modern stack
A useful way to describe it in your article:
- ILM defines intent: retention, access rules, acceptable latency, cost constraints, compliance obligations.
- HSM executes placement: migration, tier transitions, restore workflows, and enforcement mechanisms.
**Example:
**ILM says: “This collection must be retained for 25 years, immutable, with restores allowed but tracked, and retrieval should be under 24 hours.”
HSM implements: “After 90 days, transition to cold/archive tier; enable restore workflow; restrict who can rehydrate; log restores; enforce immutability.”
ILM is the ‘why’ and the ‘rules of the road.’ HSM is the ‘how’—the engine that moves data across tiers in a way that matches those rules, especially in file-centric and hybrid environments.
A quick timeline: mainframe → open systems → HPC → clustered file → object/cloud
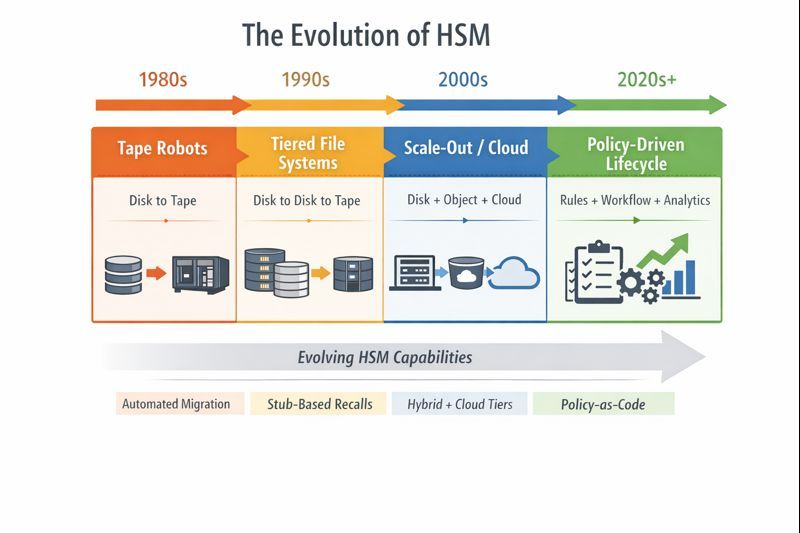
Mainframe roots (late 1970s through the 1980s): policy before it was cool
Mainframe HSM wasn’t born as a “nice-to-have.” It showed up because Direct Access Storage Device (DASD) was expensive, data growth was relentless, and nobody was volunteering to manually babysit data sets at 2 a.m. IBM’s Hierarchical Storage Manager (HSM) (later DFHSM, later DFSMShsm) was introduced in 1978 specifically to automate storage management for data sets using simple, repeatable criteria.
What mainframe HSM emphasized
- Automated space management: periodic, policy-driven cleanup and migration so primary pools didn’t stay “full forever.”
- Hierarchical “levels” of storage: data sets moved from primary volumes to cheaper tiers (including Migration Level 2 (ML2), typically on tape and usually not mounted/online).
- Operational stability: predictable policy cycles (batch windows), consistent reporting, and a control plane storage admins could actually run.
**Other HSM-type products in the same era \ IBM wasn’t the only one chasing the same outcome. A major “HSM-adjacent / competing” line on z/OS was CA Disk Backup and Restore (now Broadcom), which combined archive, space release, and movement across the storage hierarchy—meaning it attacked the same problem from a “data management suite” angle rather than IBM’s DFSMS-integrated path.
Key point: the mainframe world treated policy-driven automation as normal because it had to. You can’t staff your way out of exponential growth—especially when the platform is designed around repeatable operations, not heroics.
Open systems in the 1980s: UNIX grows up, libraries get robotic (and HSM becomes a “stack”)
As UNIX spread through labs, engineering shops, and early enterprise environments, HSM stopped being a single platform feature and turned into a vendor ecosystem: file services up top, media automation underneath, and a policy engine trying to keep disk from being treated like an infinite resource (spoiler: it wasn’t).
What open-systems HSM emphasized in this era
- Robotic tape libraries and optical jukeboxes become real infrastructure, not science-fair props.
- Media managers and volume services start to matter as much as the file system, because someone has to track cartridges, drives, mounts, and “where the heck did that volume go?”
This is where EMASS shows up as a true “HSM stack”
- EMASS FileServ was the HSM / file-space management layer—the part that handles file-level behavior and “make it look like it’s still there” logic.
- EMASS VolServ was the Physical Volume Library (PVL) layer—centralized media management, robotics control, mount/dismount automation, multi-client support, and the gritty details of running a library at scale. NASA/technical literature describes VolServ specifically in PVL terms (centralized media management and automated mounting/dismounting) and describes EMASS as a hierarchical mass storage family providing storage/file-space management.
In other words: FileServ is the “HSM brain for files,” VolServ is the “robot wrangler for media.” Together they’re a clean example of how open-systems HSM became modular.
And this era also includes HSM-adjacent “archiving as a file system” products
- ADIC AMASS framed long-term storage as something users could access with the same applications they used for disk—by presenting archive behind a file system-like abstraction over tape/optical libraries. That’s HSM behavior even when the marketing said “online archive.”
