Table of Links
-
Related work
-
Our method
4. Our method
4.1. Estimation of Contribution in the Ideal Scenario

Moreover, we can employ the classic first-order Taylor expansion to approximate ϕ(g, θ), which has also been widely used in previous work (Pruthi et al., 2020; He et al., 2023). Note that, it is possible to use more sophisticated methods here, e.g., Koh and Liang (2017).
Lemma 4.1. The loss of a network f on a dataset U can be approximated by a first-order approximation:
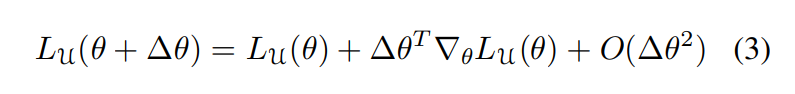
So the contribution of g to f can be approximated by:
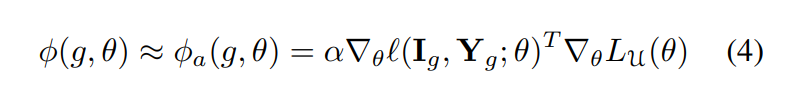

Authors:
(1) Muzhi Zhu, with equal contribution from Zhejiang University, China;
(2) Chengxiang Fan, with equal contribution from Zhejiang University, China;
(3) Hao Chen, Zhejiang University, China (haochen.cad@zju.edu.cn);
(4) Yang Liu, Zhejiang University, China;
(5) Weian Mao, Zhejiang University, China and The University of Adelaide, Australia;
(6) Xiaogang Xu, Zhejiang University, China;
(7) Chunhua Shen, Zhejiang University, China (chunhuashen@zju.edu.cn).
This paper is
[story continues]
tags