
You can find me on Twitter @bhutanisanyam1, connect with me on Linkedin hereHere and Here are two articles on my Learning Path to Self Driving Cars
If you want to read more Tutorials/Notes, please check this post out
These are the Lecture 1 notes for the MIT 6.S094: Deep Learning for Self-Driving Cars Course (2018), Taught by Lex Fridman
Lecture 2 Notes can be found hereLecture 3 Notes can be found hereLecture 4 Notes can be found hereLecture 5 Notes can be found here
All images are from the Lecture slides.

Deep learning: Set of techniques that have worked well for AI techniques in recent years due to advancement in research and GPU capabilities. SDC are Systems that can utilize these.
Instructors are working on devoloping cars that understand environment inside and outside the car.
Competitions:
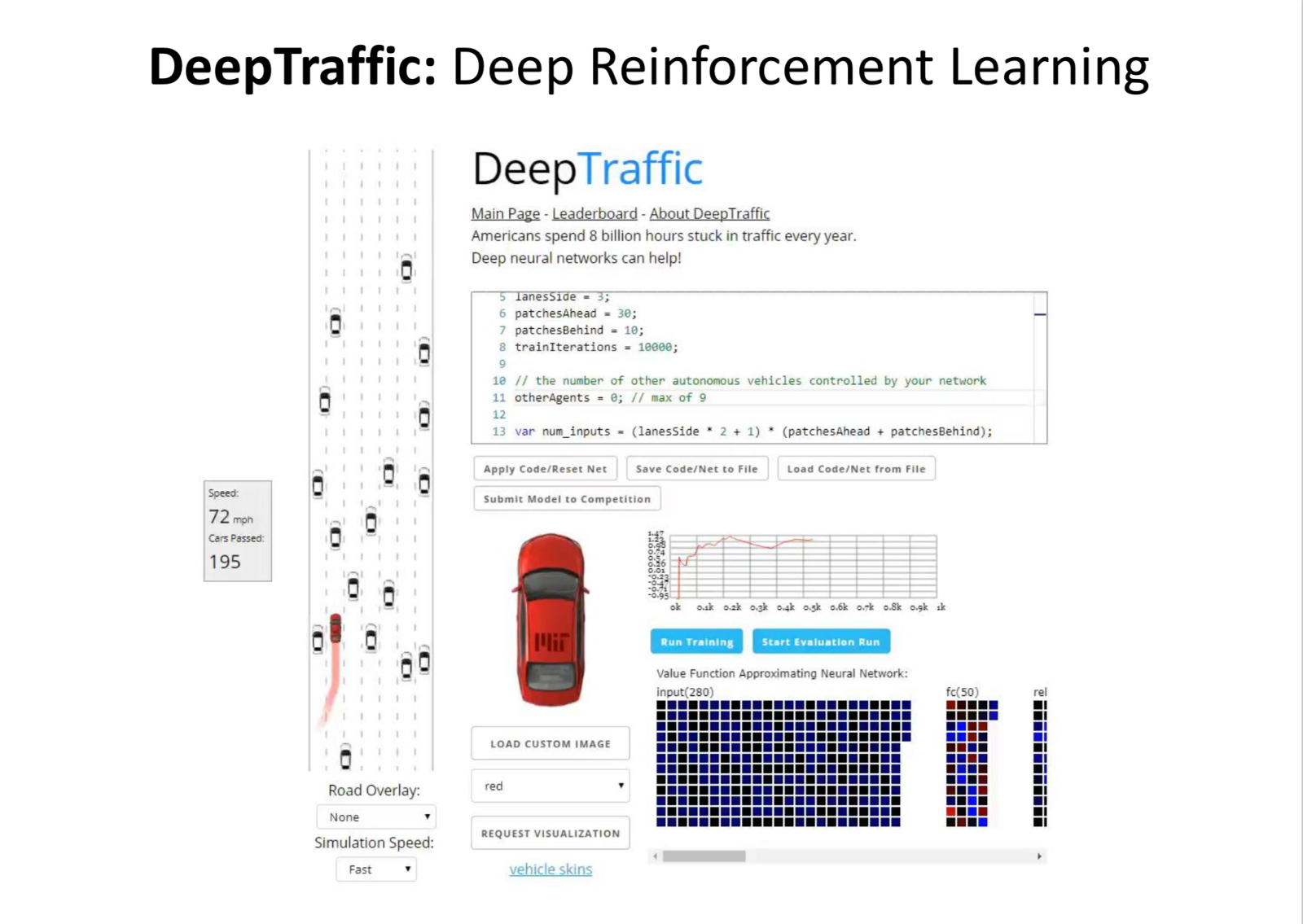
- DeepTraffic: Deep Reinfocement Learning competition, the code runs in browser. v2.0 now allows Multi-Agent training.

- SegFuse: Dynamic Driving Scene Segmentation competition. Given the Raw video, the kinematics (movements) of automobiles in the video. Training set gives us ground truth labels, pixel level labels, scene segmentation and Optical flow. Goal: To perform better than the State of the art in Image Based Segmentation. Need: Robots need to interpret, understand and track details of scene.

- Deep Crash: Goal: Use Deep RL to avoid High Speed Crash Avoidance. Training: 1000 runs to train a car model running at 30mph+ speeds with input from a Monocular camera.
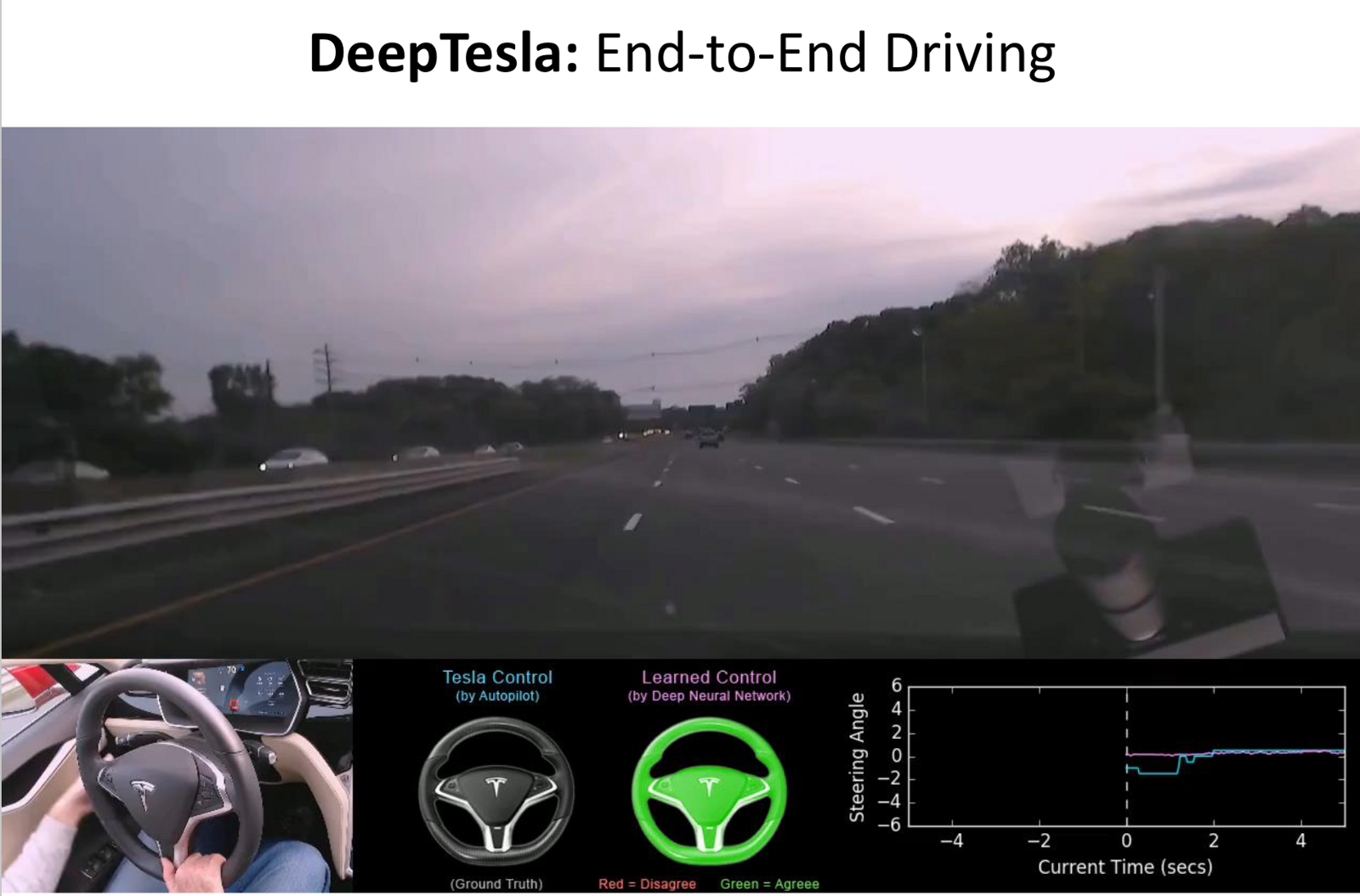
- DeepTesla: Using large scale networks to train end to end steering, using a monocular video as input for training.
Why Self Driving Cars?
Goal: Applying Data Driven learning methods to autonomous vehicle.
It’s a biggest integration of personal robots.
- Wide Reaching: Huge number of vehicles on road.
- Profound: An intimate connection between the car and human. Trusting the Robot with your life, a ‘transfer of control’ to the car. The life critical nature of the system if profound and will truly test the limits of the system.
Autonomous vehicle: It’s a Personal robot rather than a Perception-Control. The systems will need assistance from humans via a Transfer of control during situations. A truly Perceptional System having a dynamic nature with human equivalence maybe a few decades away.
