
Introduction
I’m a software development engineer at Cisco. Our team has been using Apache DolphinScheduler to build our own big data scheduling platform for nearly three years. Starting from version 2.0.3, we’ve grown alongside the community; what I’m sharing today is based on secondary development on version 3.1.1, adding features not included in the community release.
Today I will share how we used Apache DolphinScheduler to build a big data platform, submit and deploy our jobs to AWS, the challenges we encountered, and our solutions.
Architecture Design and Adjustments
Initially, all of our services were deployed on Kubernetes (K8s), including API, Alert, as well as Zookeeper (ZK), Master, and Worker components.
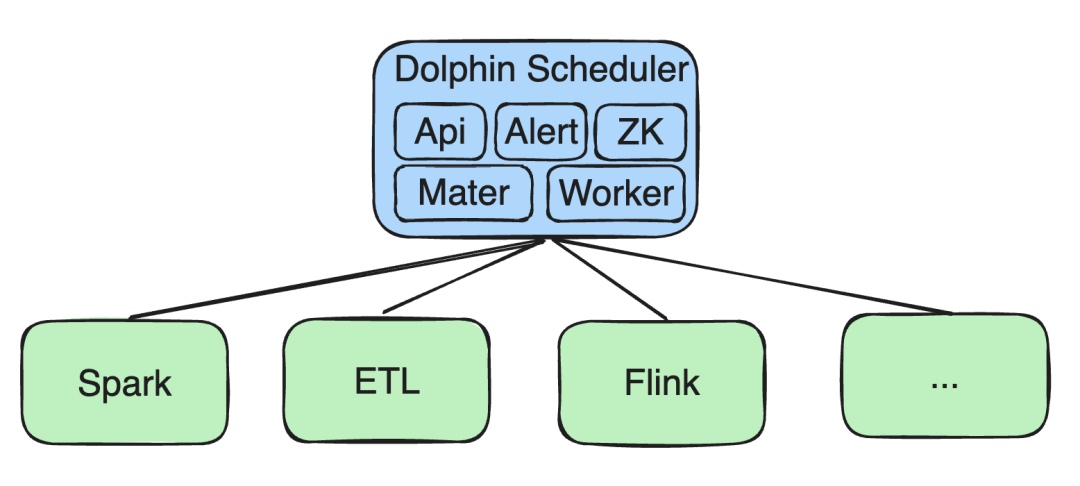
Big Data Processing Jobs
We performed secondary development for Spark, ETL, and Flink tasks:
- ETL tasks: Our team developed a simple drag‑and‑drop tool, allowing users to quickly generate ETL jobs.
- Spark support: Early versions only supported Spark on Yarn. We extended it to support Spark on K8s. The latest community release now supports Spark on K8s.
- Flink secondary development: Similarly, we added support for Flink-on-K8s streaming tasks, as well as SQL and Python tasks on K8s.
Supporting Jobs on AWS
With business expansion and data policy requirements, we faced the challenge of running data tasks in multiple regions. This required building an architecture that supported multi‑cluster deployment. Here are the details of our solution and implementation.
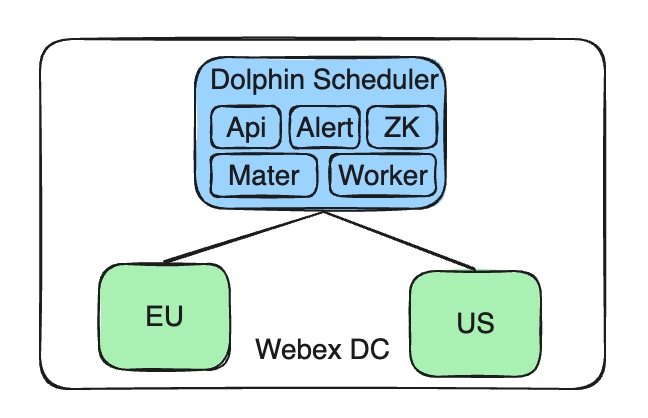
Our current architecture includes a centralized control terminal—that is, a single Apache DolphinScheduler service that manages multiple clusters. These clusters are deployed across different geographies, such as the EU and the US, to comply with local data policy and isolation needs.
Architecture Adjustments
To meet this requirement, we made the following modifications:
- Maintain centralized management of the Apache DolphinScheduler service: Our DolphinScheduler service remains deployed in Cisco’s self‑built Webex data center (DC), ensuring management centralization and consistency.
- Support AWS EKS clusters: We extended the architecture to support multiple AWS EKS clusters. This allows tasks to run on EKS clusters for new business needs without affecting operations or data isolation in other Webex DC clusters.
