Table of Links
3.2 Measuring Learning with Coding and Math Benchmarks (target domain evaluation)
3.3 Forgetting Metrics (source domain evaluation)
4 Results
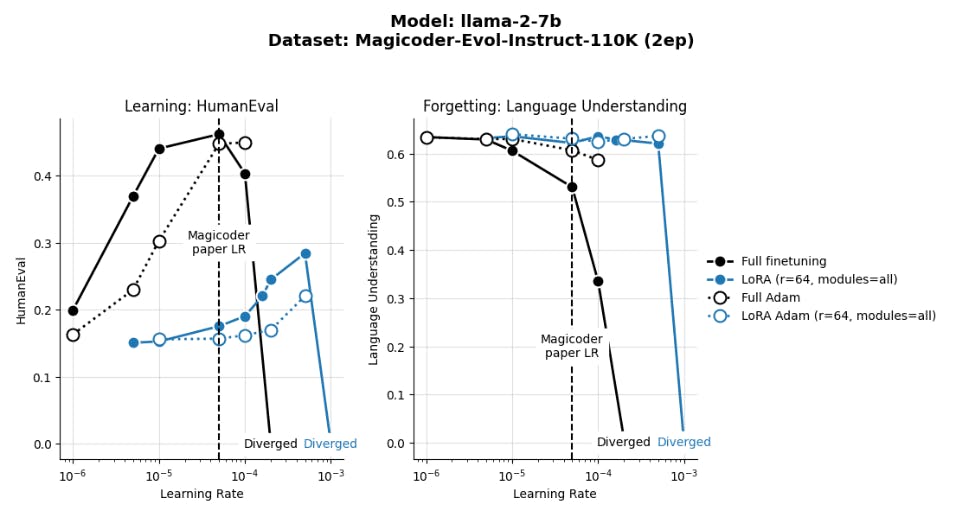
4.1 LoRA underperforms full finetuning in programming and math tasks
4.2 LoRA forgets less than full finetuning
4.3 The Learning-Forgetting Tradeoff
4.4 LoRA’s regularization properties
4.5 Full finetuning on code and math does not learn low-rank perturbations
4.6 Practical takeaways for optimally configuring LoRA
Appendix
D. Theoretical Memory Efficiency Gains with LoRA for Single and Multi-GPU Settings
5 Related Work
Extensions to LoRA LoRA has inspired many variants and extensions that are more memory-efficient or performant, such as QLoRA (Dettmers et al., 2024), VeRA (Kopiczko et al., 2023), DoRA (Liu et al., 2024), Chain of LoRA (Xia et al., 2024), and GaLoRe, (Zhao et al., 2024a), as well as efficient inference techniques building on LoRA, such as S-LoRA (Sheng et al., 2023).
Benchmarking LoRA vs. Full Finetuning The original LoRA study by Hu et al. (2021) reported that LoRA matched full finetuning performance for RoBERTa (Liu et al., 2019) on GLUE (Wang et al., 2018), and GPT-2 on E2E NLG Challenge (Novikova et al., 2017), and GPT-3 on WikiSQL (Zhong et al., 2017), MNLI (Williams et al., 2017), and SAMSum (Gliwa et al., 2019). Many subsequent studies follow this template and report encoder model performance on tasks in GLUE such as SST-2 (Socher et al., 2013) and MNLI (Williams et al., 2017). Models such as RoBERTa are less than 340M parameters, however, and classification tasks such as MNLI are quite trivial for modern billion-parameter LLMs such as Llama-2-7B. Despite LoRA’s popularity, only a few studies have rigorously compared LoRA to full finetuning in this setting and with challenging domains such as code and math. Dettmers et al. (2024) for example found that QLoRA matched full finetuning MMLU (Hendrycks et al., 2020) performance when finetuning Llama-1 7B, 13B, 33B and 65B on the Alpaca (Taori et al., 2023) and FLAN (Chung et al., 2024) datasets. Ivison et al. (2023) on the other hand found that QLoRA did not perform as well as full finetuning for Llama-2-7B, 13B and 70B models trained on the Tülü-2 dataset when evaluated across a suite of tasks including MMLU, GSM8K, AlpacaEval (which uses LLM-as-a-judge; (Dubois et al., 2024)) and HumanEval. One recent notable study is Astraios, which found that LoRA performed worse than full finetuning on 8 datasets and across 4 model sizes (up to 16 billion parameters), on 5 representative code tasks (Zhuo et al., 2024). Our study corroborates these results.
The conclusions have also been mixed with regards to the practical details surrounding LoRA target modules and rank: Raschka (2023) and Dettmers et al. (2024) show that optimized LoRA configurations perform as well as full finetuning, and that performance is governed by choice of target modules but not rank. In contrast, Liu et al. (2024) shows that LoRA is sensitive to ranks. It is likely that some of these discrepancies are due to differences in finetuning datasets and evaluations.
Learning-Forgetting tradeoffs Continual learning on a new target domain often comes at the expense of performance in the source domain (Lesort et al., 2020; Wang et al., 2024). A relevant example is that code-finetuned LLMs lose some of their capabilities in language understanding and commonsense reasoning (Li et al., 2023; Roziere et al., 2023; Wei et al., 2023). A common approach to mitigate forgetting involves “replaying” source-domain data during continual learning, which can be done by storing the data in a memory buffer, or generating it on the fly (Lesort et al., 2022; Scialom et al., 2022; Sun et al., 2019).
Authors:
(1) Dan Biderman, Columbia University and Databricks Mosaic AI (db3236@columbia.edu);
(2) Jose Gonzalez Ortiz, Databricks Mosaic AI (j.gonzalez@databricks.com);
(3) Jacob Portes, Databricks Mosaic AI (jportes@databricks.com);
(4) Mansheej Paul, Databricks Mosaic AI (mansheej.paul@databricks.com);
(5) Philip Greengard, Columbia University (pg2118@columbia.edu);
(6) Connor Jennings, Databricks Mosaic AI (connor.jennings@databricks.com);
(7) Daniel King, Databricks Mosaic AI (daniel.king@databricks.com);
(8) Sam Havens, Databricks Mosaic AI (sam.havens@databricks.com);
(9) Vitaliy Chiley, Databricks Mosaic AI (vitaliy.chiley@databricks.com);
(10) Jonathan Frankle, Databricks Mosaic AI (jfrankle@databricks.com);
(11) Cody Blakeney, Databricks Mosaic AI (cody.blakeney);
(12) John P. Cunningham, Columbia University (jpc2181@columbia.edu).
This paper is