
TL;DR —
In this paper we propose a new few-shot learning approach that allows us to decouple the complexity of the task space from the complexity of individual tasks.
This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Andrey Zhmoginov, Google Research & {azhmogin,sandler,mxv}@google.com;
(2) Mark Sandler, Google Research & {azhmogin,sandler,mxv}@google.com;
(3) Max Vladymyrov, Google Research & {azhmogin,sandler,mxv}@google.com.
Table of Links
- Abstract and Introduction
- Problem Setup and Related Work
- HyperTransformer
- Experiments
- Conclusion and References
- A Example of a Self-Attention Mechanism For Supervised Learning
- B Model Parameters
- C Additional Supervised Experiments
- D Dependence On Parameters and Ablation Studies
- E Attention Maps of Learned Transformer Models
- F Visualization of The Generated CNN Weights
- G Additional Tables and Figures
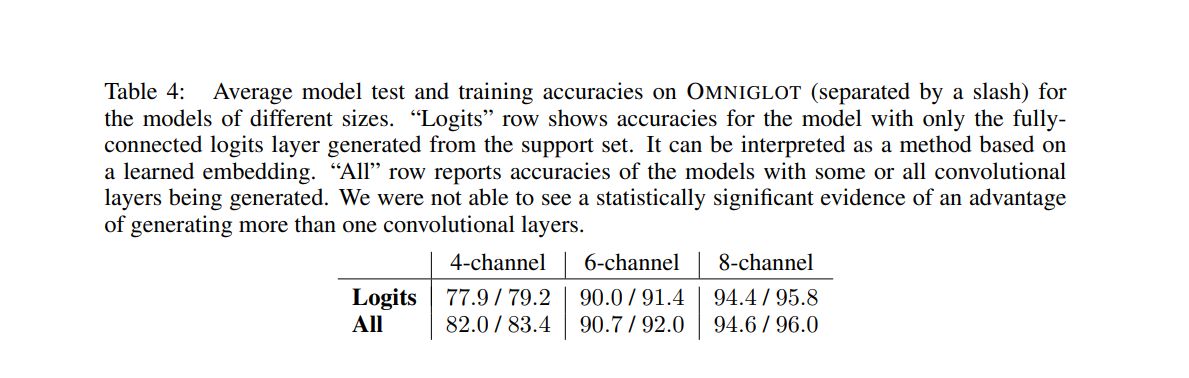
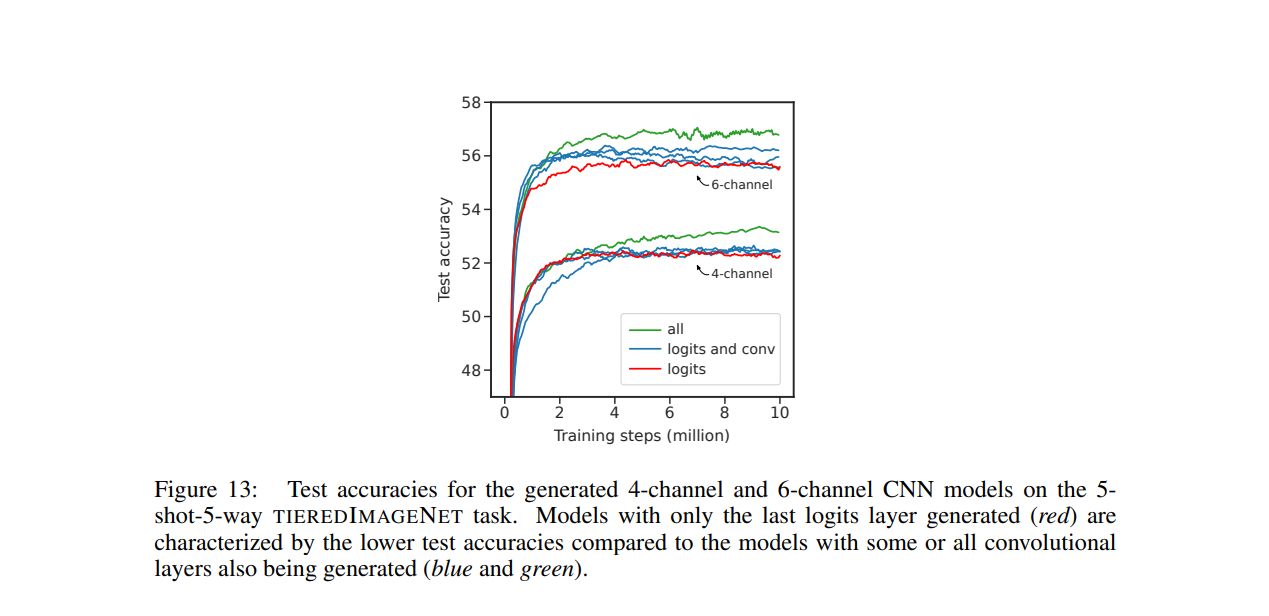
G ADDITIONAL TABLES AND FIGURES


[story continues]
Written by
@escholar
We publish the best academic work (that's too often lost to peer reviews & the TA's desk) to the global tech community
Topics and
tags
tags
hypertransformer|supervised-model-generation|few-shot-learning|convolutional-neural-network|small-target-cnn-architectures|task-independent-embedding|conventional-machine-learning|parametric-model
This story on HackerNoon has a decentralized backup on Sia.
Transaction ID: 9MDGZV-3P0mFeZfTQVbekJm48ZcSlQSelqKJW4jpJ6M