Once I destroyed my production DB with a sleepy UPDATE and had no fresh backups. Lost ~30% of the revenue, a bunch of nerves and way too many hours. That pain pushed me to build and open-source a PostgreSQL backup & monitoring tool that I now use everywhere.
Table of content
- About the open-source PostgreSQL backup project
- The story of how I broke the DB and couldn’t fully recover
- How I started building the project
- Roadmap & future plans
- DB safety rules I now enforce on every project
- Wrap-up
About the open source PostgreSQL backup project
I open sourced my own tool for monitoring and backing up PostgreSQL. I’ve been building and using it for a little over two years. Initially, I’ve developed it for my day job and a couple of pet projects.
Only recently did it hit me that the project actually looks good enough to show publicly, it already helps my friends and could be useful to the community.
Stack: Go, gin, gorm, React, TypeScript, PostgreSQL — everything wrapped in Docker. The very first version was in Java, but I rewrote it to Go over the time.
In essence, it’s a UI wrapper around the standard pg_dump in custom format, with a bunch of extras that make the UX less painful and add integrations with external storage and notification services.
What it can do:
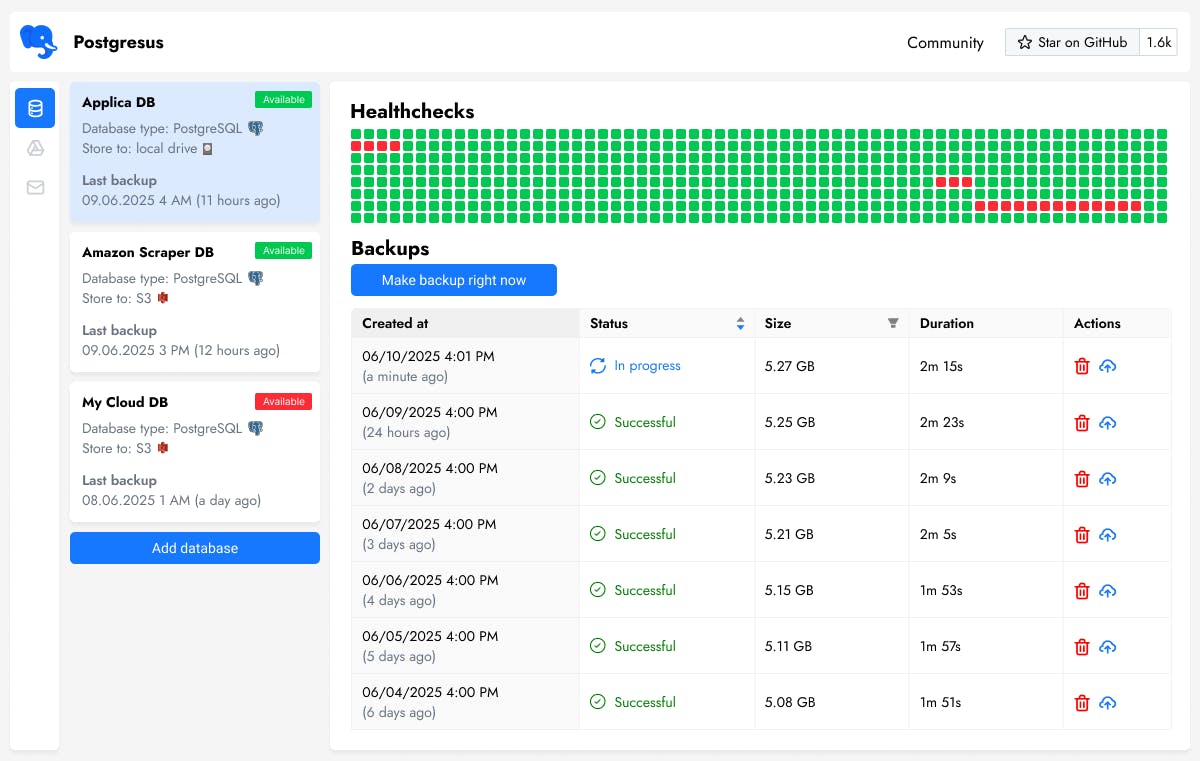
- Schedule backups (e.g., every day at 4 AM or every Sunday at midnight) for PostgreSQL 13–17.
- Store compressed backups locally on the server, in S3 or Google Drive (NS servers and FTP are on the roadmap).
- Send you a message after each backup that everything is fine… or not. Notifications are optional.
- Ping you in Discord, email, Telegram and Slack if the DB stops responding. It only alerts after
nfailed checks (to avoid false positives due to network glitches) and shows an availability graph.
Naturally, the project is free, open source (MIT), self-hosted and comes with a humane web UI.
