Authors:
(1) Lichao Wang, FNii, CUHKSZ (wanglichao1999@outlook.com);
(2) Zhihao Yuan, FNii and SSE, CUHKSZ (zhihaoyuan@link.cuhk.edu.cn);
(3) Jinke Ren, FNii and SSE, CUHKSZ (jinkeren@cuhk.edu.cn);
(4) Shuguang Cui, SSE and FNii, CUHKSZ (shuguangcui@cuhk.edu.cn);
(5) Zhen Li, a Corresponding Author from SSE and FNii, CUHKSZ (lizhen@cuhk.edu.cn).
Table of Links
-
Method
-
Experiments
-
Performance Analysis
Supplementary Material
- Details of KITTI360Pose Dataset
- More Experiments on the Instance Query Extractor
- Text-Cell Embedding Space Analysis
- More Visualization Results
- Point Cloud Robustness Analysis
Anonymous Authors
- Details of KITTI360Pose Dataset
- More Experiments on the Instance Query Extractor
- Text-Cell Embedding Space Analysis
- More Visualization Results
- Point Cloud Robustness Analysis
ABSTRACT
Text-to-point-cloud cross-modal localization is an emerging vision-language task critical for future robot-human collaboration. It seeks to localize a position from a city-scale point cloud scene based on a few natural language instructions. In this paper, we address two key limitations of existing approaches: 1) their reliance on ground-truth instances as input; and 2) their neglect of the relative positions among potential instances. Our proposed model follows a two-stage pipeline, including a coarse stage for text-cell retrieval and a fine stage for position estimation. In both stages, we introduce an instance query extractor, in which the cells are encoded by a 3D sparse convolution U-Net to generate the multi-scale point cloud features, and a set of queries iteratively attend to these features to represent instances. In the coarse stage, a row-column relative position-aware self-attention (RowColRPA) module is designed to capture the spatial relations among the instance queries. In the fine stage, a multi-modal relative position-aware cross-attention (RPCA) module is developed to fuse the text and point cloud features along with spatial relations for improving fine position estimation. Experiment results on the KITTI360Pose dataset demonstrate that our model achieves competitive performance with the state-of-the-art models without taking ground-truth instances as input.
1 INTRODUCTION
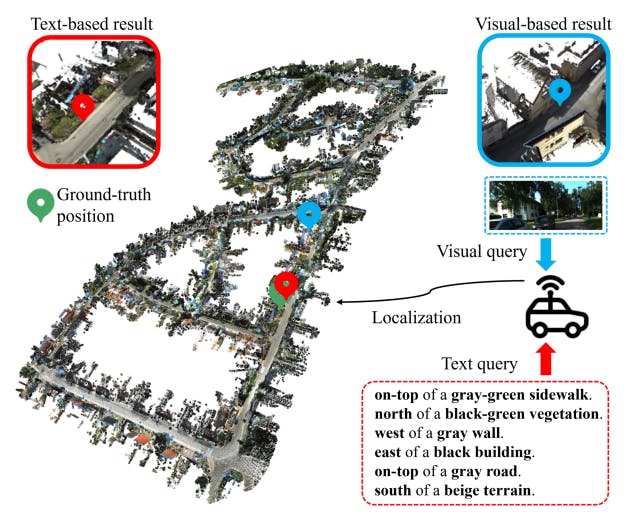
Text-to-point-cloud localization is crucial for autonomous agents. To effectively navigate and complete tasks, future autonomous systems like self-driving vehicles and delivery drones will require collaboration and coordination with humans, necessitating the ability to plan routes and actions based on human input. Traditionally, Mobile agents employ visual localization techniques [2, 52] to determine positions within a map, matching captured images/point clouds against databases of images/point cloud maps [2, 16, 34, 43]. However, visual input is not the most efficient way for humans to interact with autonomous agents [19]. On the other hand, utilizing natural language description enhances the efficiency of communicating pick-up or delivery points to autonomous agents, as demonstrated in Fig. 1. Moreover, the text-to-point-cloud approach offers greater robustness compared to GPS systems [46]. GPS systems struggle in areas concealed by tall buildings or dense foliage.
In contrast, point cloud is a geometrically stable data, providing reliable localization capabilities despite environmental changes.
To accurately interpret the language descriptions and semantically understand the city-scale point clouds, a pioneer work, Text2Pos [21], first divides a city-wide point cloud into cells and accomplishes the task using a coarse-to-fine approach. However, this method describes a cell only based on its instances, ignoring the instance relations and hint relations. To address this drawback, a relation enhanced transformer (RET) network [39] is proposed. RET captures hint relations and instance relations, and then uses cross-attention to fuse instance features into hint features for position estimation. However, RET only incorporates instance relations in the coarse stage, and the design of the relation-enhanced attention may lose crucial relative position information. More recently, Text2Loc [42] employes a pre-trained T5 language model [32] with a hierarchical transformer to capture contextual feature across hints, and proposes a matching-free regression model to mitigate noisy matching in fine stage. Additionally, it utilizes contrastive learning to balance positive and negative text-cell pairs. However, all current approaches rely on ground-truth instances as input, which are costly to obtain in new scenarios. While an instance segmentation model can be adopted as a prior step to provide instances, this pipeline suffers from error propagation and increased inference time, severely degrading its effectiveness. Moreover, current works do not fully leverage the relative position information of potential instances, which is crucial given that directions between the position and surrounding instances frequently appear in textual descriptions.
To address the aforementioned problems, we propose an instance query extractor that takes raw point cloud and a set of queries as input and outputs the refined quires with instance semantic information. To acquire the spatial relations, a mask module is introduced to generate the instance masks of the corresponding queries. In the coarse stage, the row-column relative position-aware self-attention (RowColRPA) mechanism is employed to capture global information of the instance queries with spatial relations. Subsequently, a max-pooling layer is employed to obtain the cell feature. In the fine stage, the instance queries undergo the relative position-aware cross-attention (RPCA) to fuse the multi-modal features with the relative position information, which effectively leverages the spatial relations and the contextual information from both point cloud and language modalities. By leveraging the instance query extractor and the relative position-aware attention mechanisms, our method addresses the two limitations, including the dependency on groundtruth instance as input and the failure to capture relative position information.
To summarize, the main contributions of this work are as follows:
• We propose an instance-free relative position-aware text-to-point*-cloud localization (IFRP-T2P) model, which adopts instance queries to represent potential instances in cells, thus removing the reliance on ground-truth instances as input.
• We design a RowColRPA module in the coarse stage and a RPCA module in the fine stage to fully leverage the spatial relation information of the potential instances.
• We conduct extensive experiments on the KITTI360Pose [21] dataset and illustrate that our model achieves comparable performance to the state-of-the-art models without using ground-truth instances as input.
This paper is
[story continues]
tags