
Image credit: Tunde Berumo via Unsplash
If you’ve lived in Lagos, Nigeria, long enough, you have seen and experienced firsthand how rent prices have been on a steady rise, up until the point where it’s frankly become senseless and disgusting now. Yes, I’m particularly pained about this because I think this behaviour of increasing rent willy-nilly by property owners in Nigeria has been aided and abetted by people in places of power in the state who have chosen to fold their hands and look on. The lack of regulatory oversight has allowed landlords and property owners to run wild for so long, it’s now become ridiculous. You can tell that I pay rent in Lagos, right? *fights back a tear*
This ‘scourge’ keeps getting worse, with no hope in sight for a solution soon. This is especially the case for young people looking to get their first spaces and get the rude shock that they can’t live in their preferred neighborhoods because of the rent price. So I thought to myself, wouldn’t it be nice to have a tool anyone could use to estimate and predict the price of renting a house in any area within Lagos state?
This tool answers a simple question—“What’s a reasonable annual rent for my ideal apartment scenario?” But behind it sits a messy reality made up of fragmented scraping sources, macro indicators (part of the numerous features that affect how real estate might be priced in the state), and a model that runs both locally and on Hugging Face. The model churns out predicted estimates for the amount it’d take to rent a property anywhere in both divisions of the state — mainland and island. This article attempts to capture what it took to go from raw CSVs to a reproducible user interface.
Data Pipeline & Feature Prep
At the start of this project, I knew I needed to get my dataset first, curated or not. I needed to have a database (sort of) of properties for rent in Lagos state. My first instinct was to Google search “Lagos housing dataset”. That didn’t help much because I didn’t find any dataset that satisfied what I thought I’d need. I did find one project on Kaggle, though, but it was a very small dataset of rent prices from five years ago. So I did the next best idea that came to mind: building my own dataset.
I generated a Python script (scripts/build_combined_properties.py) that helped me scrape listings in Lagos from three property websites and then stitched them together. This script normalizes columns, tags each row with its source, and then outputs data/combined_properties.csv. The dataset had some noise in the form of a handful of rental properties from states like Oyo and Abuja, which I cleaned up. This left me with a dataset of properties in Lagos structured firmly with columns like location, number of bedrooms and bathrooms, toilets, area_sqm, type of property (commercial or residential), price, etc.
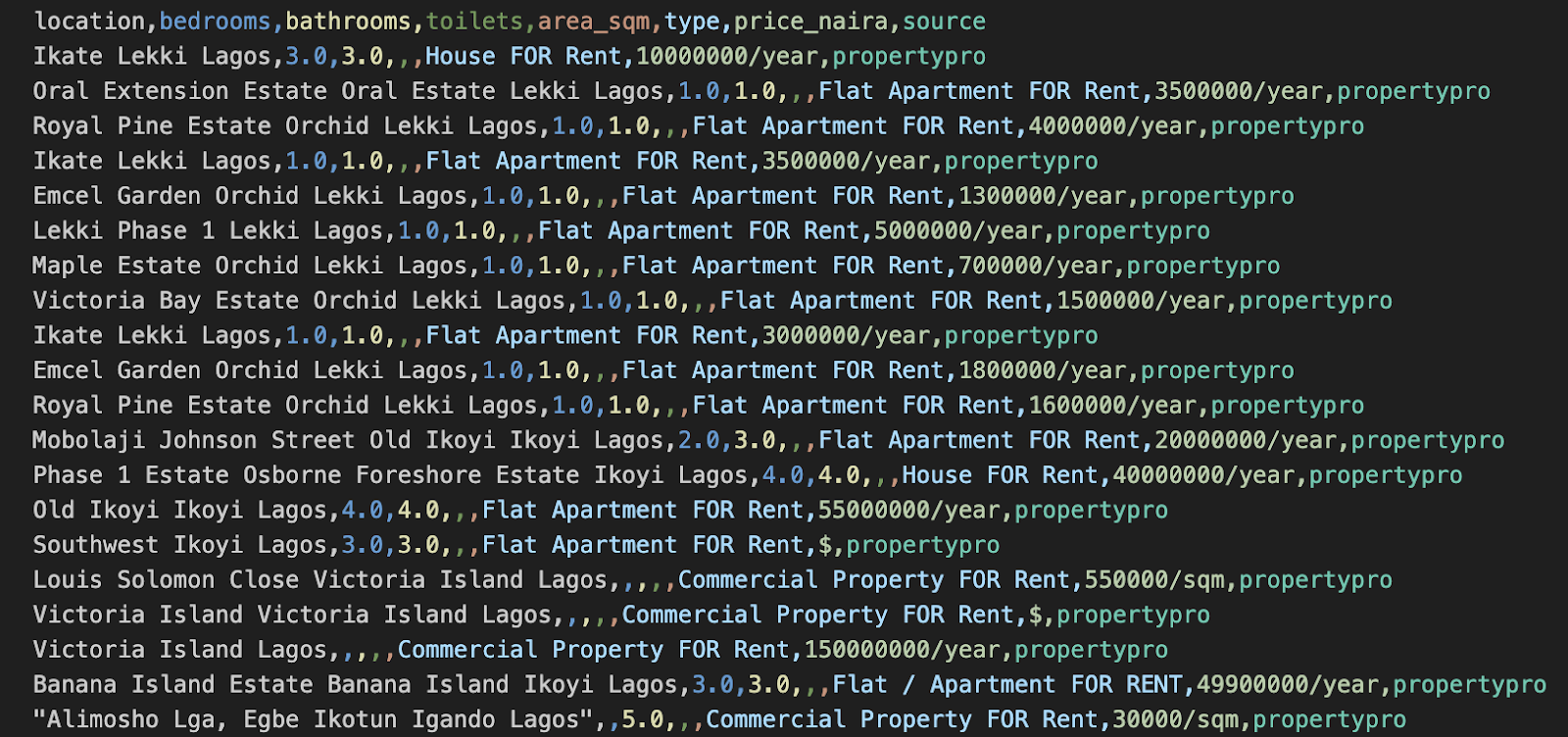
