Authors:
(1) Goran Muric, InferLink Corporation, Los Angeles, (California [email protected]);
(2) Ben Delay, InferLink Corporation, Los Angeles, California ([email protected]);
(3) Steven Minton, InferLink Corporation, Los Angeles, California ([email protected]).
Table of Links
2 Related Work and 2.1 Prompting techniques
3.3 Verbalizing the answers and 3.4 Training a classifier
4 Data and 4.1 Clinical trials
4.2 Catalonia Independence Corpus and 4.3 Climate Detection Corpus
4.4 Medical health advice data and 4.5 The European Court of Human Rights (ECtHR) Data
7.1 Implications for Model Interpretability
7.2 Limitations and Future Work
A Questions used in ICE-T method
6 Results
The results of the classification experiments are summarized in Table 1. We can see that across all datasets, the ICE-T method consistently surpasses the zero-shot approach in performance for a given language models. Specifically, using the GPT-3.5 model, the average µF1 for the zero-shot approach is 0.683, but it increases to 0.845 with the ICET method. A similar trend is observed with the larger GPT-4 model, where the average F1 score improves from 0.7 using the zero-shot approach to 0.892 with the ICE-T technique. This improvement is not constant across the datasets as we can see a significant variations in performance and in improvements across different tasks.
The upper portion of Table 1 showcases the findings from the clinical trial dataset, as detailed in Section 4. The dataset’s contents remain consistent across all sub-tasks within this clinical trial dataset, though each sub-task involves a distinct classification criterion based on 12 different criteria. In some sub-tasks, substantial improvements were observed over the zero-shot method. For instance, in the task CREATININE (involving serum creatinine levels exceeding the upper normal limit), the zero-shot method achieved µF1 of 0.349. In contrast, the ICE-T technique utilizing the same large language model significantly improved this score to 0.721. Similarly, for the task ENGLISH (determining if a patient speaks English) using the larger GPT4 model, the greatest increase noted exceeded 0.733 points, with the zero-shot approach at a µF1 of 0.233 and the ICE-T technique improving it to 0.966. Analysis of tasks outside the clinical trial dataset revealed varied results, dependent on the specific domain. The task assessing “Catalonia independence” presented a notable challenge in the zero-shot setup for both models, barely achieving a µF1 above 0.5, with no significant improvements noted with the ICE-T technique.
The task related to the European Court of Human Rights (ECtHR) already exhibited high baseline scores in the zero-shot setting, achieving 0.853 with GPT-3.5 and 0.861 with GPT-4. The application of the ICE-T technique yielded minimal improvement, with both models achieving a µF1 of 0.873. A similar scenario was observed with the Health advice dataset, where enhancements were negligible.
However, the UNFAIR-ToS task demonstrated significant improvement using the ICE-T approach, particularly with the GPT-3.5 model. Here, the µF1 score saw a dramatic increase from 0.335 to 0.887.
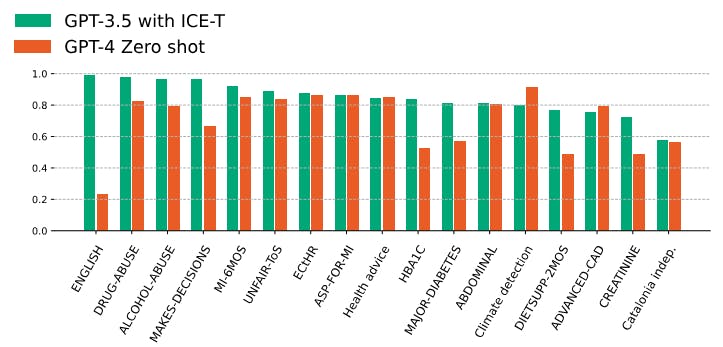
Furthermore, our analysis reveals that the ICE-T technique, when applied to a smaller model, can surpass or match the performance of a larger model that uses the zero-shot approach. In our experiments, we assessed the µF1 of classification tasks executed by GPT-4 in a zero-shot setting against those performed by GPT-3.5 using the ICE-T technique across various datasets. In nearly all cases, except for two, the ICE-T-enhanced GPT-3.5 either outperformed or equaled the larger GPT-4 model on identical tasks. These findings are depicted in Figure 2.
We observed a minor variation in performance across different task groups. By categorizing clinical trial tasks into one group and other tasks into another, we observed a comparable average performance improvement when comparing the zero-shot to the ICE-T approach, as detailed in Table 4 in Appendix B. This consistency underscores the versatility of the ICE-T method across various domains and tasks.
To explore how the number of features impacts the micro F1 score (µF1), we conducted an additional sensitivity analysis. The outcomes of this
analysis are depicted in Figure 3. This figure illustrates the change of the µF1 as we incrementally introduce more features (obtained by secondary questions). A solid orange line shows the average µF1 across all datasets, while the surrounding shaded area indicates one standard deviation from the mean, based on 100 iterations. As anticipated, there is a consistent increase in the micro F1 score with the addition of more secondary questions. On average, adding three secondary questions increases the µF1 score from 0.76 to 0.80, with further additions raising it to 0.82.
It is important to highlight that this figure averages results from 17 different datasets, using only the Random Forest classifier. Detailed results for each individual task are available in Figure 4 in Appendix B. The use of a single classifier in this analysis was a deliberate choice to isolate the impact of increasing the number of features, thereby minimizing the influence of classifier selection on the results. However, this choice may also limit the generalizability of the findings, as it differs from previous analyses where the optimal classifier was selected for each task.
This paper is