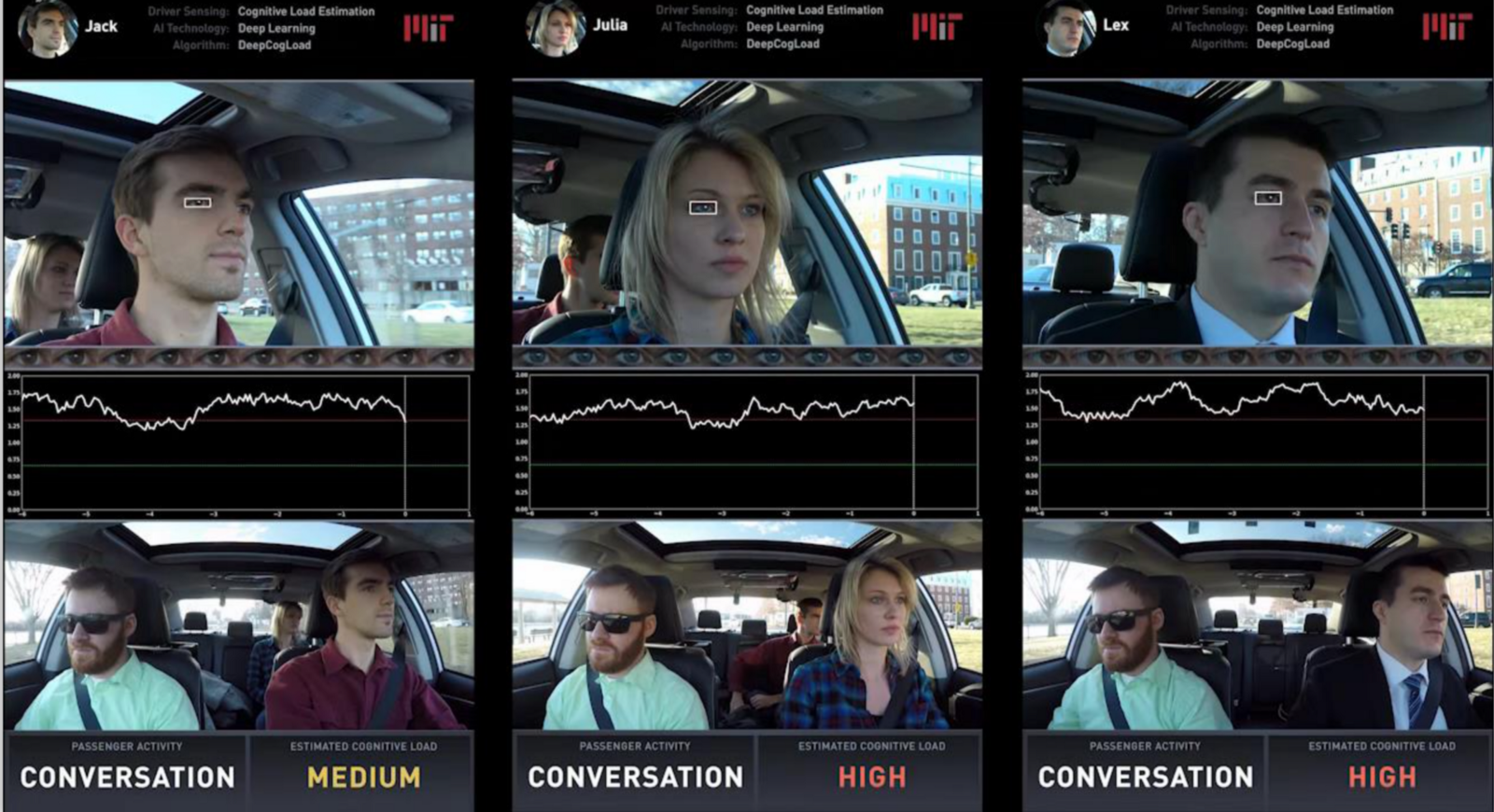
Cognitive load: A fully connected CNN takes in the raw 3D input to analyse the cognitive load,body pose estimation, drowsiness of the driver.
Argument: Full Autonomy requires achieving human level Intelligence for some fields.
Human-Centred Artifical Intelligence Approach
Proposal: Consider human presence in design of every algorithm.
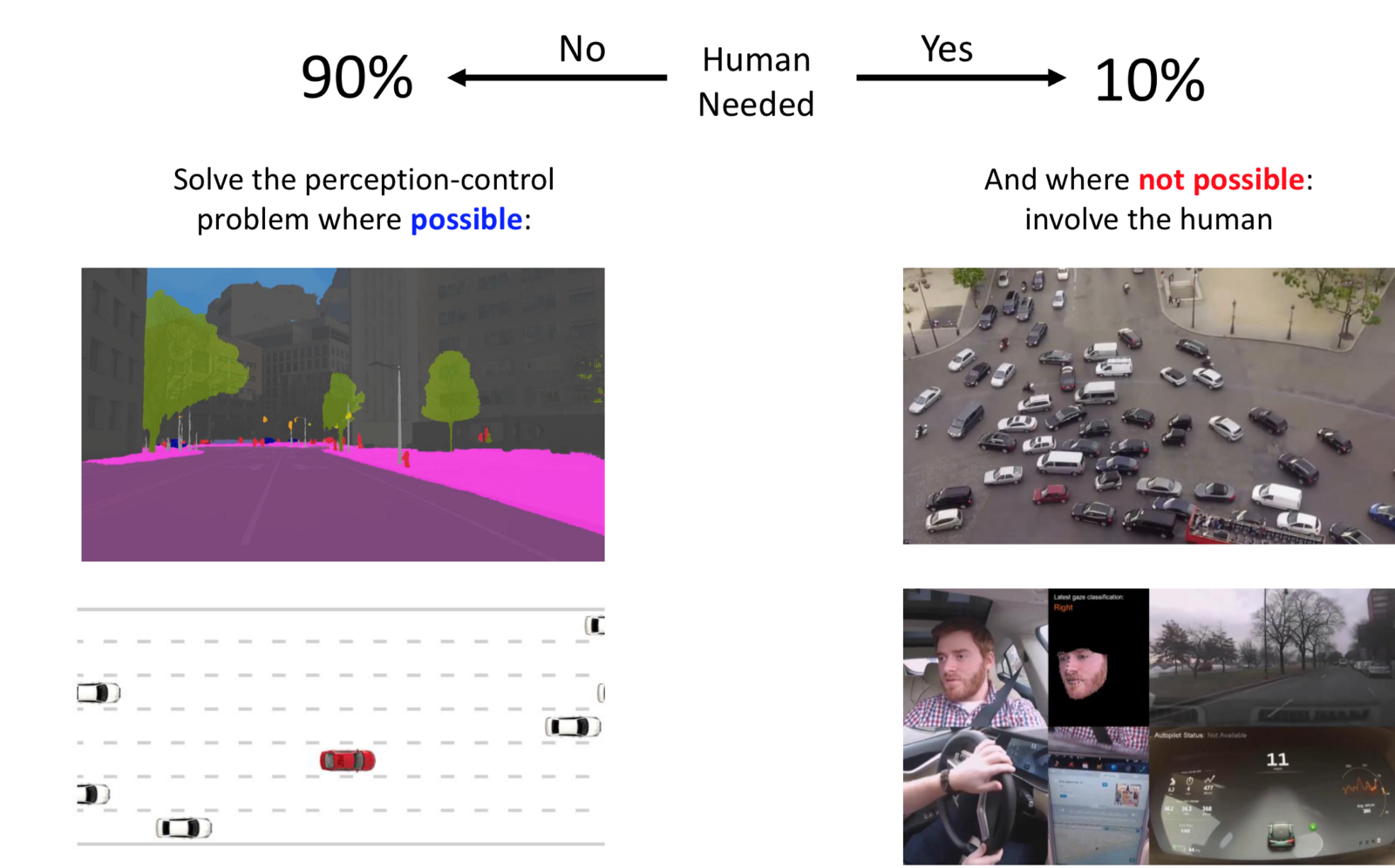
- Perception control can handle 90% of the cases.
- Human Control: Dominant in 10% of the cases.
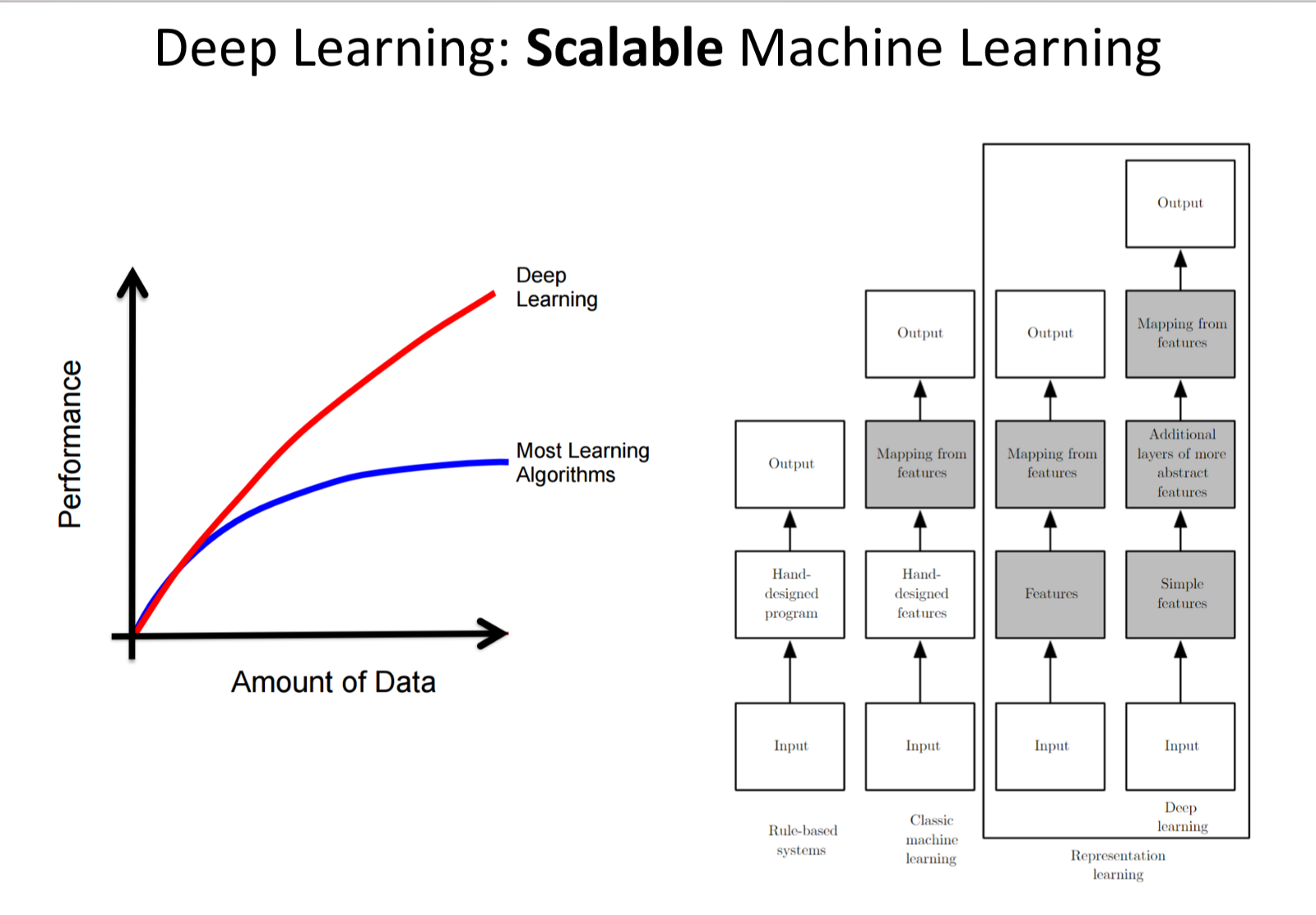
Why Deep Learning?
Deep learning Perform really well with huge data. Since human lives are directly dependent on the machines, techniques that learn from real world data are needed.
- Perception/Control Side
- Human based collobaration and interaction.
What is Deep Learning?
