
Table of Links
-
Related Works
-
Methodology
4.1 Formulation of the DRL Problem
4.2 Instance-Aware Deep Reinforcement Learning for Efficient Index Selection
-
Experiments
4.2 Instance-Aware Deep Reinforcement Learning for Efficient Index Selection
Our TD3-TD-SWAR model, developed for the Index Selection Problem (ISP), enhances action space pruning through the incorporation of a selector network (𝐺𝜃 ). This network selectively masks actions based on their relevance, concentrating on those with substantial impact to improve computational efficiency. The model extends the traditional Actor-Critic reinforcement learning framework [4], exemplified by TD3 [3], by adding specific features. One such addition is a blocking diagram that highlights the crucial role of the selector networks, depicted in Figure 2. This approach is grounded in minimizing Temporal Difference (TD) error (L𝑇𝐷), directing actors towards the most beneficial actions in accordance with the task’s goals:
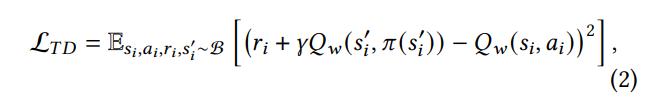
where the introduction of 𝐺𝜃 and the blocking diagram in our model signifies our additional design on the existing Actor-Critic RL frameworks like TD3, emphasizing the selector networks’ role in optimizing the action selection process
Training of 𝐺𝜃 exploits the TD error differences between baseline (unmasked actions) and critic networks (masked actions), pinpointing actions’ contributions under storage constraints. This discrepancy informs 𝐺𝜃 ’s refinement, employing policy gradients for targeted action exploration
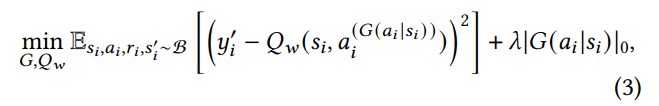
This process not only reduces computational demand by focusing on essential actions but also dynamically adjusts 𝐺𝜃 , ensuring action selection is closely aligned with ISP’s strategic goals, thereby improving learning efficiency and decision quality. Basic ideas of this proposed RL algorithm are presented in Algorithm 1.
Authors:
(1) Taiyi Wang, University of Cambridge, Cambridge, United Kingdom (Taiyi.Wang@cl.cam.ac.uk);
(2) Eiko Yoneki, University of Cambridge, Cambridge, United Kingdom (eiko.yoneki@cl.cam.ac.uk).
This paper is
[story continues]
tags