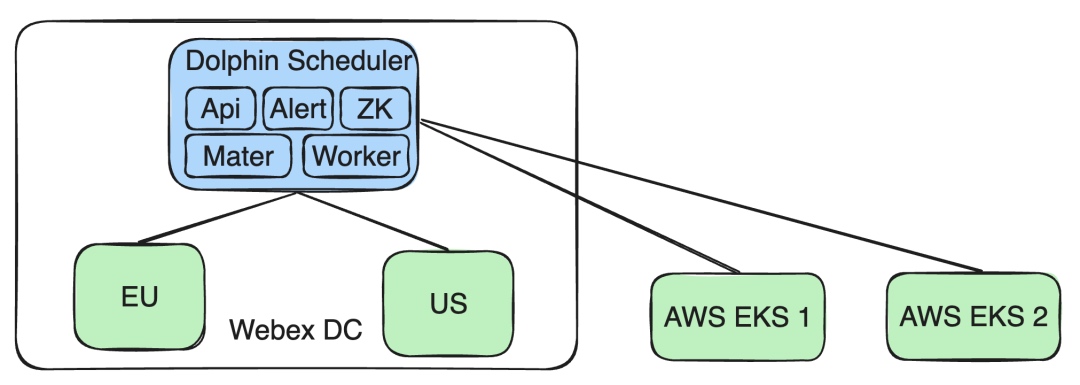
This design enables a flexible response to diverse business needs and technical challenges while ensuring data isolation and policy compliance.
Next, I’ll discuss the technical implementation and resource dependencies when Apache DolphinScheduler runs jobs in the Cisco Webex DC.
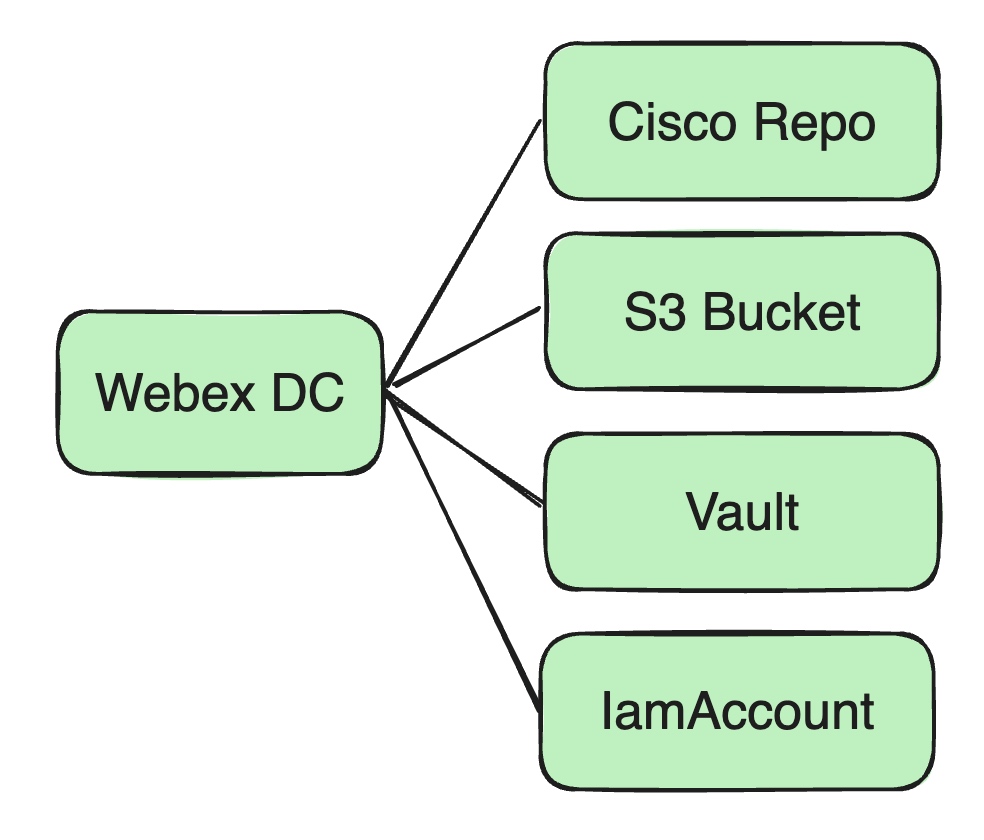
Resource Dependencies and Storage
Since all our jobs run on Kubernetes (K8s), the following are critical to us:
Docker Images
- Storage location: Previously, all Docker images were stored in Cisco’s private Docker repository.
- Image management: These images provide the necessary runtime environments and dependencies for our various services and jobs.