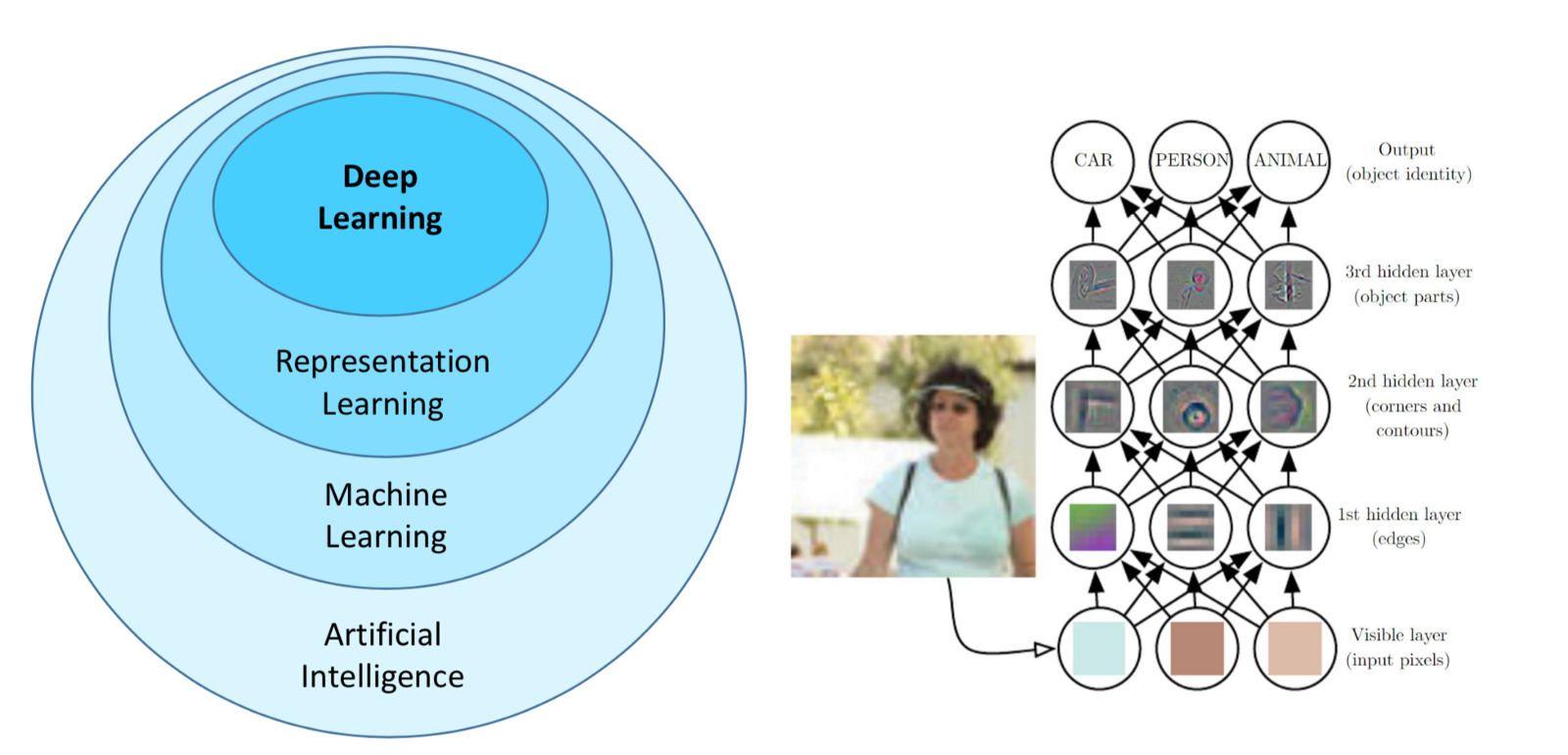
AI: Ability to accomplish complex goals.
Understanding/Reasoning: Ability to turn complex information into simple and useful information.
Deep learning (Representation Learning or Feature Learning) is able to take raw information without any meaning and is able to construct hierarchical representation to allow insights to be generated.
The most capable branch of AI that is capable of deriving structure from the data to allow to derivation of insights.
Representation Learning
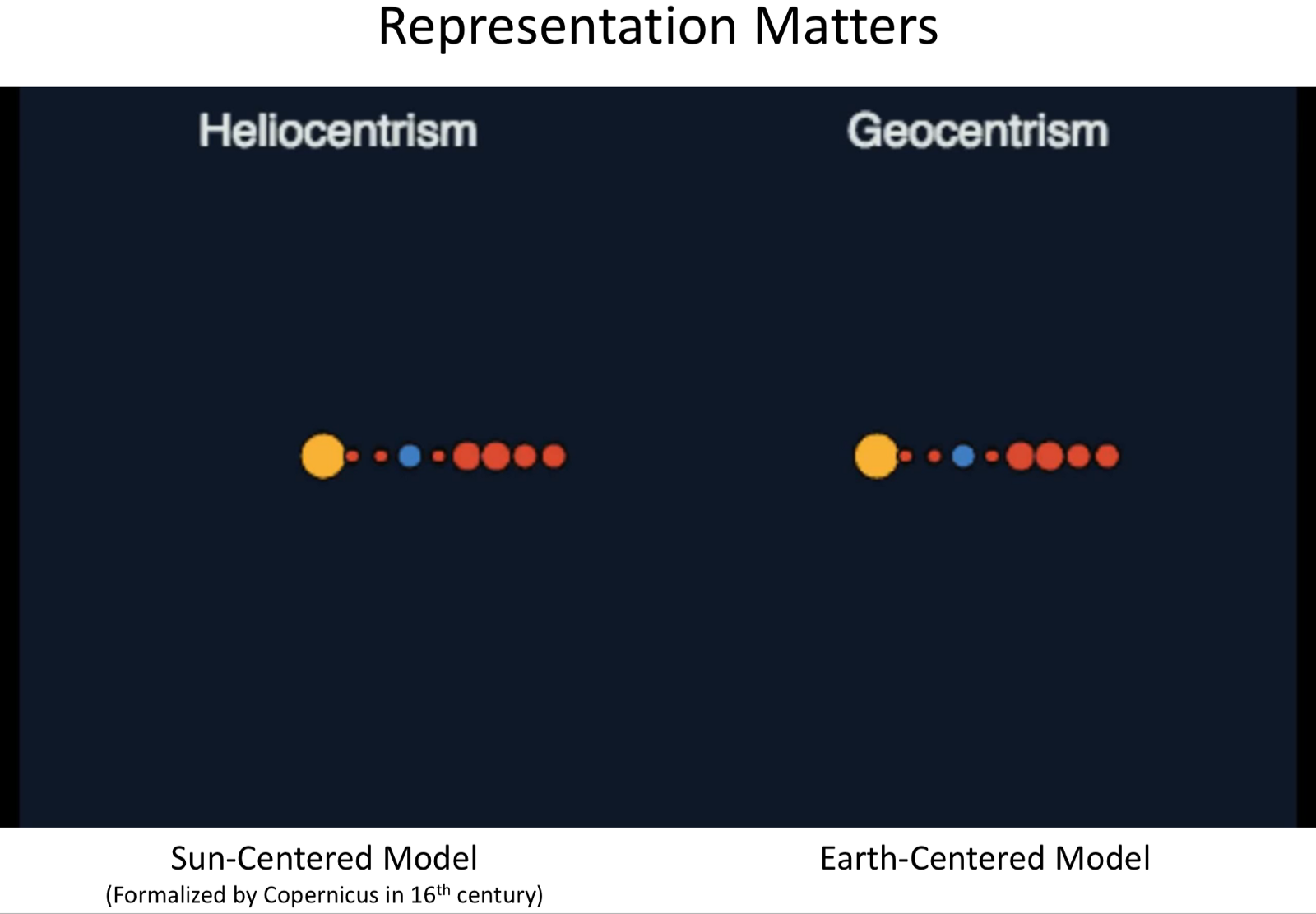
- Representation is important. Ex: Earth Centered Vs Sun Centred.

- Cartesian Vs Polar Cordinates to seperate circles and triangles
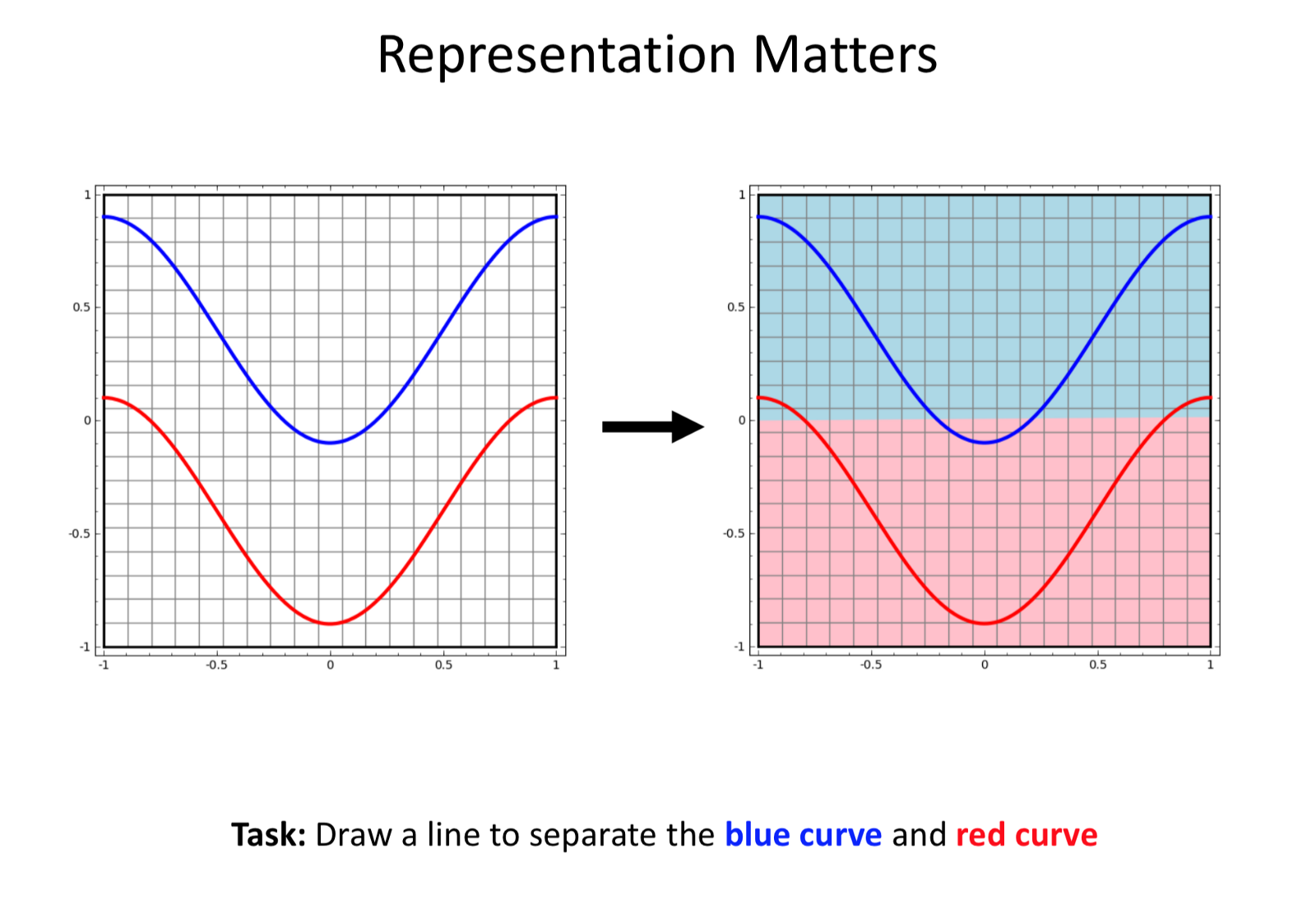
- Ex: To Seperate Blue Vs Red Curve using a 1 layer hidden Neural Net. The learning (Using raw input to generate outputs) of the function is achieve using Deep Learning
- Deep learning improves with more data.