Feature engineering for the project was one of the things I worked on. Here, I augmented the basic property info in the dataset (beds, baths, toilets, area) with location heuristics (mainland/island) and macroeconomic features like inflation, FX, GDP of the state, etc). Essentially, the types of things that guide real estate anywhere, especially in a major economic and cultural hub like Lagos. These columns live in FEATURE_COLUMNS inside app/predict.py, keeping the UI and model perfectly aligned.
The features of the different locations told an interesting story. When I ranked feature importance after training the model, the top signals were simple everyday things Lagosians care about: number of bedrooms, and the economic disparity between locations like Igbogbo Ikorodu, and Old Ikoyi. I liked this because the model was able to learn the same thing people living in Lagos already know. A three-bedroom flat in Ikorodu is nothing like a three-bedroom in Ikoyi. The spread in behavior between those two ends of the location spectrum is so strong that the one-hot encoded location columns became some of the most powerful predictors in the model.
For this model, location isn’t just a minor factor; it is a critical driver of the observed outcomes.

Data Challenges in Lagos Real Estate
Lagos real estate data is messy by nature. There’s no standard format that listings follow across platforms. If you look keenly, you’ll notice some agents even upload the same property multiple times with different prices. Others leave out basic fields like size (sqm) or number of toilets or bathrooms. Even naming the locations isn’t consistent. For instance, you'll see “Ikoyi,” “Old Ikoyi,” “Ikoyi Lagos,” and “Ikoyi, Lagos” all pointing to the same place.
All these inconsistencies made cleaning up the dataset take more effort than expected. I had to normalize locations, remove duplicates, and then drop rows that had suspicious pricing. I also handled a spillover effect from scraping that saw listings from places like Abuja or Oyo sneak into the Lagos-focused dataset. The dataset finally looked like something a model could trust by the time the cleanup was done, but it showed how fragmented the real estate market is offline.
Modeling & Validation
The dataset was heavily right-skewed, which meant a classic long-tail distribution. I’ll explain why. When it comes to the price, most Lagos listings are clustered in the “low-to-mid million naira” range, but a small number of luxury properties have huge values, and this causes a spike in the distribution. This made the histogram look normal-ish with a heavy right tail. That is why I used a scikit-learn regression pipeline with a Box-Cox transform to handle this particular distribution—Box-Cox tames the skew and makes residuals closer to Gaussian. The artifacts from this are in the trained_model_pipeline.joblib and lambda_boxcox.joblib files.