Resource Files and Dependencies
- JARs and configuration files: We use Amazon S3 buckets as a central store for user JARs and other dependency configuration files.
- Secure resource management: Sensitive information—including database passwords, Kafka credentials, and user-related keys—are all stored in Cisco’s Vault service.
Secure Access and Permission Management
For accessing S3 buckets, we needed to configure and manage AWS credentials:
IAM Account Configuration
- Credential management: We use IAM accounts to control access to AWS resources, including Access Keys and Secret Keys.
- K8s integration: These credentials are stored in Kubernetes Secrets and referenced by the API service for secure S3 access.
- Permission control and resource isolation: Through IAM, we enforce fine-grained permission control, ensuring data security and business compliance.
AWS IAM Access Key Expiration and Mitigation
During AWS resource access via IAM accounts, we encountered access key expiration issues. Here’s how we addressed it:
Access Key Expiry Challenge
- Key lifecycle: AWS IAM keys typically expire every 90 days for security reasons.
- Task impact: Once a key expires, any job that depends on that key to access AWS resources fails. Prompt key renewal is necessary to ensure business continuity.
In response, we configured automatic periodic task restarts and monitoring alerts. If an AWS account key shows issues before expiration, our team is notified for timely handling.
Supporting AWS EKS
As business expanded to AWS EKS, we made several adjustments to the architecture and security.
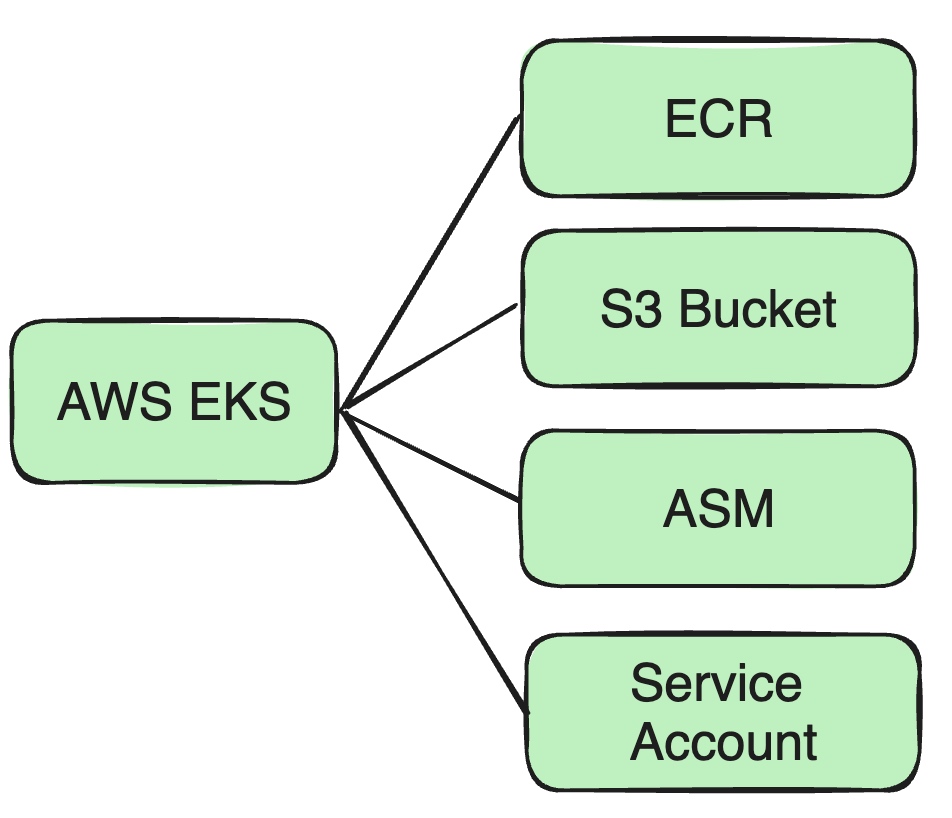
For example, Docker images previously stored in Cisco’s private Docker repo now need to be pushed to AWS ECR.
