Authors:
(1) Jaehyeon Moon, Yonsei University and Articron;
(2) Dohyung Kim, Yonsei University;
(3) Junyong Cheon, Yonsei University;
(4) Bumsub Ham, a Corresponding Author from Yonsei University.
Table of Links
-
Method
-
Experiments
Supplementary Material
A. More implementation details
B. Compatibility with existing hardwares
C. Latency on practical devices
Abstract
Post-training quantization (PTQ) is an efficient model compression technique that quantizes a pretrained full-precision model using only a small calibration set of unlabeled samples without retraining. PTQ methods for convolutional neural networks (CNNs) provide quantization results comparable to full-precision counterparts. Directly applying them to vision transformers (ViTs), however, incurs severe performance degradation, mainly due to the differences in architectures between CNNs and ViTs. In particular, the distribution of activations for each channel vary drastically according to input instances, making PTQ methods for CNNs inappropriate for ViTs. To address this, we introduce instance-aware group quantization for ViTs (IGQViT). To this end, we propose to split the channels of activation maps into multiple groups dynamically for each input instance, such that activations within each group share similar statistical properties. We also extend our scheme to quantize softmax attentions across tokens. In addition, the number of groups for each layer is adjusted to minimize the discrepancies between predictions from quantized and full-precision models, under a bit-operation (BOP) constraint. We show extensive experimental results on image classification, object detection, and instance segmentation, with various transformer architectures, demonstrating the effectiveness of our approach.
1. Introduction
Transformers [35] can capture long-range dependencies across sequential inputs, which is of central importance in natural language processing, aggregating contextual information and providing discriminative feature representations. Recently, vision transformers (ViTs) [10] has demonstrated the effectiveness of transformers for images, providing state-of-the-art results on various visual recognition tasks, including image classification [25, 34], object detection [25, 42], and semantic segmentation [25, 33, 39]. However, a series of fully-connected (FC) and self-attention layers in ViTs requires a substantial amount of memory and computational cost, making it challenging to deploy them on devices with limited resources (e.g., drones and mobile phones). The growing demand for ViTs to operate on the resource-constrained devices has led to increased interest in developing network quantization techniques for ViTs.
Network quantization generally reduces bit-widths of weights and activations of a model for an efficient inference process, which can be categorized into two groups: Quantization-aware training (QAT) and post-training quantization (PTQ). QAT methods [11, 43, 44] train fullprecision models, while simulating the quantization process by inserting discretizers into networks to quantize, such that the discrepancy between the full-precision and quantized models is minimized in terms of accuracy. This suggests that QAT methods require entire training samples, and they are computationally expensive, making them impractical for the prompt deployment of neural networks. PTQ methods [19, 27, 37], on the other hand, calibrate quantization parameters (e.g., quantization intervals, zero-points) from pretrained full-precision models, enabling faster quantization of networks compared to QAT methods with only a limited number of training samples (usually less than 1k).
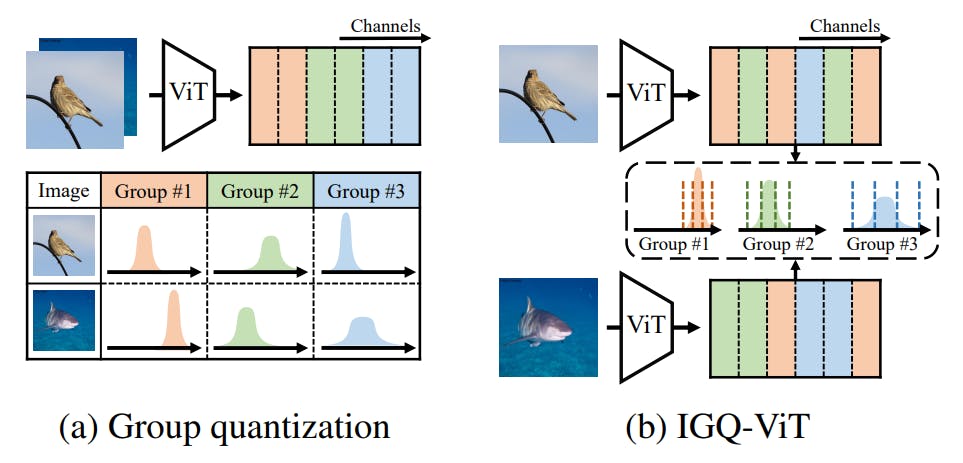
Several PTQ methods for transformers [9, 26, 40] apply layer-wise quantization techniques, where a single quantizer is applied to all activation values for efficiency. These methods, however, are not directly applicable for quantizing models using extremely low bit-widths (e.g., 4-bit), due to the significant scale variation on the activations for each channel. Exploiting channel-wise quantizers (i.e., applying different quantizers for each channel) could be a potential solution, but at the expense of computational overheads, due to floating-point summations of channel-wise outputs for matrix multiplication. Group quantization techniques [7, 32] could be an alternative to address this problem, where they divide consecutive channels uniformly into multiple groups, and apply a single quantizer for each group (Fig. 1a). However, we have observed that the channel-wise distributions of activation values vary largely among different samples, making conventional approaches inappropriate for ViTs.
In this paper, we present instance-aware group quantization for ViTs (IGQ-ViT), that effectively and efficiently addresses the variations of channel-wise distributions across different input instances (Fig. 1b). Specifically, we split the channels of activation maps into multiple groups dynamically, such that the activation values within each group share similar statistical properties, and then quantize the activations within the group using identical quantization parameters. We also propose to use the instance-aware grouping technique to softmax attentions, since the distributions of attention values vary significantly according to tokens. In addition, we present a simple yet effective method to optimize the number of groups for individual layers, under a bit-operation (BOP) constraint. IGQ-ViT can be applied to various components in ViTs, including input activations of FC layers and softmax attentions, unlike previous methods [21, 23, 26, 40] that are limited to specific parts of transformer architectures. We demonstrate the effectiveness and efficiency of IGQ-ViT for various transformers, including ViT [10] and its variants [25, 34], and show that IGQ-ViT achieves state-of-the-art results on standard benchmarks. We summarize the main contributions of our work as follows:
• We introduce a novel PTQ method for ViTs, dubbed IGQViT, that splits channels of activation maps into a number of groups dynamically according to input instances. We also propose to use the instance-aware grouping technique to split softmax attentions across tokens.
• We present a group size allocation technique searching for an optimal number of groups for each layer given a BOP constraint.
• We set a new state of the art on image classification [8], object detection, and instance segmentation [22], with various ViT architectures [10, 25, 34].
This paper is