Key point: In the 1980s open-systems world, HSM becomes a layered architecture: file services + movers + volume/media management + robotics. That blueprint is basically the ancestor of today’s “lifecycle + object + cloud” designs—just with more SCSI and fewer REST APIs.
The 1990s supercomputer/HPC era: HSM becomes “mass storage” (and gets serious)
HPC forced HSM to graduate from “disk space janitor” to full-throttle data logistics. When your users are running multi-node jobs that can chew through terabytes like popcorn, HSM isn’t just about freeing space—it’s about feeding compute without turning the storage budget into a crime scene.
IBM HPSS (High Performance Storage System) is the canonical example of this shift. Its architecture explicitly includes a Migration/Purge function that provides hierarchical storage management through migration and caching between disk and tape, supporting multiple storage hierarchies and moving data up to fast tiers on access, then migrating it back down when inactive and space is needed.
What HPC-era HSM had to do well
- Parallel movers: multiple concurrent data streams to keep aggregate throughput high (because one mover thread doesn’t cut it).
- High-bandwidth staging: disk caches/staging layers sized and tuned to match compute and I/O peaks.
- Scalable metadata + policy selection: the system has to find candidate files fast, not spend all day thinking about it.
- Workflow integration: batch schedulers, project spaces, scratch vs. archive, and predictable recall behavior—because science runs on deadlines and coffee.
Representative products in the 1990s HPC “mass storage” lane
- NSL UniTree — described in HPC proceedings as acting like a virtual disk, automatically migrating files to cheaper storage via a programmable migration strategy.
- SGI DMF (Data Migration Facility) — positioned as an automated tiered-storage management system that creates and automatically manages a tiered virtual storage environment, handling migration and recall as part of normal operations.
- EMASS FileServ / VolServ — shows up heavily in NASA-era work as a hierarchical mass storage family providing storage / “file space” management, paired with a centralized volume/media layer for library automation (the “robot wrangler” side of the stack).
- NAStore (NASA Ames in-house HSM) — an internal HSM effort that NASA evaluated directly against commercial alternatives like FileServ, DMF, and UniTree, which tells you how strategic (and competitive) this space was in the 90s.
Why this era matters:
This is the point where HSM stops looking like “IT housekeeping” and starts looking like core scientific infrastructure—because in HPC, storage isn’t a closet. It’s part of the machine.
Late 1990s through the 2010s: stubs, DMAPI, clustered file systems, and enterprise sprawl
This is the era where HSM stopped being a niche “supercomputer thing” and turned into something normal people had to run—across messy fleets of UNIX, Windows, tape, disk, and (eventually) object targets. The big shift wasn’t a new idea. It was integration: better file-system hooks, better policy engines, and storage platforms that finally accepted they were part of a bigger workflow.
UNIX and friends: DMAPI, policy engines, and real automation
On UNIX, HSM matured because file systems and clustered/parallel designs started giving HSM what it always wanted:
- A shared namespace (one view of files, not “this host’s opinion”)
- Centralized policy evaluation (one ruleset, not 40 snowflakes)
- Coordinated movers (so recalls/migrations don’t fight each other)
- Fewer hilarious edge cases where a single server thinks it owns the universe
IBM Storage Scale / General Parallel File System (GPFS) is a good example of the “policy engine becomes first-class” pattern—rules select files and trigger actions like placement and migration. And when you bolt it to IBM High Performance Storage System (HPSS) via the GPFS HPSS Interface (GHI), you get the late-90s/2000s reference architecture: file system emits events, a daemon handles them, movers push/pull data to deep archive under Information Lifecycle Management (ILM) control.
Other HSM products that fit this UNIX/clustered file-system phase:
- Sun SAM-QFS / Oracle HSM — classic UNIX HSM architecture (stubs, policies, movers, tape integration) that was widely used in research/media environments.
- SGI DMF (Data Migration Facility) — strongly present in HPC and “big archive” shops; file-centric HSM with serious mover plumbing.
- IBM Tivoli Storage Manager (TSM) for Space Management (later Spectrum Protect for Space Management) — enterprise-grade HSM-style migration/purge/recall integrated with broader data protection tooling.
- Quantum StorNext Storage Manager — in media/entertainment and big unstructured workflows, it became a go-to “keep it online-ish, but pay archive prices” solution.
- Lustre HSM ecosystems — by the 2000s, parallel file systems like Lustre normalized the idea that “hot” lives on the file system and “cold” lives behind an HSM connector.
Windows: HSM grows a second head (and a lot of opinions)
Windows HSM is absolutely real, but it has always had more “please don’t poke my file handles” energy than UNIX.
- DiskXtender (OTG → Legato → EMC era) is the canonical Windows HSM story: stubs/placeholders on NTFS, automatic migration of inactive files, and transparent recall. (Same core behavior as UNIX HSM, just with more ways for apps and scanners to accidentally recall your archive.)
- IBM HSM for Windows is another explicit example: HSM for New Technology File System (NTFS) with stub/recall behavior, aimed at making Windows file shares survivable without buying infinite primary storage.