- Generalisation over Edge cases is the main challenge for Deep Learning.
Neural Networks.
Inspired loosely by biological human neurons.
- Human NN: 100 billion Neurons, 1,000 Trillion Synapses
- State of the Art ResNet-52: 60 million Synapses.
- The difference is a 7 order of magnitude difference.
- Differences:
- Human NN have no stacking, ANN are stacked.
- No Order Vs Ordered
- Synchronous Learning Vs Asynchronous Learning
- Unknown Learning Vs Backprop
- Slower Processing Vs Faster Processing
- Less Power consumption Vs Inefficient
Similiarity: Both are distributed computation on a large scale.
A basic Neuron is simple, connected units allow much complex use cases.
Neuron:
- Neuron consists of inputs of a set of edges with weights
- The weights are multiplied
- A bias is added
- A non-linear function determines if the NN is activated.
Combination of NN:
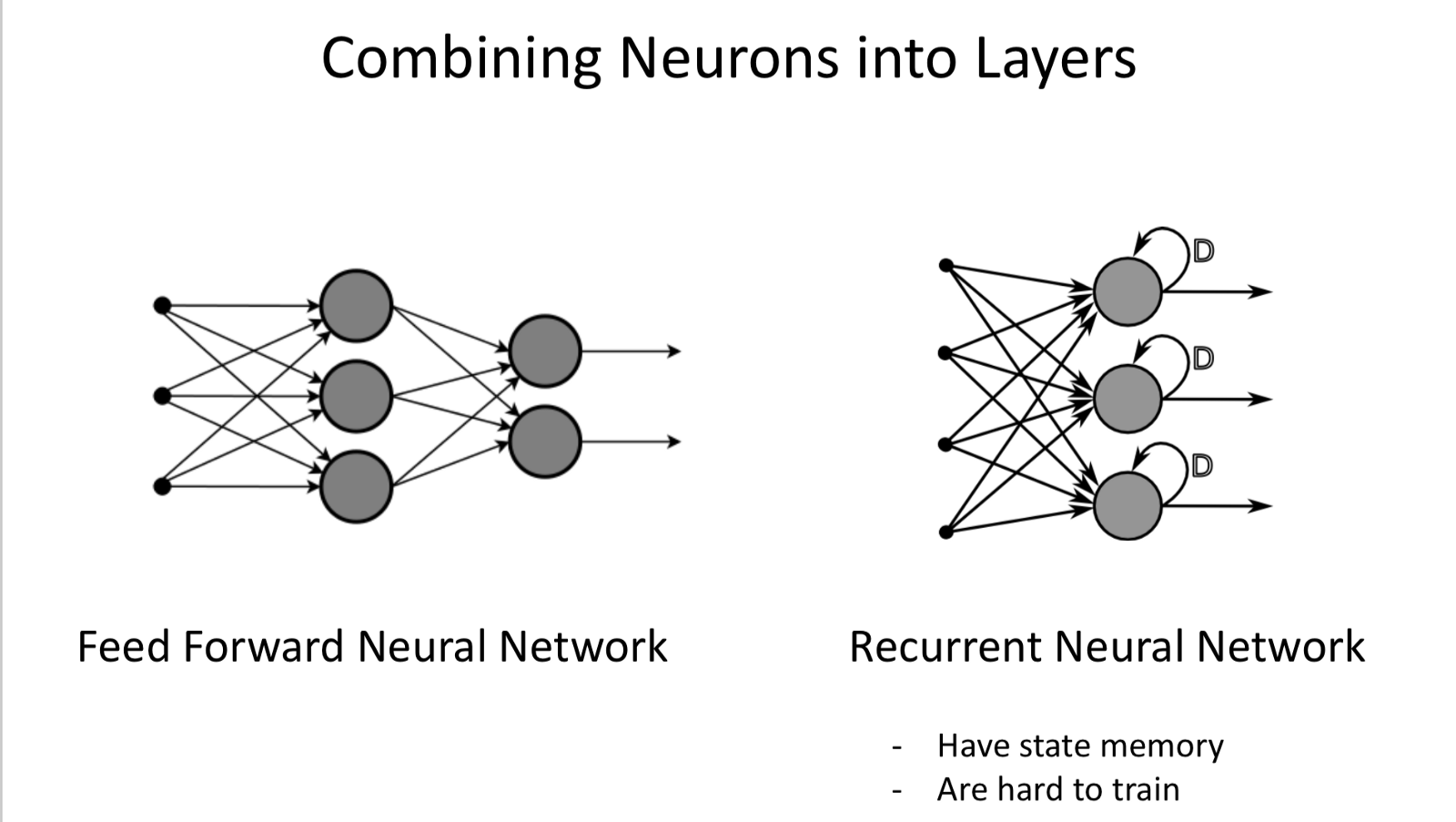
- Feed Forward NN: Successful in Computer Vision.
- Recurrent NN: Feed back into itself, have memory. Successful in Time Series related data, much similar to Human (hence are harder to train).
Universality: Mutiple Neural nets can learn to approximate any function with just 1 hidden network layer*
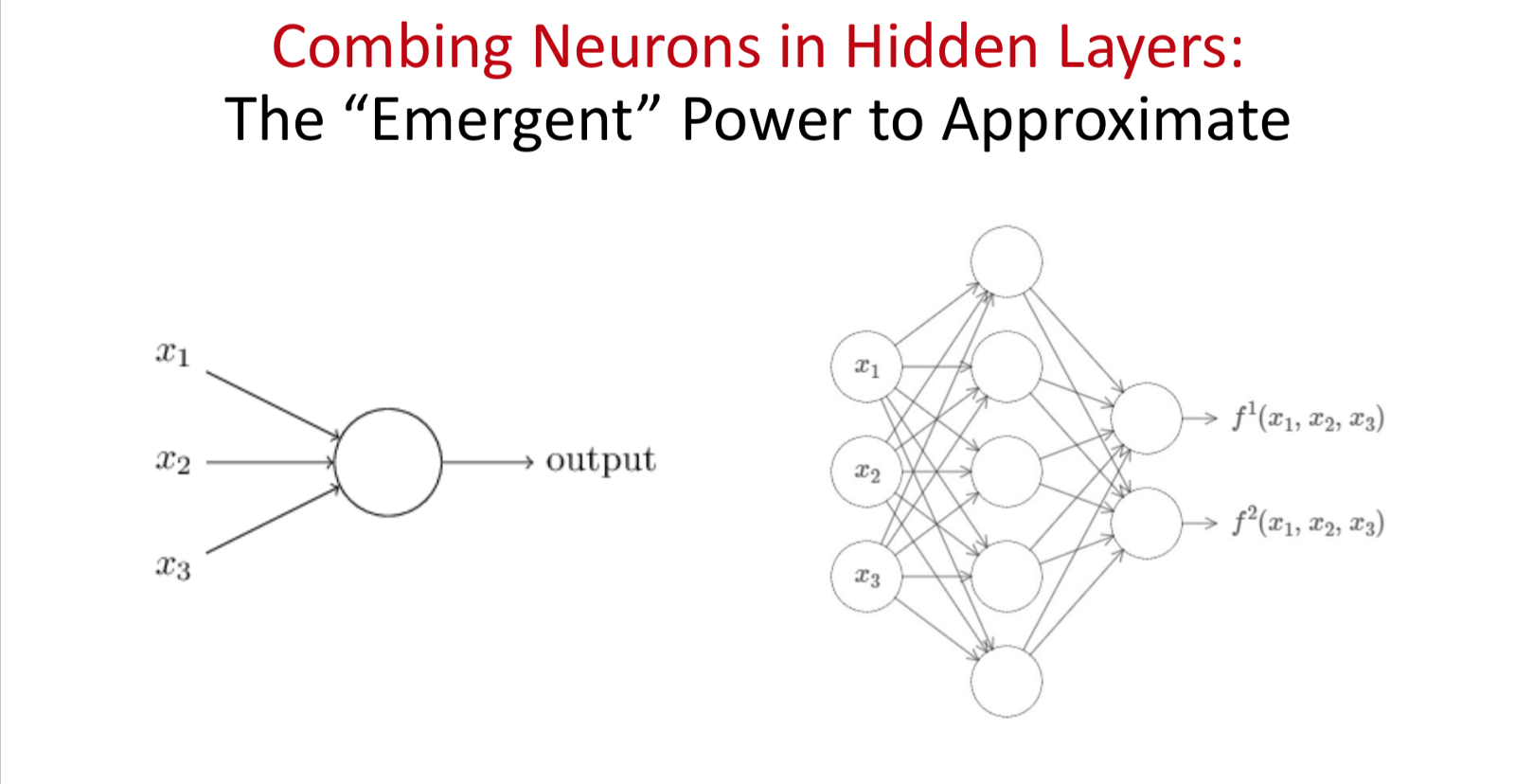
*Given good algorithms.
Limitation: Not in power of the Networks, but in the methods.