Support for Multiple S3 Buckets
Due to the distributed AWS clusters and the need for business data isolation, we needed to support multiple S3 buckets:
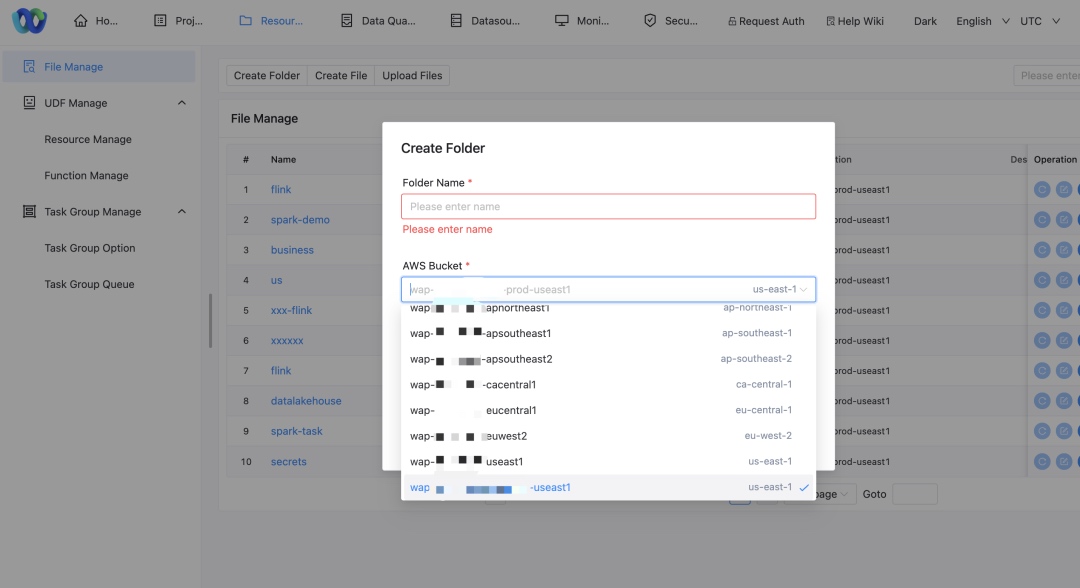
- Mapping clusters to buckets: Each cluster accesses its corresponding S3 bucket to ensure data locality and compliance.
- Policy updates: We adapted storage access logic to support reading from and writing to multiple S3 buckets. Business units access only their designated bucket.
Secrets Management Tool Migration
To enhance security, we migrated from Cisco’s internal Vault to AWS Secrets Manager (ASM):
- ASM usage: Provides a more integrated solution for managing AWS resource secrets.
We adopted an IAM Role + Service Account model to improve Pod security:
- Create IAM Role and Policy: Assign minimal necessary permissions.
- Bind to Kubernetes Service Account: Link Kubernetes Service Account to IAM Role.
- Pod permission integration: Pods assume the IAM Role via the Service Account to access AWS resources securely.
These adjustments not only improved scalability and flexibility but also strengthened our overall security architecture and resolved automatic key expiration issues.
Optimizing Resource Management and Storage Flow
To simplify deployment, we plan to push Docker images directly to ECR rather than via intermediate transfers:
- Direct push: Modify build processes so Docker images are pushed directly to ECR post‑build, reducing latency and failure points.
Implementation Changes
- Code‑level updates: We made changes in DolphinScheduler to support multiple S3 clients and manage their caching.
- UI updates for resource management: Users can now select different AWS bucket names in the interface.
- Resource access support: Modified DolphinScheduler service can now access multiple S3 buckets, enabling flexible data management across AWS clusters.
AWS Resource Management and Access Isolation
Integrating AWS Secrets Manager (ASM)
We extended DolphinScheduler to support AWS Secrets Manager, allowing users to pick secrets based on cluster type:
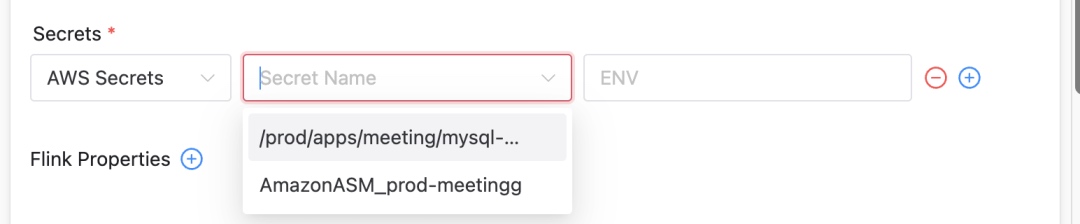
ASM Integration Features
- UI enhancements: In the DolphinScheduler UI, we added secret type display and selection options.
- Automatic key handling: At runtime, the selected secret’s file path is mapped to Pod environment variables for secure usage.