Project site:
GitHub:
P.S. If the project looks useful and you have a GitHub account, I’d really appreciate a ⭐️. The first stars are really the hardest to get.
The story of how I broke the DB and couldn’t fully recover
Back in 2023 I had a pet project that was a wrapper of ChatGPT (3.5). Basically, it was just reselling API access with a pretty UI and shortcuts. The project grew, then started to go down and I finally sold it. The DB was being backed up once a day with a console tool like PgBackRest to another server.
At the moment when the project was bringing in about $1,500 passively and hitting its revenue peak, something bad happened: I broke the data in the DB.
It was a Friday night. I was tired, I was instantly switching from coding to messages answering, totally unfocused. A customer asked me to change the email for his account.
Through SSH and psql I hopped into production VPS and typed something like:
UPDATE users SET email = 'customer@email.com' WHERE email ILIKE '%%';
Then I got distracted to copy the correct email from the chat and… hit Enter on “autopilot”. Next thing I saw was something like AFFECTED ROWS: 10 000.
That was the only time in many, many years I literally felt a cold sweat on my back.
Disclaimers: of course, I knew I should have done a SELECT first, maybe set a SAVEPOINT, etc. But like in every horror story, the basic safety rules were ignored, and it all snowballed into disaster.
All user emails were overwritten. And here’s the key detail: payment systems have strict rules — if a user can’t access a paid service, that’s a huge violation. Naturally, nobody could log in anymore and complaints started rolling in.
I ran to the backups — and the cold sweat got even worse. The most recent backup was about a month old 😐. No way to restore from that. From that time new payments came in, subscriptions were canceled (meaning I couldn’t just restore everyone — some people had already left), etc.
Somehow, over the rest of the night and morning, I managed to reconstruct about 65% of the DB via scripts using user IDs. For the rest, I had to cancel subscriptions and refund people. It was painful, unpleasant and expensive.
The lesson was learned.
How I started building the project
Decision time: I’m going to build myself a backup tool that will ping me every day that everything is fine! And restore in a couple of clicks! And blackjack and microservices! And I’ll add an API health-check endpoint too!
I made the first version of Postgresus in about a month in Java. Started using it. Let a few friends try it. Kept polishing it based on my needs and their feedback.
Turned out: it’s useful. A few times those backups saved me (and not just me). The name “Postgresus” only appeared two months ago, before the repo was simply called “pg-web-backup”.
Right now, Postgresus solves these problems for me:
- It’s the main backup tool if the project is small or lives on a VPS instead of a cloud DB service.
- It’s the fallback backup toolif the project is large and lives in a DBaaS with its own cloud backups.
It backs up “just in case” (if the cloud dies, gets blocked, the DB is accidentally deleted along with cloud backups due to non-payment, etc.). It’s always better to have a duplicate backup than to end up in that unlucky 0.01% when even the cloud disappears and there’s no Plan B.
Roadmap & future plans I’m planning to push the project in these directions:
-
Add more PostgreSQL-specific load monitoring (pg_stat_activity, pg_stat_system, pg_locks) with a friendly UI. Think of it as an alternative to postgres_exporter + Grafana, but bundled out of the box with backups.
-
Observe and alert on slowdown of key queries.
In my work project, there are tables and specific functions that are too early to optimize (if the hypothesis fails, we might drop them), but they could grow and slow down.
For example, if INSERT INTO users (...) VALUES (...) starts taking more than 100 ms while the flow of new users is growing - we'll get a notification and go optimize.
-
Collect query stats by CPU time and execution frequency to see where resources are actually going and what’s worth improving.
-
Add more channels for notifications and more storage providers.
DB safety rules I now enforce on every project
Let me remind you of two pieces of folk wisdom:
System admins fall into two categories: those who don’t make backups yet and those who already do.
Don’t just make backups — regularly test that you can actually restore from them.
Since trashing my project’s DB, I’ve adopted these rules without exception:
- Before any
UPDATE, always run aSELECTand make sure you're touching exactly 1-2 rows. - If the change is big — set a
SAVEPOINTmanually. - Conduct “fire alarms” with restoration at least once every 3 months: restore from a cloud copy and from a local one. So when it matters, you don’t discover there’s no data, backups don’t work,or restores take forever.`
In the last two years there have been a few cases where we needed to restore from backups — every time it worked, both in the cloud and via Postgresus. No issues, because the process had already been ironed out during tests. Basic safety rules do work.
Wrap-up
I hope this project will be useful to a broad set of developers, DBAs and DevOps folks. I plan to keep evolving it to make it even more helpful in real-world scenarios. I’m happy to hear any suggestions and feedback for improvement.