Enterprise sprawl: HSM ideas leak into “adjacent” domains
From the 2000s into the 2010s, the industry also started solving HSM-shaped problems in non-traditional places:
- Email/groupware archiving (ex: Zarafa Archiver) — lifecycle policies applied to mail stores.
- Compliance + tiering platforms (ex: PoINT Storage Manager) — rule-based movement plus retention behavior.
- Heterogeneous data movers (ex: Moonwalk) — “move cold data to cheaper tiers” across mixed file systems/object/tape.
Not all of these are classic file-system HSM. But they’re clearly in the same evolutionary branch: policy-driven movement, long-term retention, and keeping access predictable while storage gets cheaper per terabyte and more complicated per environment.
If you want, I can also add a tight one-paragraph “what changed operationally” closer for this section (stub storms, recall throttling, namespace governance, and why clustered metadata made the whole thing less fragile).
2010–2020: Policy Engines, Cloud Tiers, and the Death of “Just Buy More Disk”
NAS / file platforms that added object/cloud tiering (2015–2020)
- Dell EMC Isilon / PowerScale CloudPools — policy-based movement/tiering from OneFS (NFS/SMB) to object targets like S3/Azure (and OneFS-to-OneFS cloud). This is basically “HSM for NAS admins who don’t want to say HSM.”
- NetApp FabricPool — ONTAP feature that keeps hot data on SSD and tiers colder data to an object store (public or private), driven by policy.
Vendor-neutral policy engines for unstructured data (2013–2020)
- Komprise Intelligent Data Management — file analytics + policy-driven tiering/“right placing” of unstructured data across storage systems (file and object). Great example of HSM moving up the stack into “data management.”
- Data Dynamics StorageX — policy-based NAS file migration/tiering; later versions explicitly talk about S3-compliant storage support, which makes it a good “bridge to object” entry in this era.
- StrongLink — cross-platform policy engine that can tier/copy/move across storage types; by 2020 it’s explicitly pushing LTFS + policy-based management across silos (very “modern HSM”).
Tape gets modern interfaces (2015–2020)
- IBM Spectrum Archive (LTFS) — “tape as a file system” approach that became a common building block for active archive designs in the 2010s (often paired with higher-level policy engines).
- QStar Archive Manager + Network Migrator — presents archive behind file shares or S3 buckets and uses policy-based migration to push cold data to lower-cost tiers (tape/object/cloud).
- Atempo Miria — high-performance archiving/migration platform for massive unstructured data across heterogeneous storage; fits well in HPC/media “petabytes + billions of files” conversations.
Cloud-adjacent “stub & tier” services (late 2010s)
- Azure File Sync (Cloud Tiering) — explicitly separates namespace from content (stub-like behavior) and tiers file content to the cloud based on free-space and date policies. This is basically Windows-friendly HSM, but delivered as a service.
- Microsoft StorSimple (hybrid storage appliances) — early 2010s example of “use cloud as the capacity tier,” long before everyone pretended they invented hybrid tiering.
On-prem S3 object platforms that leaned into lifecycle (2015–2020)
These are good to mention as targets for modern HSM/lifecycle systems:
- Cloudian HyperStore — lifecycle policies / auto-tiering patterns in S3-land.
- Scality (RING/Artesca lifecycle tooling) — S3 lifecycle policy management shows how object platforms absorbed “HSM-like” automation.
The 2020s: HSM doesn’t die — it gets absorbed into object and cloud semantics
In the 2020s, HSM didn’t disappear. It got assimilated. Modern platforms increasingly treat tiering as a native capability, not a separate “HSM product” you install, pray over, and then avoid touching for five years.
What used to be a hierarchy of disk → nearline → tape now looks like hot → cool → cold → archive, driven by lifecycle rules, storage classes, and API-first workflows. Same mission, different wardrobe.
What “modern HSM” looks like now
- Lifecycle policies are built into object storage (on-prem and cloud): transition based on age, tags, prefix, versions, or compliance rules.
- Cloud storage classes + transition rules become the hierarchy: the platform decides where “cold” lives and how painful recall will be (latency + cost).
- Policy engines are everywhere, often expressed as config, rules, or JSON—less “the one admin who knows,” more “repeatable automation.”
Why this matters: the control plane shifted. Instead of POSIX stubs and DMAPI events, you’re dealing with object metadata, restore workflows, and billing-aware decisions. Recall isn’t “open() blocks for a bit.” It’s “restore job, wait window, then access.”
Cloud & object: HSM becomes “lifecycle”
This is where the big public platforms normalized the pattern:
- Amazon S3 Lifecycle transitions objects between classes, including archival tiers.
- Azure Blob lifecycle does the same across hot/cool/cold/archive.
- Ceph RGW lifecycle + storage classes brings similar semantics to S3-compatible private clouds.
The punchline: lifecycle policies are HSM by another name, with the bonus feature of “your finance team now gets to participate.”