Dynamic Resource Configuration & Init Containers
To flexibly manage and initialize AWS resources, we deployed an Init Container:
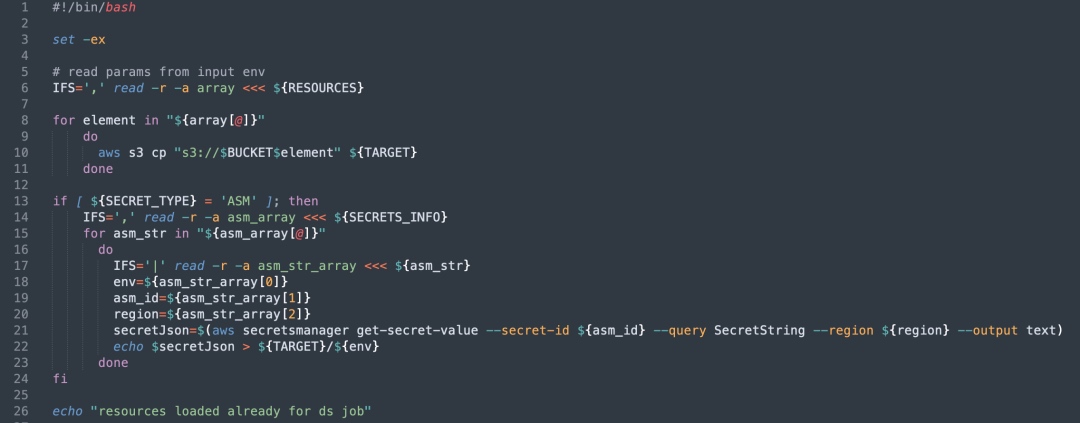
- Resource fetch: Before Pod execution, the Init Container retrieves configured S3 resources and places them into a specified directory.
- Key and config handling: It pulls ASM secrets, stores them as files, and maps them via environment variables for Pod use.
Using Terraform for Resource Provisioning
We automated AWS resource setup using Terraform, simplifying resource allocation and permission configuration:
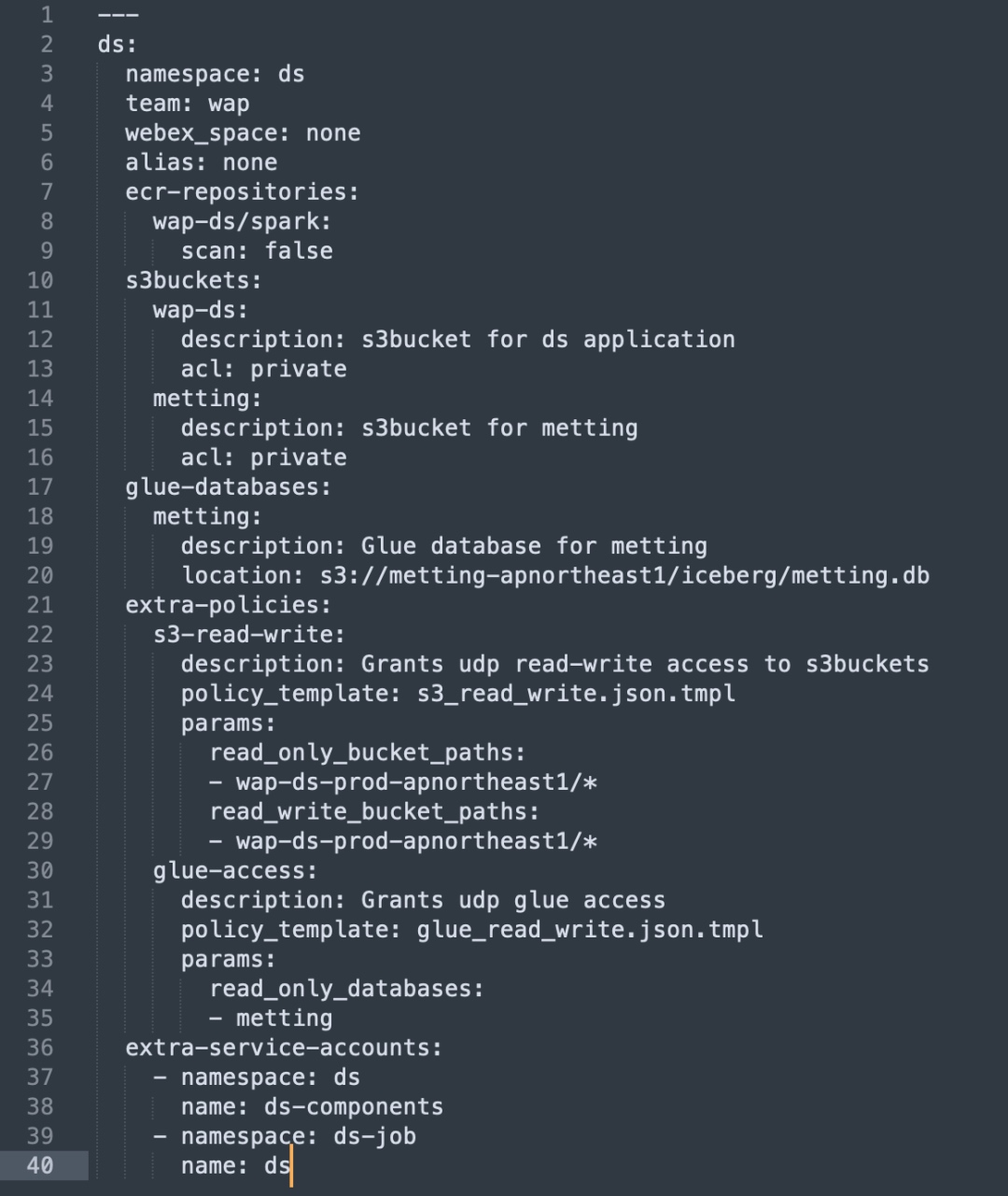
- Automated infrastructure setup: Terraform provisions S3 buckets, ECR repos, etc.