Categories of DL
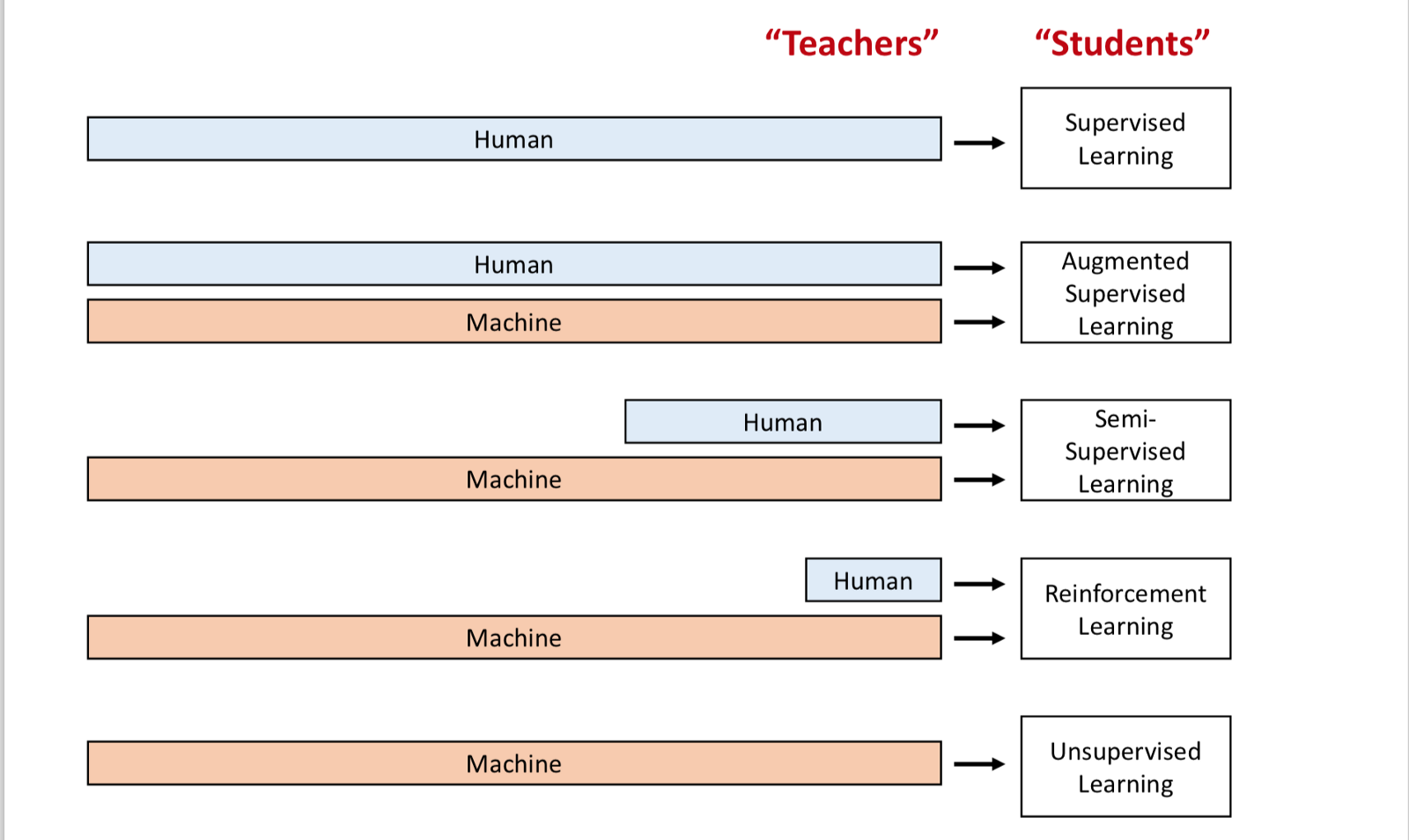
- Supervised Learning: Human annotation of data is needed.
- Augmented Supervised Learning: Human + Machine approach.
- Semi-Supervised
- Unsupervised Learning: Machine Input.
- Reinforcement Learning: Machine Input.
Currently being used: 1,2
Future and better categories: 3,4,5.
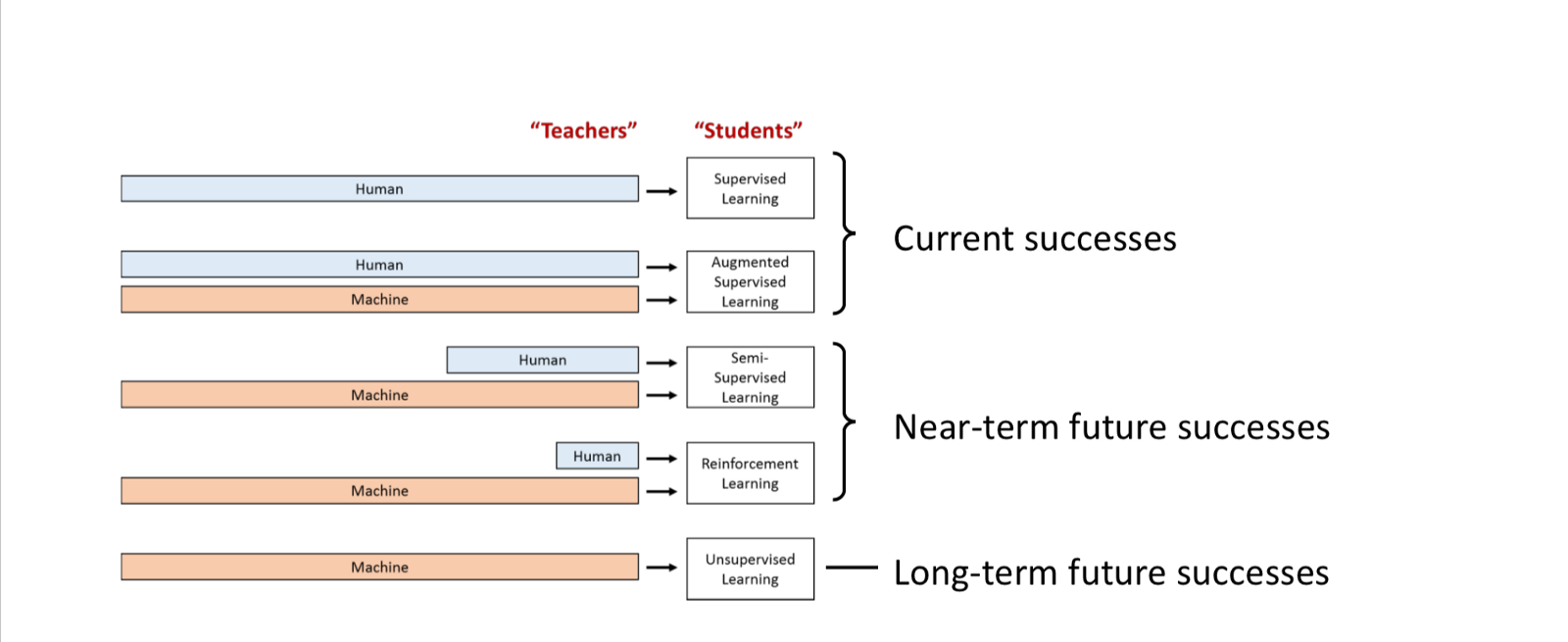
DL Impact Spaces:
- Defining and Solving a Particular Problem. ex: Boston Housing Price Estimation.
- General Purpose Intelligence (Or Almost): Reinforcement and Unsupervised Learning.
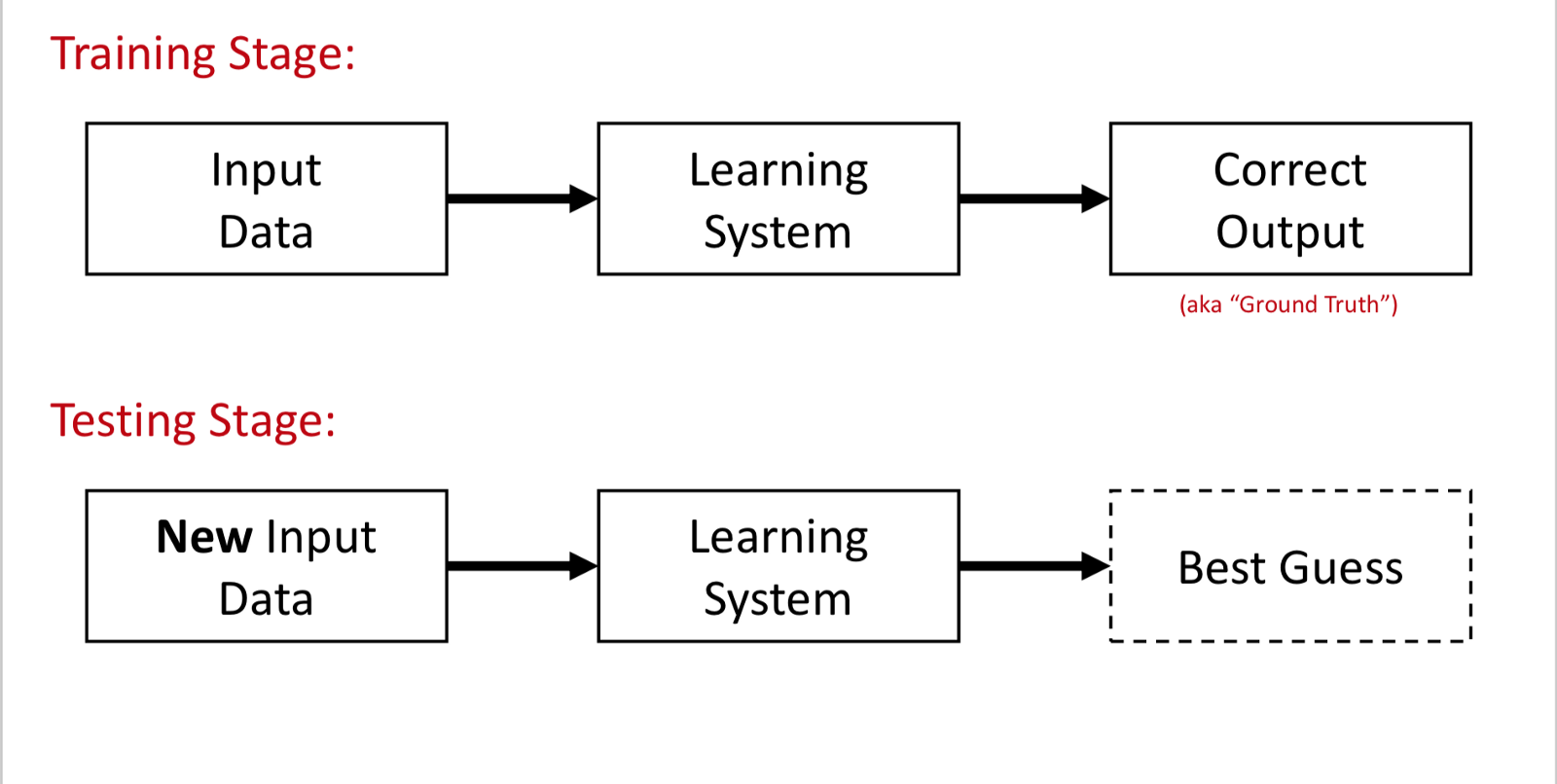
Supervised Learning
Training phases: 1. Input Data 2. Labels 3. Training of Data
Testing Stage: 1. New data 2. Inputted to learning system 3. Produce Output
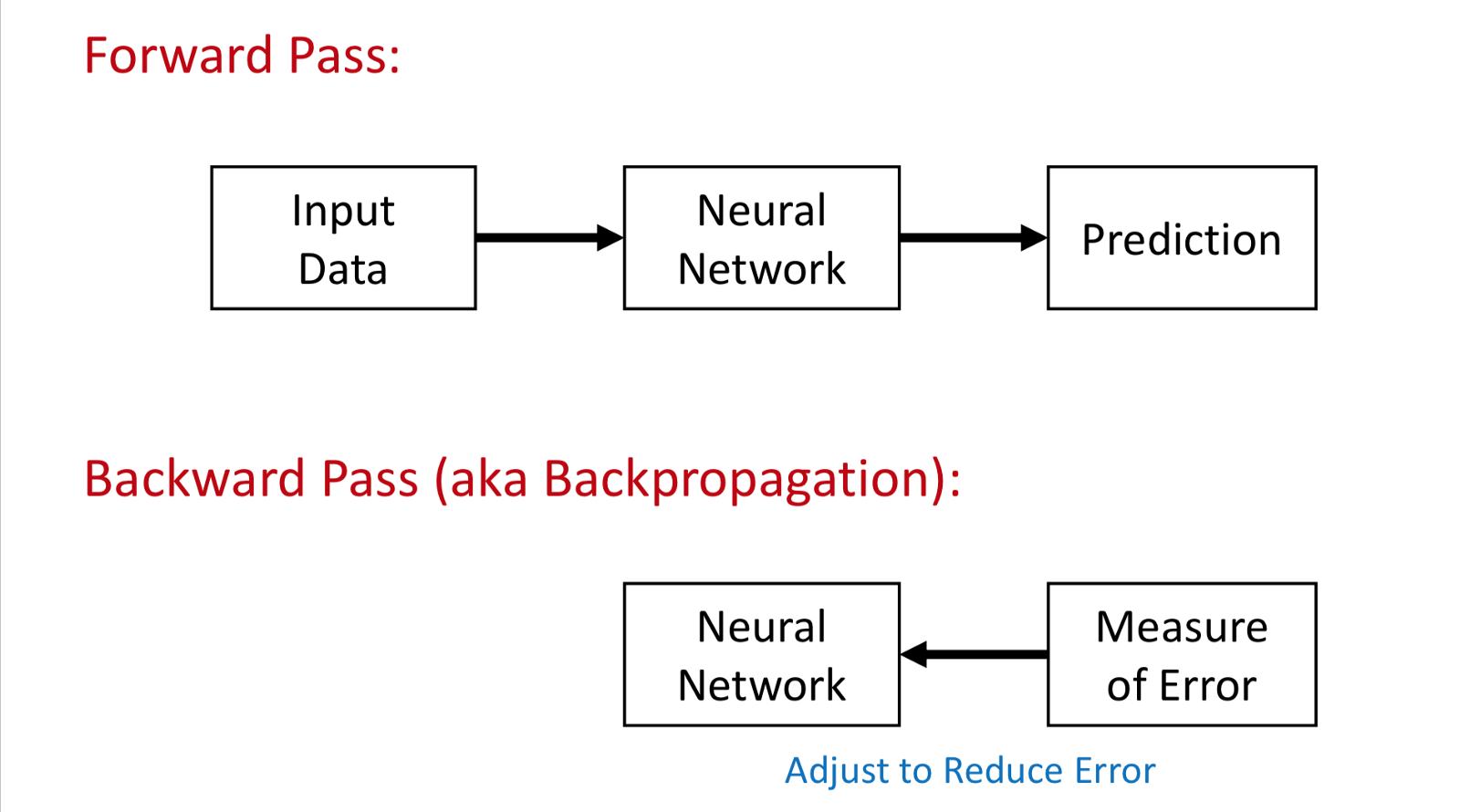
Learning
- Forward pass: Input data is fed into the NN and prediction is generated.
- Backpropagated: Measures deviation from the expected output and calculates error, adjusts the parameters (hyperparameters) used to predict the values according to the magnitude of error.