On-prem vendors meet that world halfway (and sometimes sprint into it)
A lot of modern “archive” stacks are basically HSM outcomes with object-native interfaces:
- Versity ScoutAM / ScoutFS: positioned as a modern scale-out approach aimed at the scaling pain points of older mass-storage / HSM architectures—policy, lifecycle, and massive namespace management without the classic bottlenecks.
- Quantum ActiveScale: S3-oriented object storage that plays nicely in “object as the capacity tier” designs, including cold-storage handling patterns aligned with S3 semantics.
- Spectra Logic (StorCycle + BlackPearl): lifecycle/policy orchestration plus an object-facing deep-archive front door (often tape-backed), which is basically HSM translated into modern API language.
- GRAU DATA XtreemStore: “deep archive + object semantics” approach—tape economics with modern access patterns, showing how the archive tier is increasingly presented as S3/object rather than POSIX-only.
Other 2020s “HSM-type” products worth name-dropping
If you want this section to feel complete, these fit naturally:
File/NAS platforms adding object tiering (HSM baked into the filesystem)
- NetApp FabricPool
- Dell EMC Isilon/PowerScale CloudPools
- Qumulo / similar modern NAS platforms (varies by feature set, but the theme is “policy + tier target”)
Policy engines that sit above storage (HSM becomes “data management”)
- Komprise, StrongLink, Data Dynamics-style tools that analyze, classify, and move unstructured data across heterogeneous targets (NAS ↔ object ↔ cloud ↔ tape gateways).
Tape/object gateways and archive orchestration
- QStar, Atempo, and similar “front end the archive, automate the moves” stacks that bridge file workflows into object/tape-backed retention.
**So no—HSM didn’t vanish. \ It just stopped wearing a name tag that says “HSM,” because “Lifecycle Management” sounds like something you can put in a slide deck without getting heckled.
How parallel and clustered file systems supercharged HSM
Classic HSM worked… until it didn’t. The early model assumed a mostly single-host worldview: one file server, one namespace, one set of movers, and a user population that politely didn’t hammer “recall” on Monday morning like it was a fire drill.
At scale—especially in HPC and multi-department enterprise environments—HSM hit the same predictable walls:
The classic HSM bottlenecks (a greatest-hits album)
- Metadata coordination pain: HSM is fundamentally metadata-driven. You can’t migrate what you can’t find, and you can’t recall safely if multiple clients disagree about state (“online,” “offline,” “partial,” “staged,” “stubbed,” etc.).
- Recall storms: a single workflow change (new analysis job, crawler, antivirus scan, user running find / -type f) could trigger mass recalls. The archive tier doesn’t care that you’re impatient.
- Single-node mover ceilings: early designs often had a small number of mover hosts. That’s cute until your compute fabric can read faster than your movers can stage.
- Distributed access patterns the policies weren’t built for: “last access time” is a terrible policy input when 2,000 nodes touch a file once each in a burst. Congratulations, your HSM policy just got gaslit by parallel I/O.
Parallel and clustered file systems didn’t magically “fix” HSM. What they did was turn HSM from a fragile add-on into a native capability by giving it the primitives it always needed.
What clustered/parallel file systems changed
1) A real shared namespace (one truth, not 50 interpretations)
In a clustered file system, clients don’t each maintain their own fantasy about file state. There is one namespace, one set of attributes, and one consistent view of whether data is resident, stubbed, migrated, or staged.
That matters because HSM is basically a state machine:
- Is the file resident?
- Is it partially resident?
- Is there a stub?
- Is it in recall?
- Is it pinned?
- Is it eligible for migration?
Clustered file systems make that state authoritative.
2) Centralized policy evaluation at scale
HSM policies are only as good as the system’s ability to evaluate them efficiently:
- scan metadata
- select candidates
- execute actions
- track results
With clustered metadata, policy engines can operate against a global view and apply rules consistently. IBM Storage Scale / GPFS is a clean example: policy rules evaluate file attributes and then trigger actions like placement, migration, and pool selection. That’s the model: evaluate → select → act across storage pools, not “hope the right server runs the right script.”
3) Distributed movers (throughput scales with the cluster)
Once you stop treating movers as a couple of “special servers,” you can scale them:
- more movers
- more parallel streams
- better aggregate bandwidth
- fewer hot spots
In HPC, this is everything. If your archive tier can’t stage fast enough, the compute nodes sit idle. That’s not an IT problem—that’s a “we’re lighting money on fire” problem.
Clustered environments also enable throttling and fairness: you can rate-limit recalls, schedule migrations in off-peak windows, and avoid letting one project’s workflow melt the system.
4) Better event hooks and workflow integration
The other major improvement is event awareness—HSM responding to what users do, not just periodic scans.
DMAPI-style event models (where the file system generates events like open/read on migrated files) let HSM do:
- transparent recall (“you touched it, we’ll stage it”)
- controlled recall (queueing, throttling, priority)
- smarter policy (detect hot bursts vs long-term reuse)
This is where the system becomes operationally sane: you stop relying solely on cron-like sweeps and start reacting to real access patterns.
The “true hierarchy” pattern: file system + deep archive integration
Once you have clustered metadata + policy + events, you can build cleaner hierarchies where the file system is the user-facing layer and the archive system is the deep tier.