- IAM policy and role automation: Generate IAM roles and policies per business unit to ensure least privilege access.
Access Isolation and Security
We enforced fine-grained permission and resource isolation across business units:
Implementation Details
- Service Account creation and binding: Each business unit gets its own Service Account linked to an IAM Role.
- Namespace isolation: Jobs are restricted to run within their assigned namespace and IAM-backed resources.
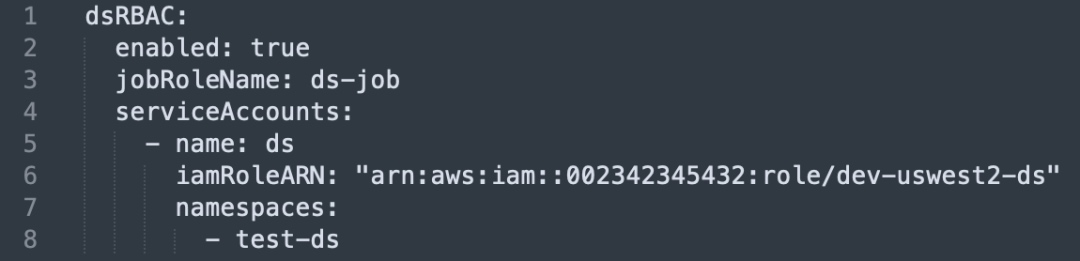
Cluster Support and Permission Control Enhancements
Extension of Cluster Types
We added a cluster type field to support different K8s cluster styles—not just Webex DC and AWS EKS, but also high‑security clusters:
Cluster Type Management
- Cluster type field: Enables easy management and extension of cluster support.
- Code‑level customization: Specific adaptations ensure jobs meet configuration and security needs when running on distinct clusters.
Enhanced Permission Control System (Auth)
We developed an Auth system for fine-grained permission control across projects, resources, and namespaces:
Permission Management Features
- Project and resource access: Project-level permissions grant access to all resources underneath.
- Namespace access control: Teams can only run jobs within their assigned namespace, preventing inter-team access.
For example, Team A can only run jobs in A namespace and cannot run jobs in B namespace.
AWS Resource Access and Permission Requests
Through the Auth system and associated tools, we manage AWS resource access and permission requests securely:
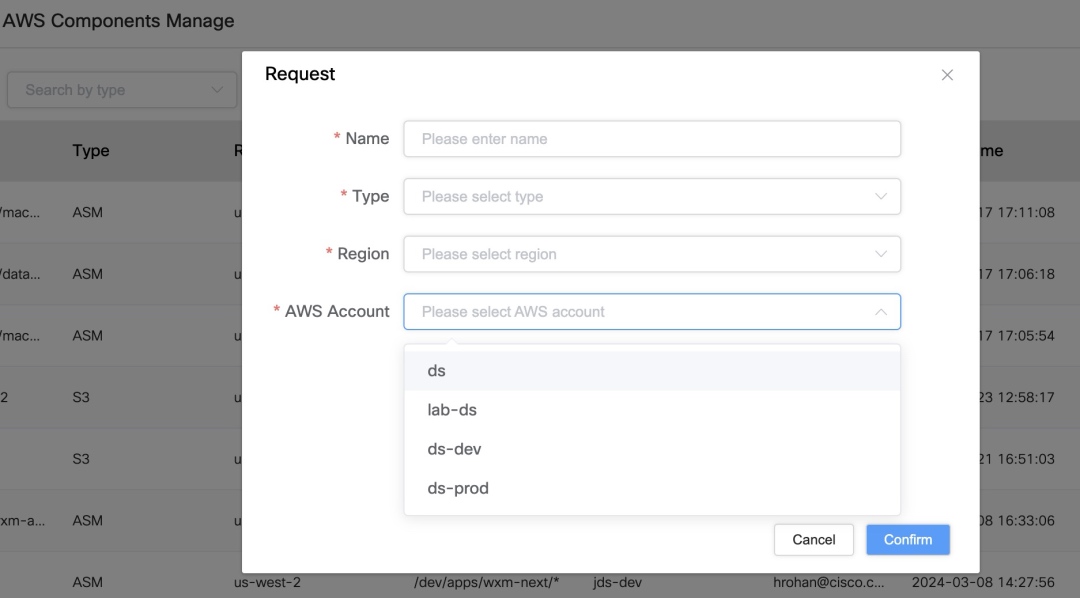
- Multi‑account support: Manage different AWS accounts and bind various resources (S3, ECR, ASM) to them.