What can we do DL?
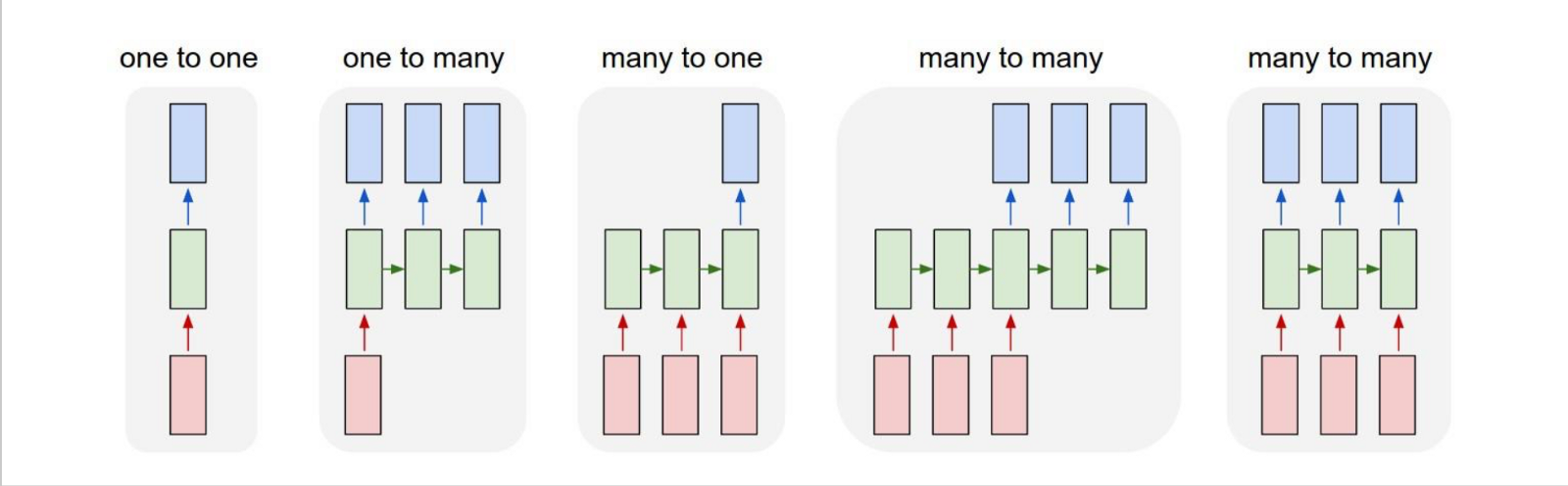
- One to One Mapping.
- One to Many
- Many to Many.
- Asynchronous Many to Many.
Terminologies:
- DL = NN (Deep Learning = Neural Nets).
- DL is a subset of ML (Machine Learning).
- MLP: Multi layer Perceptron.
- DNN: Deep Neural Networks.
- RNN: Recurrent Neural Networks.
- LSTM: Long Short Term Memory.
- CNN: Convolutinal Neural Networks.
- DBN: Deep Belief Networks.
Neural Network Operations:
- Convolution
- Pooling
- Activation Function
- Backpropogation
Activation Functions
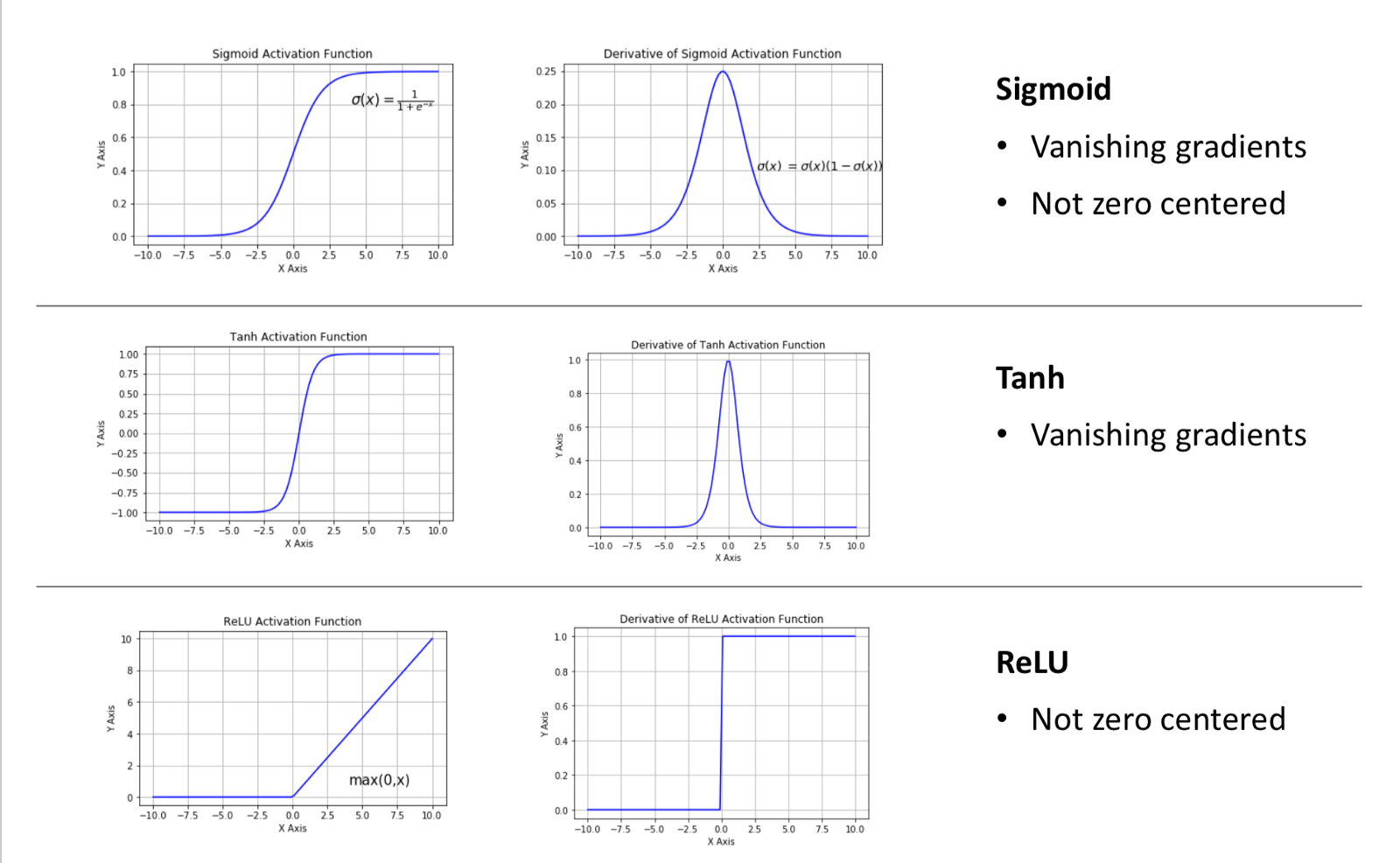
- Sigmoid. Cons: Vanishing Gradient, Not Zero Centred
- Tanh. Cons: Vanishing Gradients.
- ReLu. Cons: Not Zero Centred
Vanishing Gradients: When the output or gradient of the NN is very low and results in slow learning.
Backpropagation
Learning Process of the NN. Goal: Update the weights and biases to decrease loss function.
Subtasks:
- Forward pass to compute network output and error.