That’s exactly what the GPFS/HPSS Interface (GHI) pattern demonstrates: GPFS generates DMAPI events, an event daemon processes them, and movers push/pull data to HPSS under an ILM framework. In practice, GPFS provides the namespace and policy control plane, while HPSS provides the deep archive and tape-scale logistics.
What this enabled in the real world (the part people actually care about)
Parallel/clustered file systems didn’t just make HSM faster. They made it less fragile:
- Fewer “who owns this file state?” inconsistencies
- Better control of recall storms (queueing + throttling + prioritization)
- Policy engines that operate across the whole namespace
- A path to scale bandwidth by scaling movers and network, not by begging one server to work harder
And that’s why HSM survived into the 2020s: once clustered platforms made policy + metadata + movers coherent, HSM stopped being a bolt-on and started being a foundational pattern—even when the backend tier became object storage or cloud instead of tape.
UNIX vs Windows: same goal, different pain
On paper, UNIX and Windows HSM are chasing the same outcome: keep the namespace “whole,” push cold data to cheaper tiers, and recall it when needed. In practice, the two worlds evolved different mechanics—and different failure modes—because their file semantics and application ecosystems behave very differently.
UNIX HSM: predictable semantics, better hooks, fewer surprises (usually)
UNIX-style HSM tends to work well because it can lean on a few friendly realities:
1) File system event models and hooks
UNIX environments historically had stronger “this file was touched” integration points—think DMAPI-style event models where the file system can emit events when a process opens/reads a migrated file. That enables a clean pattern:
- user opens file
- file system notices it’s offline/stubbed
- HSM gets an event
- recall is queued/throttled
- file becomes resident again
This is why UNIX/HPC HSM implementations often feel more “native” to the platform: the recall path can be tightly coupled to file system behavior instead of being a bolt-on filter driver.
2) “Stub + recall” fits POSIX expectations better
POSIX-ish tools generally tolerate the concept that:
- stat() works even if the file’s data blocks aren’t local
- permissions/ownership behave consistently
- errors are interpretable (“file not resident,” “staging,” etc.)
- HPC workflows can be structured to stage explicitly (pre-stage) before compute runs
Even when it’s annoying, it’s at least coherent. UNIX admins can also script around it with relative confidence—because UNIX tooling is built on the assumption that storage might be slow, remote, or transient.
3) Control knobs are aligned with ops realities
UNIX/HPC HSM stacks commonly give you operational levers that matter:
- recall throttling
- prefetch/stage policies
- pinning/never-migrate flags
- project-based policies by path, owner, group, filesystem
This makes it easier to run HSM as part of a larger workflow rather than as an after-the-fact clean-up crew.
Windows HSM: the same concept, but the ecosystem fights you
Windows HSM works, but it has to survive an environment where lots of software assumes storage is always fast and always local—even when it’s hosted on a file server and the “disk” is a tape library in a trench coat.
1) Applications often assume fast random access forever
Many Windows apps (and plenty of third-party components) behave like:
- “Open file” implies “instant read”
- lots of small random reads
- frequent metadata probing
- no tolerance for multi-minute recall latency
That’s rough when your “cold tier” is tape or deep archive. UNIX/HPC users expect “stage first.” Windows users expect “it’s a file, therefore it should open.” Those are not compatible religions.
2) The hidden villains: indexers, AV scanners, and ‘helpful’ background services
Windows environments are full of well-meaning automation that touches files just enough to trigger recalls:
- Indexing services crawling a share
- Antivirus scanning everything it can see
- eDiscovery / DLP / compliance agents doing “light reads”
- Backup/DR tooling enumerating and verifying files
In HSM land, “light touch” can still equal “recall the entire file.” This is where admins learn to fear anything that does recursive scans.
3) Backup software + stubs = confusion (unless you’re careful)
Stub files and placeholders are central to Windows HSM. But backup systems can:
- back up the stub (useless) instead of the data (bad)
- trigger recalls to back up full content (worse: recall storm)
- mis-handle reparse points / offline attributes depending on vendor
So Windows HSM almost always requires explicit backup integration planning:
- decide whether backups operate on the primary tier only
- whether backup is allowed to trigger recall
- whether archived content is protected separately at the archive tier
4) “Transparent recall” is technically true… operationally messy
IBM’s documentation for Windows HSM is very explicit that it supports stubs/placeholders and transparent recall behavior—that’s the core user experience goal.
The catch is that transparency can be a trap: users and applications can unknowingly trigger recalls at scale because nothing “looks” different in Explorer.
Practical bottom line: where each platform shines
UNIX HSM is usually best when:
- workloads are batch/HPC/media pipeline
- you can pre-stage or schedule recall
- policies can be aligned to projects, paths, and compute workflows
- clustered/parallel file systems provide strong hooks and metadata scale
Windows HSM is usually best when:
- the goal is file-share capacity relief
- recall volume is moderate and predictable
- you can tightly control indexers/AV/backup behaviors
- the organization accepts that “archive tier” means “slower, sometimes a lot slower”
What changes when cloud storage shows up?
Cloud doesn’t kill HSM. It changes who’s driving.
