
TL;DR —
Text embedding models have emerged as powerful tools for transforming sentences into fixedsized feature vectors that encapsulate semantic information.
This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Michael Günther, michael.guenther;
(2) Jackmin Ong, jackmin.ong;
(3) Isabelle Mohr, isabelle.mohr;
(4) Alaeddine Abdessalem, alaeddine.abdessalem;
(5) Tanguy Abel, tanguy.abel;
(6) Mohammad Kalim Akram, kalim.akram;
(7) Susana Guzman, susana.guzman;
(8) Georgios Mastrapas, georgios.mastrapas;
(9) Saba Sturua, saba.sturua;
(10) Bo Wang, bo.wang;
(11) Maximilian Werk, maximilian.werk;
(12) Nan Wang, nan.wang;
(13) Han Xiao, han.xiao}@jina.ai.
Table of Links
- Abstract & Introduction
- Related Work
- Training Process Overview
- Backbone Pre-training
- Fine-Tuning for Embeddings
- Evaluation
- Conclusion & References
- Appendix
A Appendix
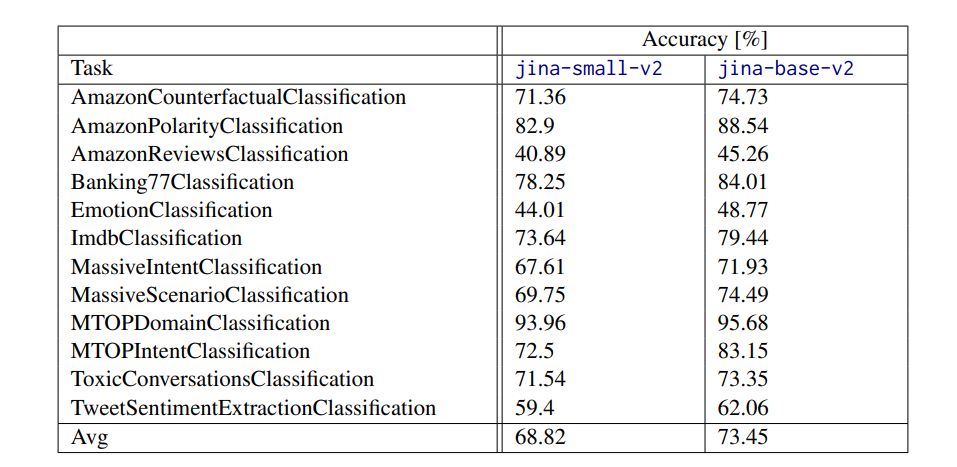
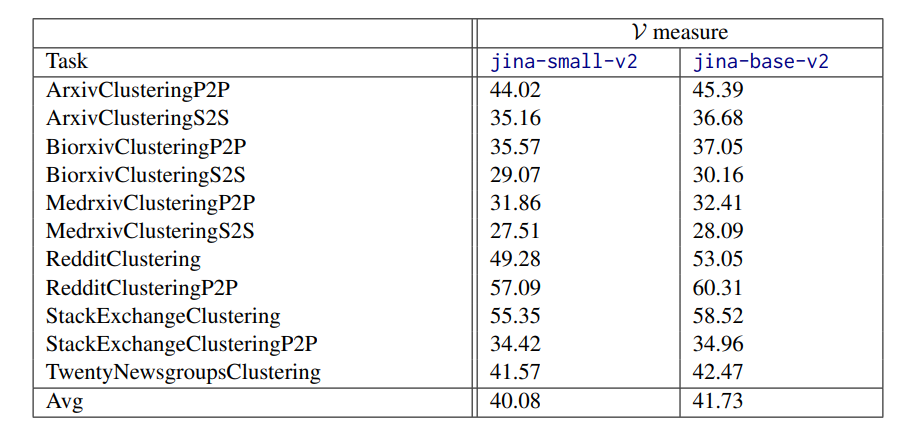

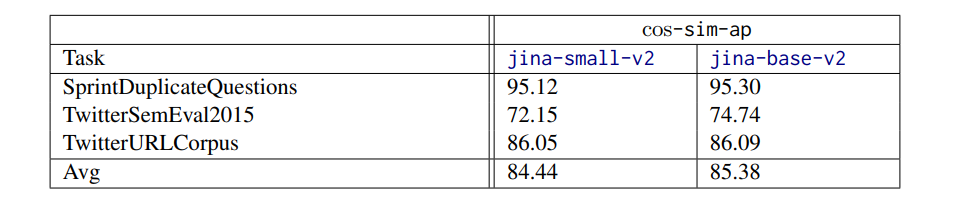
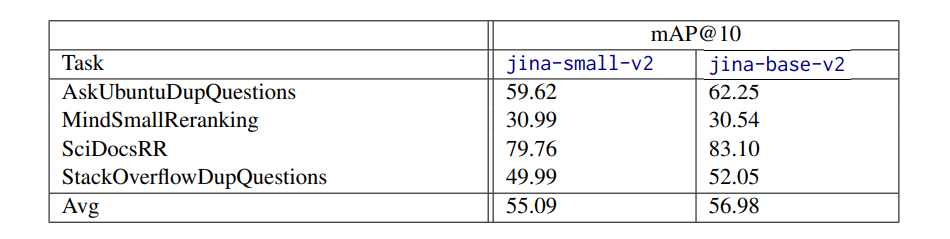
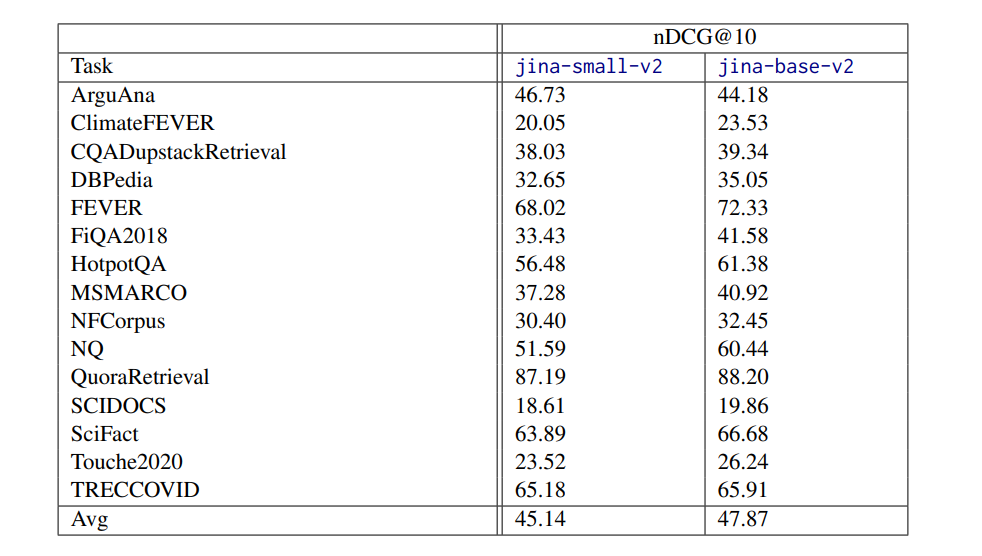
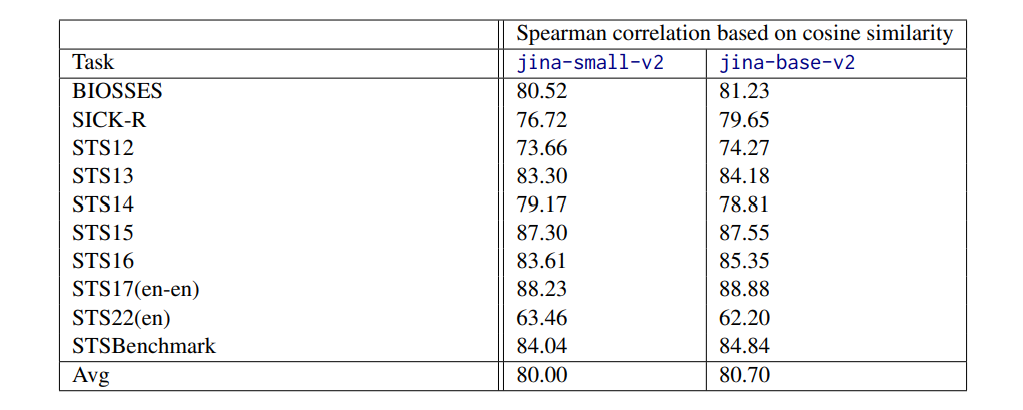
[story continues]
Written by
@escholar
We publish the best academic work (that's too often lost to peer reviews & the TA's desk) to the global tech community
Topics and
tags
tags
text-embedding-models|jina-embeddings-v2|narrativeqa|text-embedding-ada-00|text-embedding-token-limits|information-retrieval|machine-learning-research|text-re-ranking
This story on HackerNoon has a decentralized backup on Sia.
Transaction ID: a5-RyerX1Z51i33axPtq2DBh0W64LAA0Tg0gtqlQsik