
Table of Links
Supplementary Material
-
Image matting
-
Video matting
5. Experiments
We developed our model using PyTorch [20] and the Sparse convolution library Spconv [10]. Our codebase is built upon the publicly available implementations of MGM [56] and
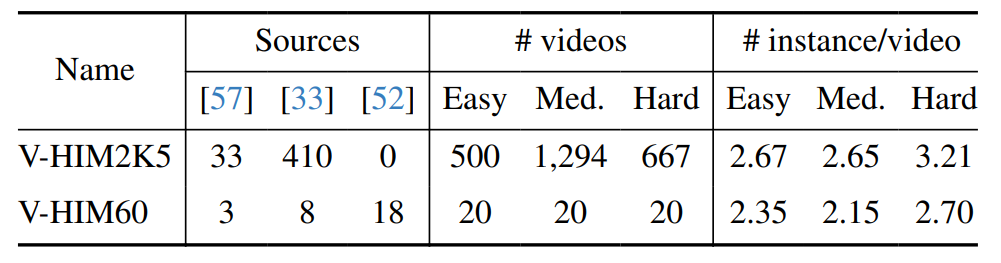
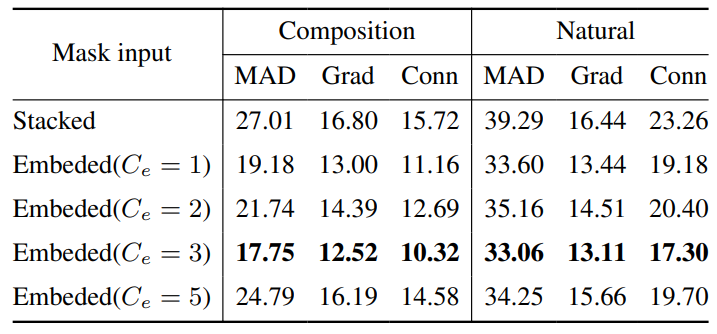
OTVM [45]. In the first Sec. 5.1, we discuss the results when pre-training on the image matting dataset. The performance on the video dataset is shown in the Sec. 5.2. All training settings are reported in the supplementary material.
Authors:
(1) Chuong Huynh, University of Maryland, College Park (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh, Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava, University of Maryland, College Park (abhinav@cs.umd.edu);
(4) Joon-Young Lee, Adobe Research (jolee@adobe.com).
This paper is
[story continues]
tags