Classic HSM lived in your data center: you owned the tiers, the robotics, the movers, the recall queue, and the “why is staging slow” war room. When cloud shows up, the HSM control plane shifts upward into the storage service itself—and your “tiers” become storage classes with lifecycle policies and restore workflows.
In other words: the same game, but now the referee is also your invoice.
1) HSM becomes “lifecycle + class transitions”
Instead of “disk → tape” being a local design choice, cloud platforms formalize the hierarchy as classes and let you define transition rules:
- Storage class transitions (“after X days, move to cheaper tier”)
- Lifecycle rules based on age/prefix/tags/versions
- Retention & governance hooks (immutability, legal holds, object lock—depending on platform)
This is textbook HSM behavior, just expressed as platform policy. For example, Amazon S3 Lifecycle can automatically transition objects to archival tiers, and Azure Blob lifecycle management can transition blobs across hot/cool/cold/archive in a similar rule-driven model.
2) “Recall” becomes a restore workflow (and it’s no longer just “slow”… it’s a process)
In classic HSM, recall usually meant: queue the request, fetch from tape, stage to disk, let the app proceed. The pain was mostly time.
In cloud, recall is often an explicit restore operation with:
- A restore request (API call / lifecycle action / console workflow)
- A waiting period (hours can be normal in archival tiers)
- A temporary accessibility window (sometimes you specify how long it should be restored)
- Potential retrieval fees and request charges
So your old “tape delay” becomes a workflow dependency. It’s not just latency—it’s orchestration. S3’s lifecycle + archival tiers are a good example: you can transition objects into archive classes, but you also inherit the restore semantics and operational constraints of those tiers.
3) Metadata and inventory suddenly matter a lot more
In traditional HSM, “what tier is it on?” was internal state. In cloud/object systems, you tend to manage by:
- Object metadata / tags
- Prefixes
- Inventory reports
- Storage analytics
- Versioning state
Why? Because your policy engine is operating on object attributes, not POSIX file-system events. If you can’t see the state cheaply (inventory/metrics), you’ll make bad lifecycle decisions—or you’ll discover them on the bill.
4) Billing becomes an HSM constraint (and sometimes the dominant one)
Old HSM decisions were mostly:
- media cost
- performance
- operational burden
Cloud adds:
- retrieval cost
- request cost
- early deletion penalties (some archival tiers)
- egress/network costs (especially cross-region or out of cloud)
- API rate limits and per-request overhead
That changes behavior. Teams start asking questions they never asked on-prem:
- “Is it worth restoring this or should we reprocess from source?”
- “Can we stage locally and batch restores?”
- “Should we replicate, version, or do we pay twice forever?”
Your archive tier is no longer a passive “cheap basement.” It’s an active financial instrument.
5) Hybrid becomes the default architecture
Most shops don’t flip a switch from “HSM” to “cloud.” They end up with hybrid patterns:
- On-prem file system + cloud/object as capacity tier
- Cloud-native object + on-prem cache/edge tier
- Tape/object gateways that present S3 interfaces while keeping tape economics
This is exactly why modern vendors pitch “lifecycle management” rather than “HSM”: the tiers can be anywhere, and the orchestration spans multiple control planes.
6) Ceph RGW and S3-compatible ecosystems: cloud semantics without hyperscalers
In Ceph RGW and other S3-compatible environments, lifecycle-driven transitions exist as well. The mechanics can vary by implementation (and sometimes include constraints like one-way transitions or limited class behaviors), but the underlying shift is the same: policy is expressed in object terms and executed by the platform.
The big operational shift (the part your app teams will absolutely notice)
Cloud turns “recall latency” into a three-part problem:
- Time (restore delay)
- Money (retrieval + request + possibly egress)
- Process (who triggers restore, how long it stays restored, what workflows depend on it)
That’s why application teams suddenly care a lot about “what tier is this in?” In cloud, tier choice hits performance and budget at the same time, and nobody likes surprises—especially the kind that show up as a four-figure line item labeled “retrieval.”
Sidebar: Cloud HSM Anti-Patterns (a.k.a. how to accidentally finance your provider’s next yacht)
Here are six very common ways teams create recall storms and retrieval bills that feel like extortion (but with better UX):
-
Let’s just run a recursive scan.”
Someone points an indexer, antivirus, DLP tool, or discovery crawler at an object-backed namespace (or file gateway) and it “helpfully” touches everything. If those touches trigger restores/reads, you’ve just scheduled a surprise mass recall.
-
Treating archive like a slower version of standard storage
Teams transition data to archive tiers and keep the same application behavior—random reads, lots of small GETs, frequent reprocessing. Archive tiers are not “cheap disk.” They’re a cost/latency contract with consequences.
-
No restore orchestration (aka “YOLO restore”)
Restores kicked off ad hoc by users/apps without queueing, throttling, or prioritization. Result: clogged restore pipelines, missed deadlines, and a bill that looks like a phone number.
-
Life-cycle rules without lifecycle governance
“After 30 days, shove it to Glacier/Archive” sounds smart until Legal needs it tomorrow, or the workflow still references it weekly. Lifecycle must align with actual access patterns, not wishful thinking.
