This is the second part of the trilogy focusing on performance evaluation infrastructure for conversational AI agents.
- Part 1 - Metrics: Swallow the Red Pill
- Part 2 - Metrics Reloaded: The Oracle
- Part 3 - The Metrics Revolution: Scaling
Quick Recap
In case you have not read the first part of this trilogy, we focused on some high level questions of what and why about metrics needed to ensure end user performance for an AI agent.
Here is a summary:
-
User Perceived Metrics and User Reported Metrics form the foundation for a highly reliable conversational assistant.
-
Reliability and Latency are two different aspects to evaluate end user performance for conversational agents.
-
Never fully trust a metric - always question negative and positive movement in a metric.
-
It is crucial to identify these metrics from early development stage to objectively measure the performance of an AI agent.
In this article, we will focus on how to obtain these metrics in a manner that is easy to use, accurate and actionable.
The Oracle
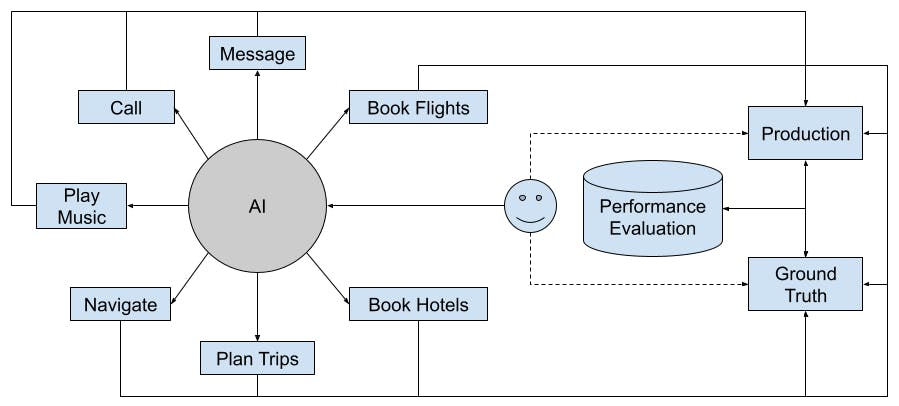
We hope there was a “oracle” which could provide highly accurate end user performance metrics. Guess what? There is! We as humans are extremely good at doing this. However this comes as a cost of efficiency. The amount of data points are less but highly confident. We will discuss some ways to mitigate this gap.
-
Human Testing: This can be the QA team or developers or PMs or executives testing the product. It is important to realize the value for this data - is truly the “golden dataset” for metrics. This also shows that there is no replacement for testing your product manually.
-
Automated Lab Testing: There can be test benches setup where a different software analyzes automated testing via audio and visual processing. This helps us increase coverage for the “golden dataset” metrics.
There should be infrastructure in place to analyze these data points and referred to as the “ground truth”.
The Next Best Thing
While ground truth provides highly confident set of metrics, it cannot replicate all the conditions that might be occur for a real user in production. Note that this might have lower confidence but is needed to uncover unanticipated issues.
Hence, there is a need to invest in ensuring we have logging signals in place for production metrics. There are few things to be cautious of for production logging.
Privacy and security implications must be kept in mind
This is pretty much self-explanatory but all production logs should be aggregated and anonymized to protect against any privacy and security issues.
Log only what is needed
On the second point, it is important to note that success metrics need to be decided beforehand and then the corresponding logs need to be identified from that. It is easy to just add a lot of logging and then determine the metrics we can derive. This actually ends up polluting the metrics making it less objective and only ends up measuring the metrics we can based on available logs.
The other drawback for logging a lot is that it can end up affecting user behavior, causing performance degradation.
Keep Logging simple
It is important to note that while metrics should drive what logs are needed, logs should not try to derive metrics. In other words, logging should just capture what event happened and when. The derivation should happen on the metric processing side and not during the user interaction. This helps to keep logging and metric derivation orthogonal - single responsibility :)
Keeping logging simple also helps with reducing unnecessary complexity in production code which can result in unexpected errors and lead to performance degradation.
Putting everything together
The two types of metric collection processes we discussed here are complementary to each other.
-
Production metrics have high coverage but lower confidence.
-
Ground truth metrics have low coverage but high confidence.
As a result, both of these should be used together to create a highly reliable and fast conversational agent. For any new changes (user facing or not), both the metric systems should be used to verify if there is any degradation in end user performance.
The metric collection processes should aim to improve each other:
- Production metrics should be validated against “ground truth” metrics. A lot of deviation suggests issues with production logging or metric instrumentation pipeline.
- Issues captured by production metrics that have not been flagged by “ground truth” metrics reveal gaps in human or semi-automated metric pipeline. These can be used to add new manual or semi-automated tests to improve the coverage for “ground truth” metrics.
High Level Takeaways
-
Ground truth and production metrics complement each others for ensuring performance.
- These two metric pipeline should be used to improve each other.
-
Metric collection from production should not affect degrading performance.
- Metrics should dictate what logs needed to be added.
- Logs should be harmless and simple.
- Metrics derivation and logs should be orthogonal.
What’s Next?
As our conversation AI agent scales across different devices - phones, tablets, cars, earphones - it is becomes vital that the performance evaluation infrastructure can also scale seamlessly. We discuss more details on scaling performance metrics infrastructure in the final part of the trilogy - stay tuned!