The histogram here plots Lagos annual rents (millions of naira ₦ and capped at the 99th percentile) against listing counts from 1626 scraped properties (1,182 after clean up). After plotting, it reveals a heavily-skewed market: the vast majority of listings cluster below ₦25M, mid-tier units range between ₦40—180M, but thin out quickly. Ultra-luxury rents appear above ₦250M in only a few isolated bars. This is clear evidence that as the rent price increases/doubles, the available properties reduce drastically.
After training the model, I ran a thorough residual analysis that confirmed things were on track. The model achieved an overall RMSE (Root Mean Square Error) of approximately ₦5.7M when predictions were converted back into actual naira amounts. This is a commendable error margin given the extreme price differences across the city’s diverse neighborhoods. An inspection of the residuals revealed some heteroscedasticity, especially for higher-priced properties, where prediction errors tended to widen. What this suggests is that while the model performs well across most price ranges, its precision may decrease when it is being used to forecast prices for the most luxurious or uniquely valued properties. Upon further granular evaluation, I saw that while the model performed strongly on properties on the Island at an R² of 0.7261, its predictive power for 'Mainland' properties still exhibited areas needing further refinement, even though they improved. I think this is because localized factors might need deeper exploration to achieve consistent accuracy across both the Island and the Mainland segments.


Why the RMSE Looks Large in Naira Terms
The price of rent in Lagos spans a wide spectrum. A one-bedroom on the mainland can be ₦400K, a duplex in Lekki can be ₦8M, and then you have penthouses in Ikoyi listed at ₦20M and above. The RMSE in naira terms naturally looks high because of this huge spread. I know an error of ₦5M sounds wild, but that’s until you realize it’s being pulled upward by a handful of ultra-premium listings in choice locations. On the other hand, the R² score tells a clearer story—the final model explains most of the price variation in the dataset. For a market as chaotic as this, the performance is surprisingly stable.
Deployment Journey
Instead of committing huge binaries with GitHub Large File Storage (LFS) or relying on manual uploads, the model auto-downloads as app/predict.py checks for .joblib artifacts in the models/ folder, and if these artifacts are missing, downloads them from the Hugging Face repo. This auto-download runs through the help of an artifact upload script that mirrors local joblibs to the Space via huggingface_hub. This way, there’s no need to manually drag and drop the files each time the model is trained/retrained.