-
Ignoring minimum storage durations / early deletion penalties
Some archive tiers have minimum retention periods. Transitioning too aggressively (or deleting/overwriting too quickly) can trigger charges that make your “savings” evaporate.
-
Egress amnesia
The archive data might be cheap to store, but pulling it out—especially cross-region or out of cloud—can be expensive. If your plan is “restore everything back on-prem for processing,” congrats, you’ve invented a budget bonfire.
One-line fix mindset: Treat cloud archive like tape with an API: plan restores, batch reads, control scanners, and make lifecycle decisions based on measured access—not optimism.
What changes as we move from POSIX to Object Storage?
This is the point in the story where a lot of seasoned HSM instincts have to be… politely dismantled and rebuilt. Classic HSM grew up in a POSIX world where everything is a file, the namespace is sacred, and “recall” is supposed to be transparent. Object storage flips that: the namespace is optional, the API is the interface, and “recall” is often an explicit workflow step.
Same goal—right data, right tier, right cost—but the mechanics and mental model change hard.
POSIX-first HSM (classic): “keep the illusion alive”
Traditional HSM is built around the POSIX contract:
- Files and directories are the user experience
- Pathnames are identity (move/rename is meaningful)
- Permissions/ownership are enforced through the file system
- Apps use open/read/close and expect data is there when they do
So classic HSM optimizes for one thing above all: preserve the illusion that the file is still “right there.”
How it does that
- Stubs/placeholders: the file still exists in the directory tree, but the payload has been migrated.
- Transparent recall: touch the file, HSM stages it back (often via file system hooks/events).
- Policies are file-centric: path patterns, uid/gid, project directories, file size, atime/mtime, “don’t migrate these extensions,” etc.
The strengths:
- Minimal app changes (in theory)
- Users stay productive in familiar tools
- Works beautifully for workflows that are mostly sequential and predictable
The weaknesses:
- Stub storms (indexers, crawlers, AV, backup tools)
- Metadata-heavy scanning at scale
- “Transparency” becomes operational risk when anything touches everything
Object-first lifecycle (modern): “stop pretending, start governing”
Object storage isn’t trying to be a file system. It’s an API-driven key/value store with metadata, and identity is usually:
- Bucket + key (often a prefix-based pseudo-directory)
- Plus tags/metadata
- Plus versioning state
- Plus storage class / tier
Apps don’t “open() a file.” They GET an object, often in chunks, often repeatedly, often via distributed clients.
What lifecycle looks like in an object world
Lifecycle engines operate on:
- Age (days since creation/last modified)
- Prefix (“everything under this keyspace”)
- Tags (“Project=NDNP”, “Retention=7Y”, “LegalHold=True”)
- Versions (noncurrent version transitions, expiration rules)
Instead of stubs, you get:
- Storage class transitions (hot → cool → cold → archive)
- Restore workflows for archival tiers (explicit “rehydrate” steps)
- Sometimes copy-on-restore patterns (restore to a new location/class)
Object storage is less “transparent recall” and more “stateful data governance.”
The big differences that matter operationally
1) Namespace identity changes (paths vs keys)
In POSIX, the path is everything—rename and moves have meaning and usually preserve identity. In object storage:
- the “directory” is usually just a key prefix convention
- “rename” often means copy + delete (expensive at scale)
- identity and policy control tend to ride on tags/metadata, not directory trees
2) Metadata becomes your control plane
Classic HSM uses file attributes and file system metadata scanning.
Object lifecycle relies on:
- object metadata / tags
- inventory reports
- analytics about access patterns, size distributions, version churn
If you don’t invest in inventory + visibility, lifecycle becomes guesswork—and guesswork becomes cost.
3) Access patterns shift from stateful IO to stateless requests
POSIX IO:
- open/read/write/close
- lots of small metadata checks
- sequential streaming is common in HPC/media
Object IO:
- stateless GET/PUT
- retries are normal
- parallel clients are common
- request rate (and per-request cost) matters
This changes what “recall storm” looks like. In object land, it’s not “everyone opened a stub.” It’s “a million small GETs and restore requests hit at once.”
4) “Recall” changes meaning
In file HSM:
- recall = stage the file back to disk and satisfy POSIX IO
In object lifecycle:
- “recall” might mean:
- restore from an archive class for temporary access
- rehydrate into a hotter class permanently
- copy into a new location/work bucket for processing
- materialize into a POSIX cache via a gateway
So you’re no longer optimizing only for latency. You’re optimizing for workflow timing + cost + durability + governance.
5) Security and governance models shift
POSIX security is enforced at the file system layer (UID/GID, ACLs).
Object security typically relies on:
- IAM policies
- bucket/key policies
- object ACLs (depending on platform)
- tagging/attribute-based controls
That changes how you implement “only this team can recall/rehydrate” or “this dataset can’t leave cold tier.”