- Backward pass to compute gradients.
- A fraction of the weight’s gradient is subtracted from the weight.
Since the process is modular, it’s parallelizable.
Learning
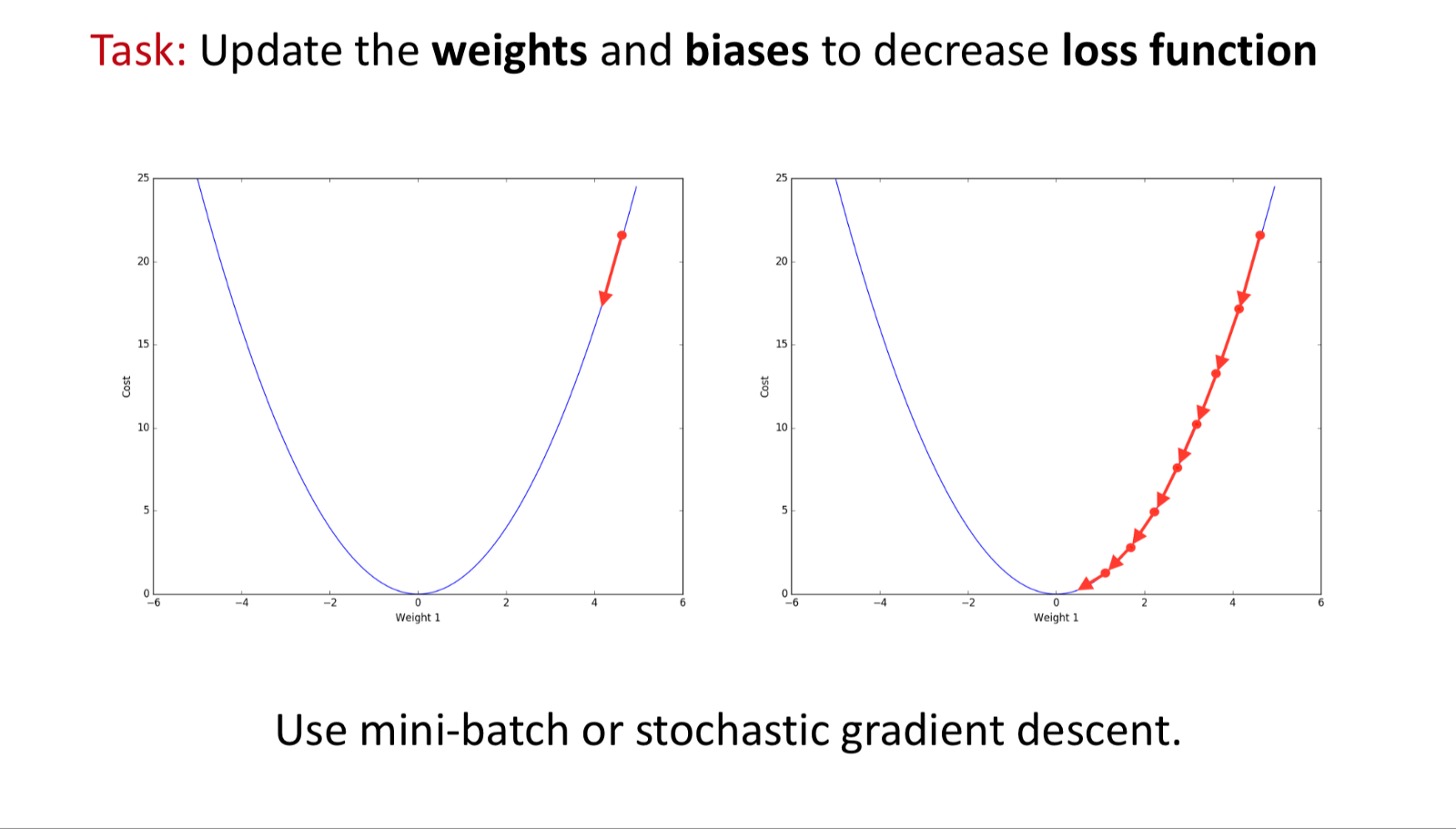
Learning is an optimization process.
Goal: To minimize the Loss Function by updating weights and biases.
Techniques used: Mini-batch Gradient Descent and Stochastic Gradient Descent.
Learning Challenge
- Loss function is highly non linear.
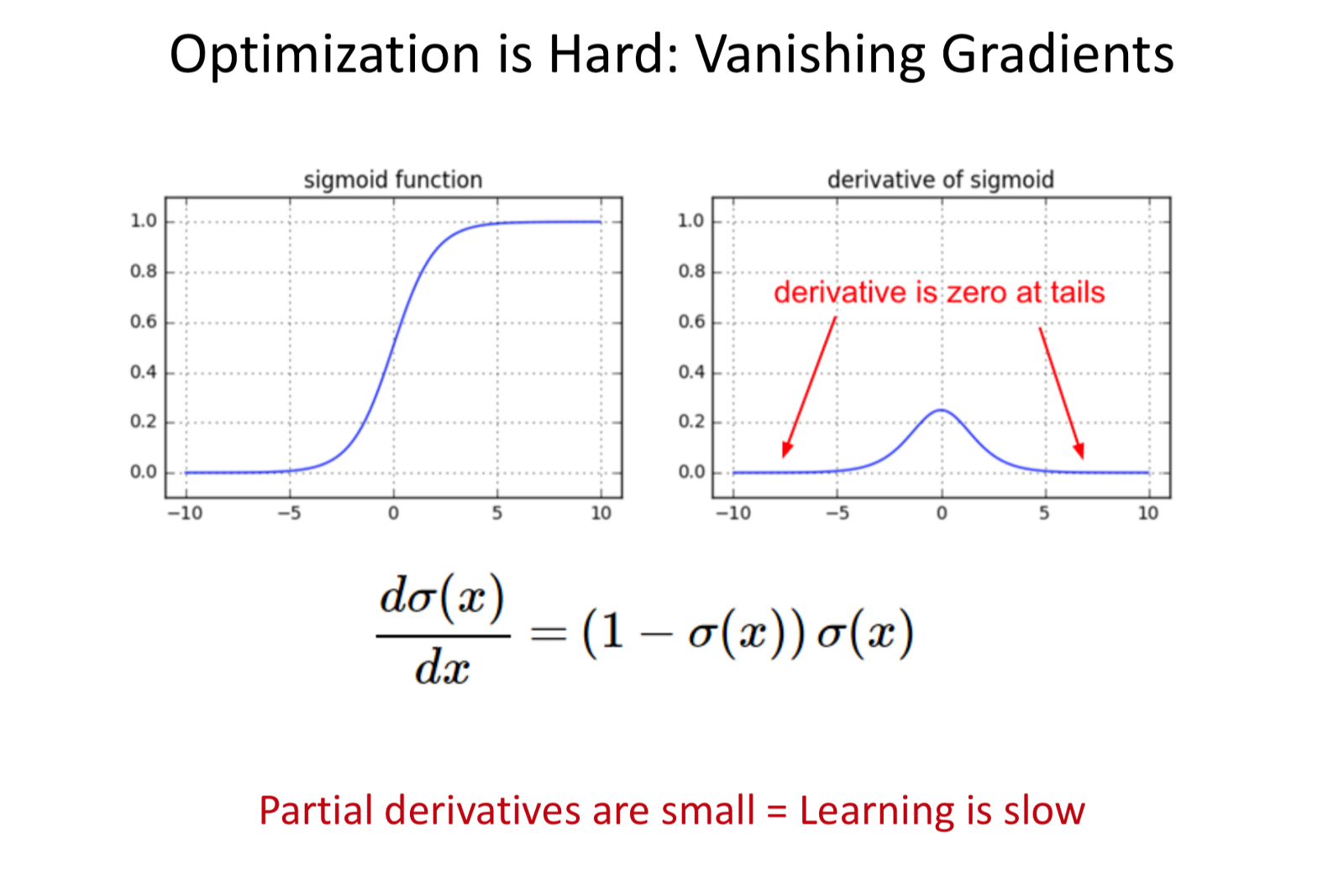
- Vanishing Gradient.
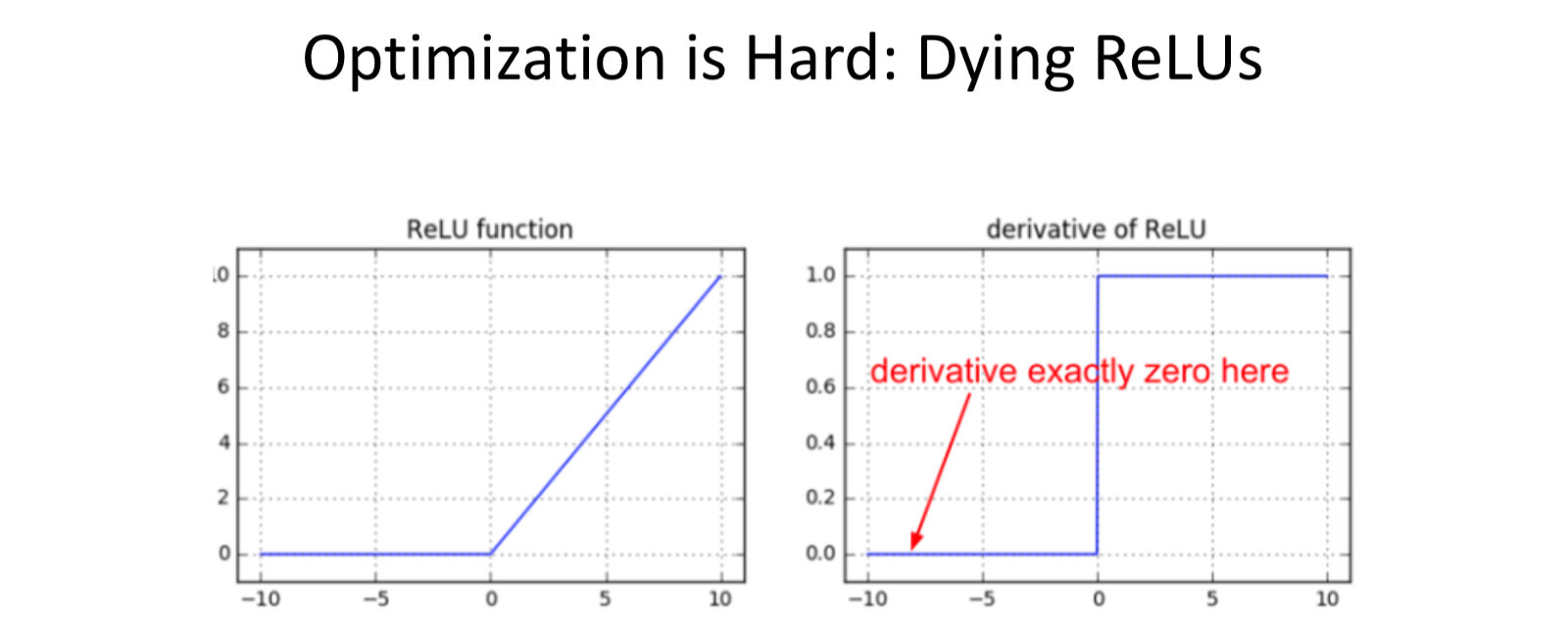
- Dying ReLU: Derivate = 0 for 0 inputs.