- Resource mapping & permission requests: Users can request access or map resources through the system, making job-run-time resource selection seamless.
Service Account Management & Permission Binding
To improve service account governance and access binding, we implemented:
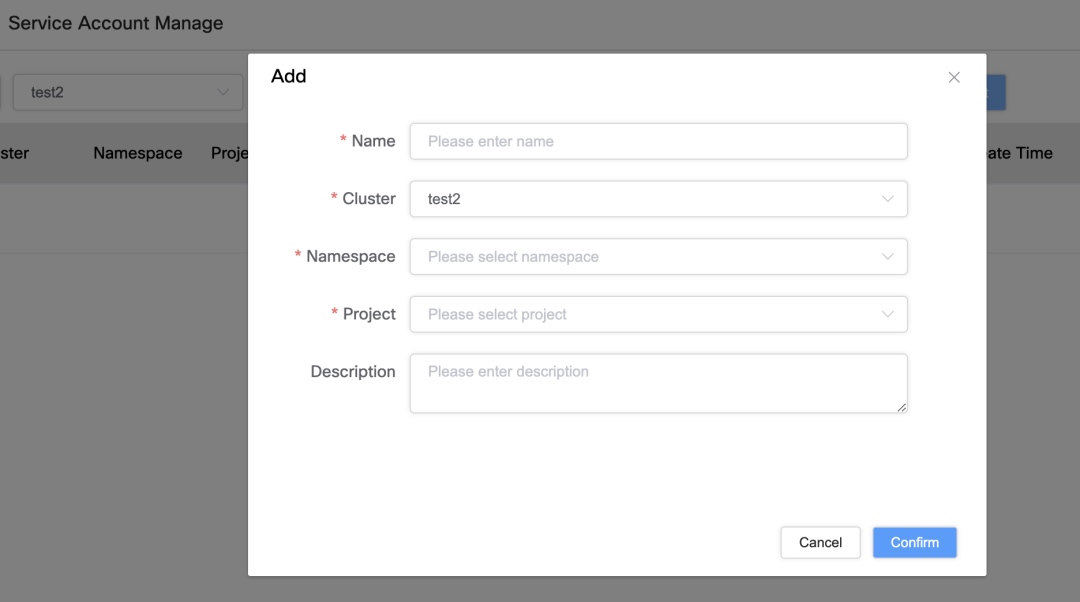
Service Account Binding Features
- Unique identification: Service Accounts are uniquely tied to cluster, namespace, and project.
- UI-based binding: Users can bind Service Accounts to AWS resources (S3, ASM, ECR) via the UI for precise access control.