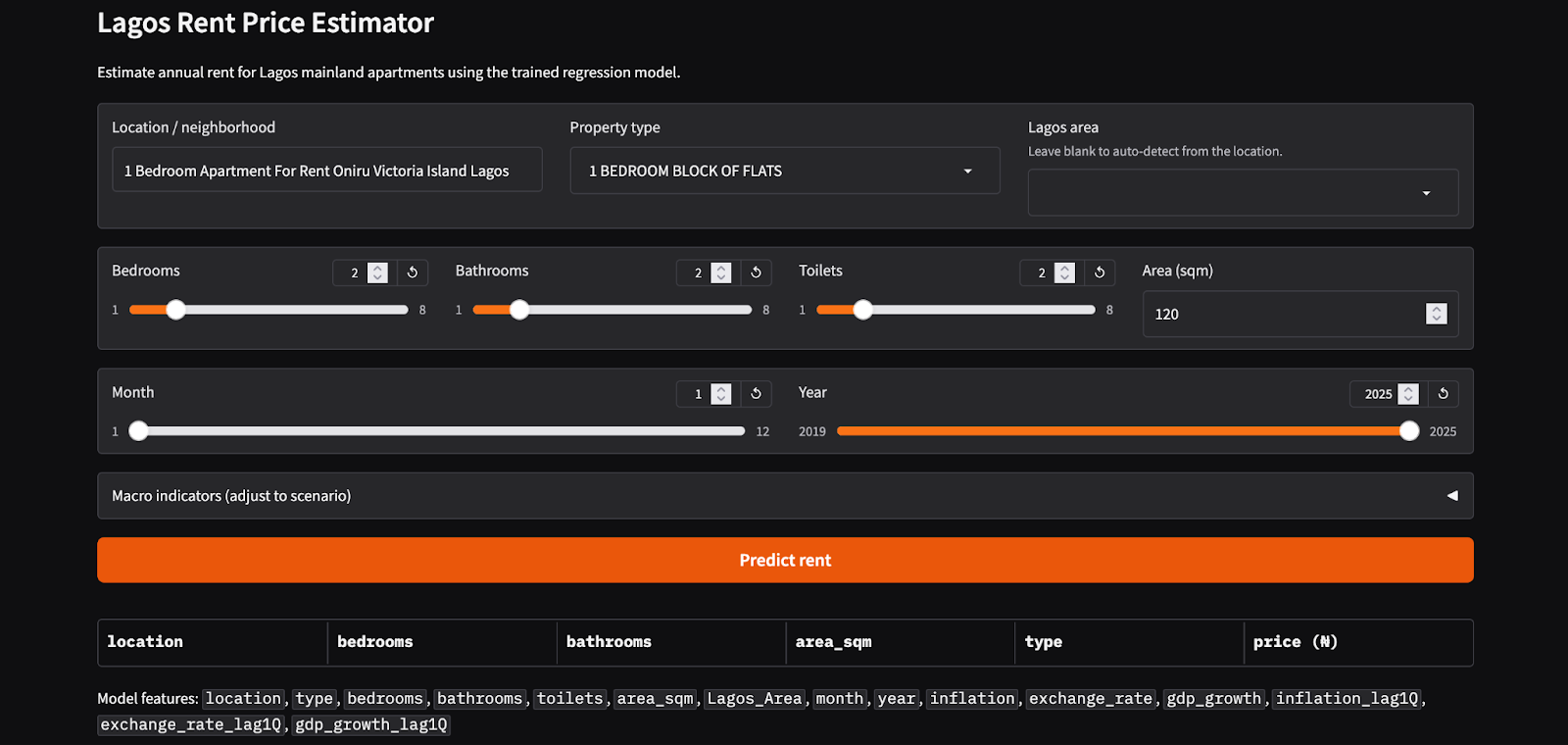
This project started as a solely CLI-based one, but as I worked on it, I imagined it would be better if the tool had a UI users could interact with. This is why I wrapped the entire model inside a Gradio interface so anyone can try it out without having to touch code or commands. The Gradio UItakes basic inputs like bedrooms, neighborhood, property type, etc, and returns a predicted annual rent the user can use to guide their decision on where to live in Lagos. The UI is hosted on Hugging Face, so the whole pipeline runs end-to-end in a lightweight environment. With this, the project went full circle—from scraping listings to serving live predictions through a publicly accessible interface.
Limitations
While the model works well, it isn’t perfect. Lagos rent pricing changes fast, and for a lot of reasons. New estates are popping up, inflation hits (Nigeria is currently going through a tough economic situation), jumps in FX, and agents are setting prices as they see fit without any regulatory body setting regulations everyone could follow. Even though I added macroeconomic features, the model still relies heavily on historical data.
Takeaways
In this project, I learnt how useful it is to keep artifacts versioned outside Git. Once the Hugging Face datasets or Spaces work as they should, just script the upload/download path. When I started on this project, I thought it was going to be a relatively straightforward one, but it hasn’t been like that. I’ve, however, learnt from working on it. Some of the things I learnt include:
Automating every “glue” task. Tasks like combining listings in the dataset file, running smoke tests (saves me from merging broken models multiple times), and uploading models. The easier it is to rerun the model, the more likely the pipeline and deployment are kept in sync.
Conclusion
This project started off from frustration at the frankly ridiculous nature of Lagos rents, but it turned into a chance to understand the Lagos rental scene through its data. I went for a tool that made rent choices less confusing by giving users a rough baseline, instead of random guesses. As I worked on the project, I learnt a lot about how messy the real estate market is and the level of difficulty involved with predicting prices. I’ve also been surprised at the level of satisfaction involved in taking a model from a noisy CSV to a working product.
This tool is by no means a magic answer to the rent problems in Lagos, but it’s a step toward transparency. And for anyone (myself included) who’s been blindsided by the sudden rent hikes, even a small step matters.
Model’s Hugging Face UI:
Project’s repository:
[story continues]
tags