6) Hybrid gateways reintroduce POSIX—but with new failure modes
Many shops use:
- file gateways over object
- POSIX overlays over S3
- caching layers that “look like NAS”
That’s useful, but it can create a worst-of-both-worlds scenario:
- POSIX apps behave like everything is local
- gateway triggers object restores/GETs behind the scenes
- you get recall storms + request storms + surprise bills
Net effect: HSM becomes less about illusion and more about governance
Classic HSM was often:
“Make the file system pretend the data is nearby.”
Modern object lifecycle is:
“Manage where data lives over time, and make access a controlled workflow.”
Transparency isn’t the default goal anymore—predictability is.
What “winning” looks like in the 2020s
The systems that do best in this transition tend to:
- Expose lifecycle controls cleanly (storage classes, transitions, retention, restore behavior)
- Provide inventory + analytics (so policy is based on reality, not folklore)
- Integrate with workflow engines (events, queues, automation, rate limits)
- Support hybrid access safely (caching/gateways with guardrails, not “surprise restore roulette”)
- Make state visible (tier, restore status, cost implications) so apps and users aren’t flying blind
So where is HSM headed next?
HSM’s future isn’t “a new tier.” It’s a new operating model.
For decades, HSM was mostly about placement: move cold files off expensive disk, bring them back when someone asks. In the 2020s and beyond, that’s table stakes. What’s changing is how decisions are made, how they’re enforced, and how you prove they’re working—especially when your tiers span on-prem file systems, object stores, and public cloud classes.
Here’s where it’s going.
1) Policy-as-code: fewer tribal rituals, more repeatable engineering
The future HSM stack looks less like “a GUI full of rules nobody dares touch” and more like infrastructure code:
- Policies written as declarative rules (often stored in Git)
- Versioned, peer-reviewed, and traceable (“who changed this and why?”)
- Tested against real datasets or synthetic inventories (“what would this migrate if we turn it on?”)
- Rolled out with staged deployments and rollback plans
This matters because HSM policies are effectively production traffic rules for your data. If you treat them like one-off config tweaks, you eventually get:
- accidental mass migrations
- surprise recall storms
- compliance failures
- and that one incident everyone remembers forever
Policy-as-code turns HSM from “admin craft” into operational engineering.
2) Observability becomes non-negotiable (because lifecycle without visibility is just gambling)
Classic HSM often ran on hope and scheduled reports. Modern HSM has to operate on telemetry:
What you need to see (continuously):
- Inventory: counts, sizes, distributions by tier/class
- Heat: access frequency, access recency, burst behavior
- Recall behavior: queue depth, latency percentiles, failure rates
- Mover throughput: staged bytes/sec, concurrency, bottlenecks
- Cost signals: retrieval costs, request costs, egress, early deletion penalties
- Policy outcomes: “how much did this policy actually move and what did it save?”
If you can’t measure it, you can’t tune it. And in cloud/object land, not tuning it doesn’t just waste time—it wastes money in a way that shows up on a monthly bill and an executive’s mood.
The new rule is: tiering decisions must be telemetry-driven, not vibes-driven.
3) Workflow integration: “recall” becomes an orchestrated event, not an accident
In classic HSM, the user touches the file and the system stages it. That works—until it doesn’t.
The future looks like event-driven orchestration:
- queue-based restores/rehydrates
- prioritization (“this job is due at 9am; that one can wait”)
- throttling to avoid system-wide storms
- pre-stage windows tied to job schedulers (HPC) or batch processing
- automated notifications (“restore complete,” “data available,” “retry scheduled”)
Instead of “transparent recall,” the goal shifts toward predictable recall:
- predictable latency
- predictable cost
- predictable workflow behavior
The systems that win will treat “getting data back from cold tier” like a first-class pipeline step—not an unpredictable side effect of someone clicking a folder.
4) Business signals become policy inputs (ILM finally earns its keep)
This is where ILM stops being a slide-deck philosophy and becomes practical.
Tiering decisions increasingly tie to business events, not just access time:
- project closes → transition to cold/archive
- publication/release → replicate + retain immutably
- legal hold → lock / block deletion / change tiering behavior
- retention clock starts → lifecycle becomes deterministic
- funding ends → enforce archival posture and reduce hot storage spend
- sensitivity changes → restrict access paths and re-encrypt/re-tag
That’s the “adult” version of HSM: policies driven by meaning, not just timestamps.
5) A shift in what HSM optimizes for: from “capacity relief” to “governed lifecycle”
Old HSM success looked like:
- “we freed 40% of primary disk”
Modern HSM success looks like:
- “we can prove where data lives, why it’s there, what it costs, how fast we can get it back, and how long we must keep it”
- “we can change policy safely without outages”
- “we can meet retention/immutability requirements without breaking workflows”
- “we can predict and cap retrieval spend”
The goal is less “make disk look bigger” and more govern data over time across multiple storage domains.
Bottom line
ILM is the “why.” HSM is still the “how.”
What’s changing is the implementation: HSM is evolving into policy-as-code + observability + event-driven workflows, and it’s getting expressed through lifecycle engines and object semantics more than file stubs.
And yes—the only truly stable constant is that vendors will keep renaming it, because “HSM” sounds like something you’d find in a beige rack next to a dot-matrix printer.
[story continues]
tags