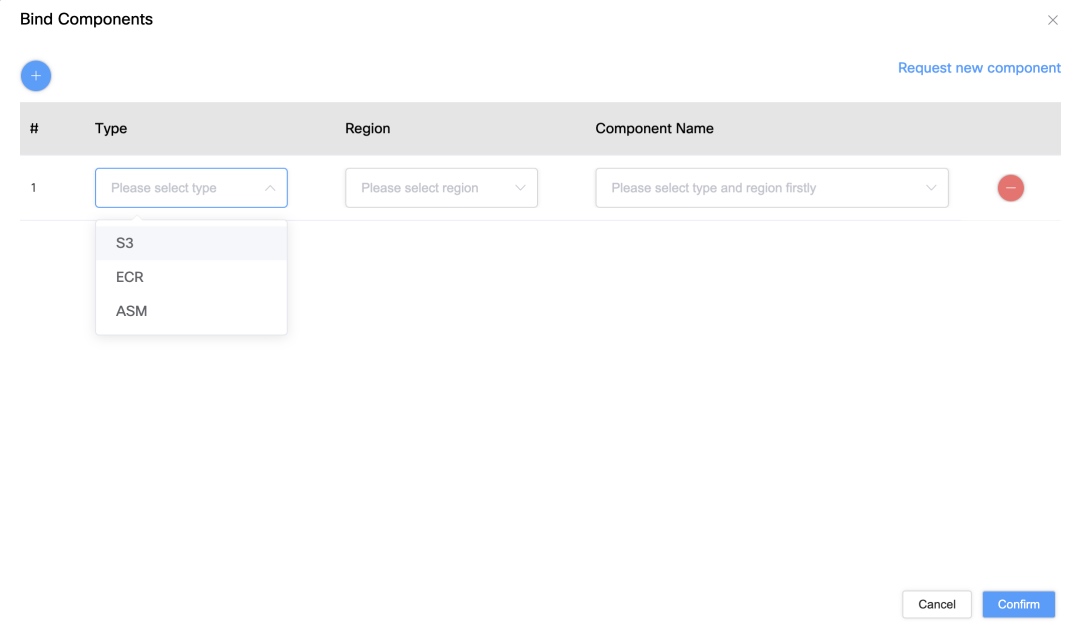
Simplified Operations and Resource Synchronization
Although the above sounds extensive, user operations are actually quite straightforward and one-time. To further improve the user experience of running DolphinScheduler in AWS:
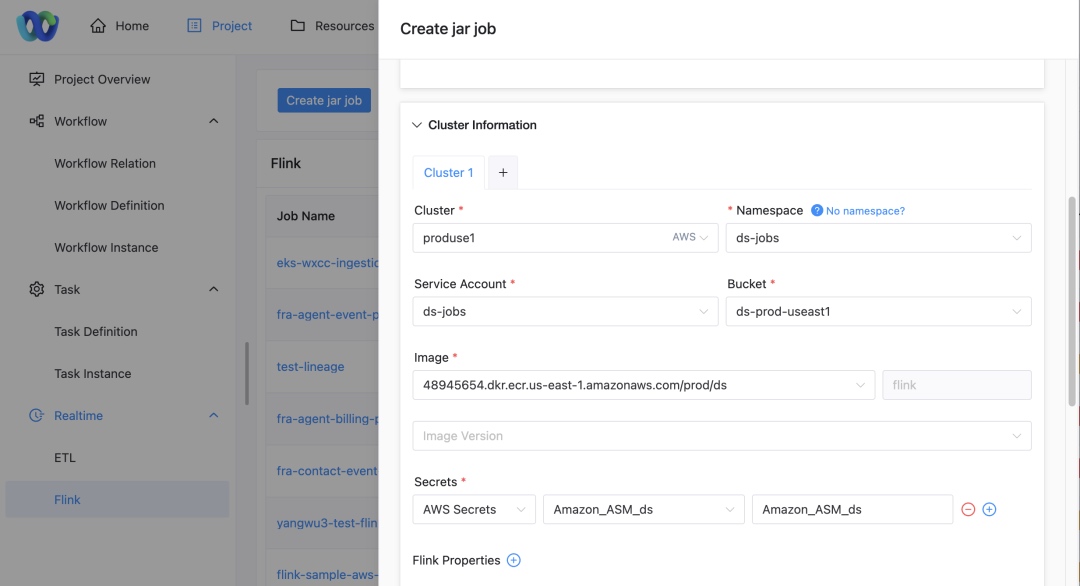
Here’s a summary:
Simplified User UI
In DolphinScheduler users can easily configure jobs’ target cluster and namespace:
Choosing Cluster and Namespace
- Cluster selection: Users can pick the cluster where the job will run.
- Namespace specification: Based on the selected cluster, users choose the appropriate namespace.
Service Account & Resource Selection
- Service Account display: Based on project, cluster, and namespace, the UI auto-selects the corresponding Service Account.
- Resource access configuration: Users choose associated S3 Buckets, ECR addresses, and ASM secrets via dropdown menus.
Future Outlook
Looking at our current design, there are still areas for optimization to improve user submission flow and operations:
- Image push optimization: Skip Cisco intermediate packaging and push images directly to ECR, especially for EKS-specific images.
- One-click sync feature: Enable users to automatically sync a resource package uploaded to one S3 bucket to multiple buckets, reducing redundant uploads.
- Automatic mapping into the Auth system: After Terraform creates AWS resources, the system auto-maps them into the permission management system, removing manual resource entry.
- Permission control enhancement: Through automated resource and permissions control, user operations will become simpler and less error‑prone.
With these enhancements, we aim to help users deploy and manage their jobs more effectively on DolphinScheduler—whether in Webex DC or on EKS—while improving resource management efficiency and security.
[story continues]
tags