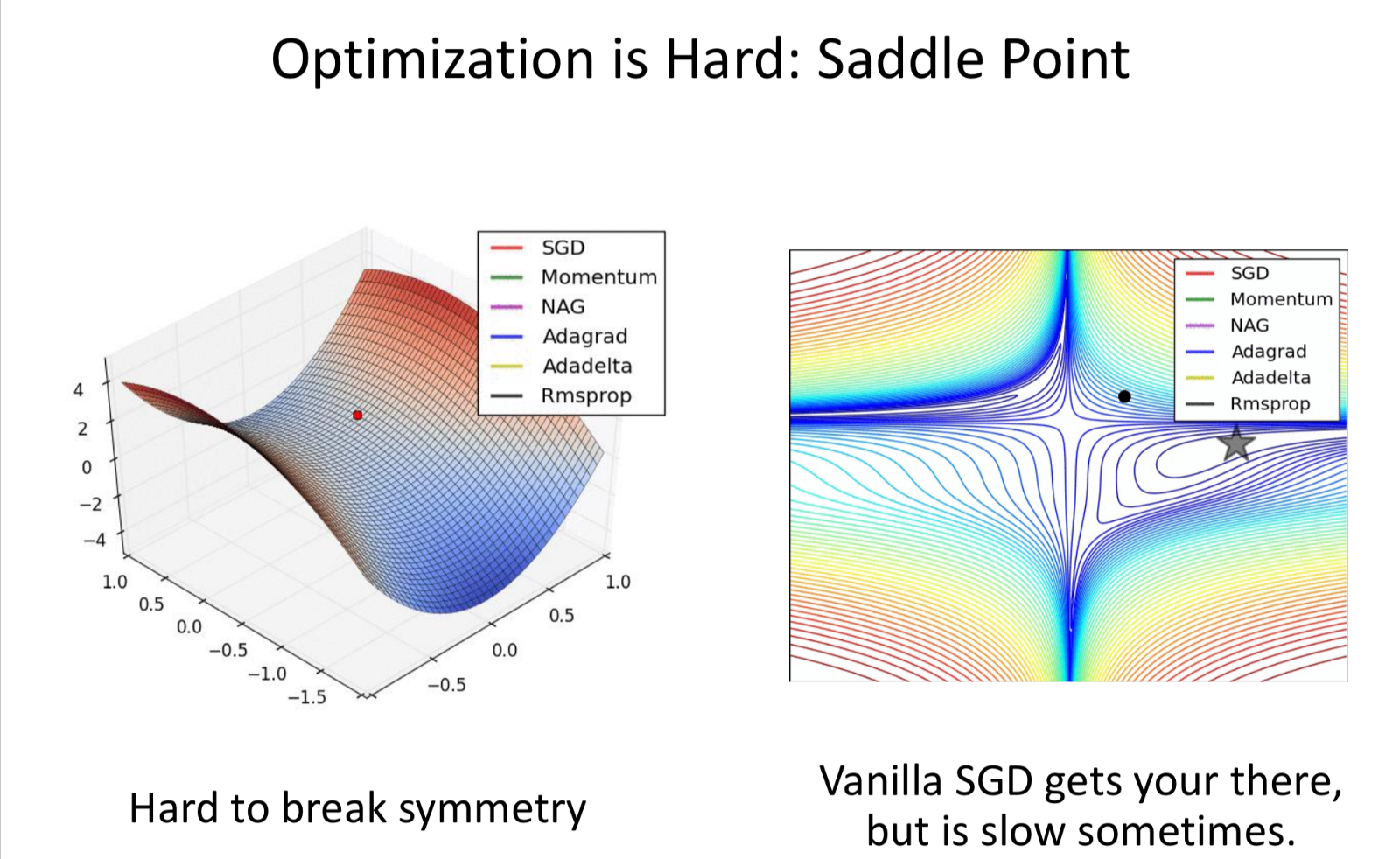
- Saddle Points.
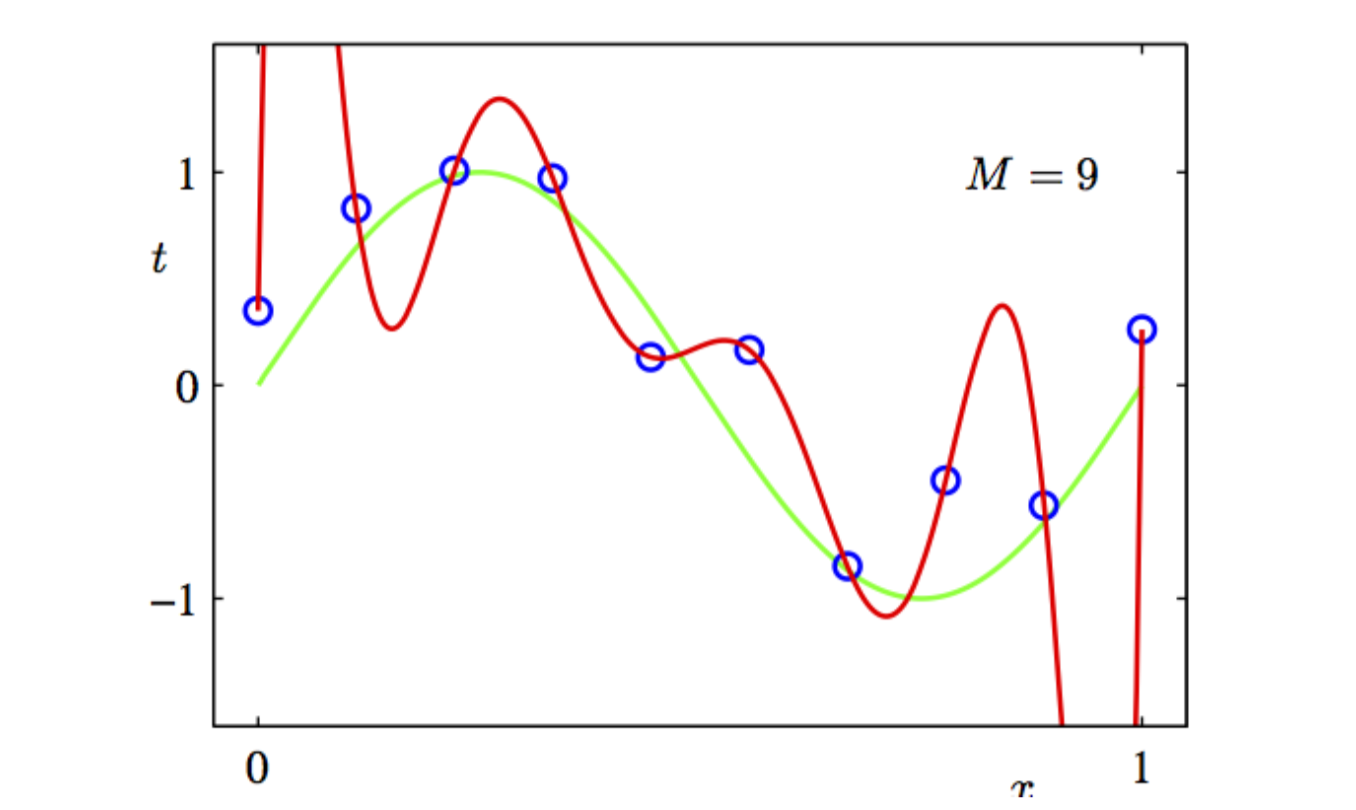
- Overfitting: NN Learns training data but fails to generalise well to real world data. Detected by: Low Training error but high Testing Error.
Regularization:
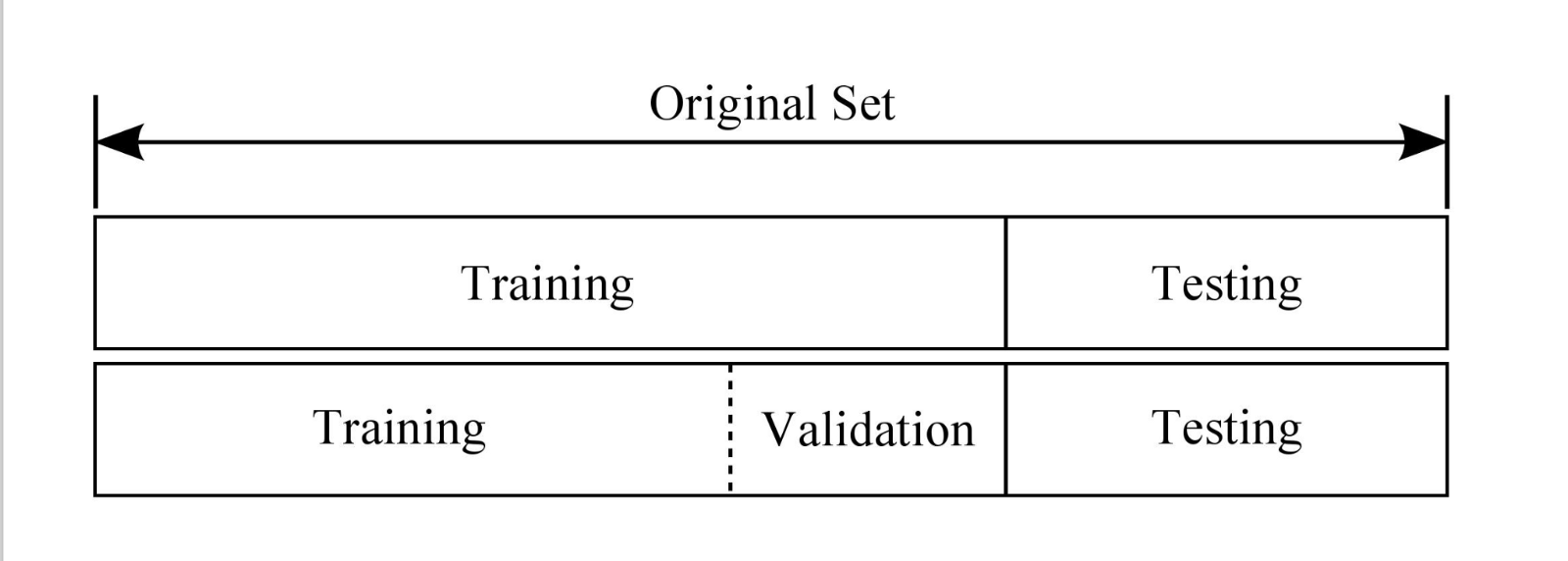
Techniques that help in generalising.
- Create Validation set: Subset of Training Data
- Early Stoppage: To save a checkpoint and evaluate how is the NN performing on Test Data.
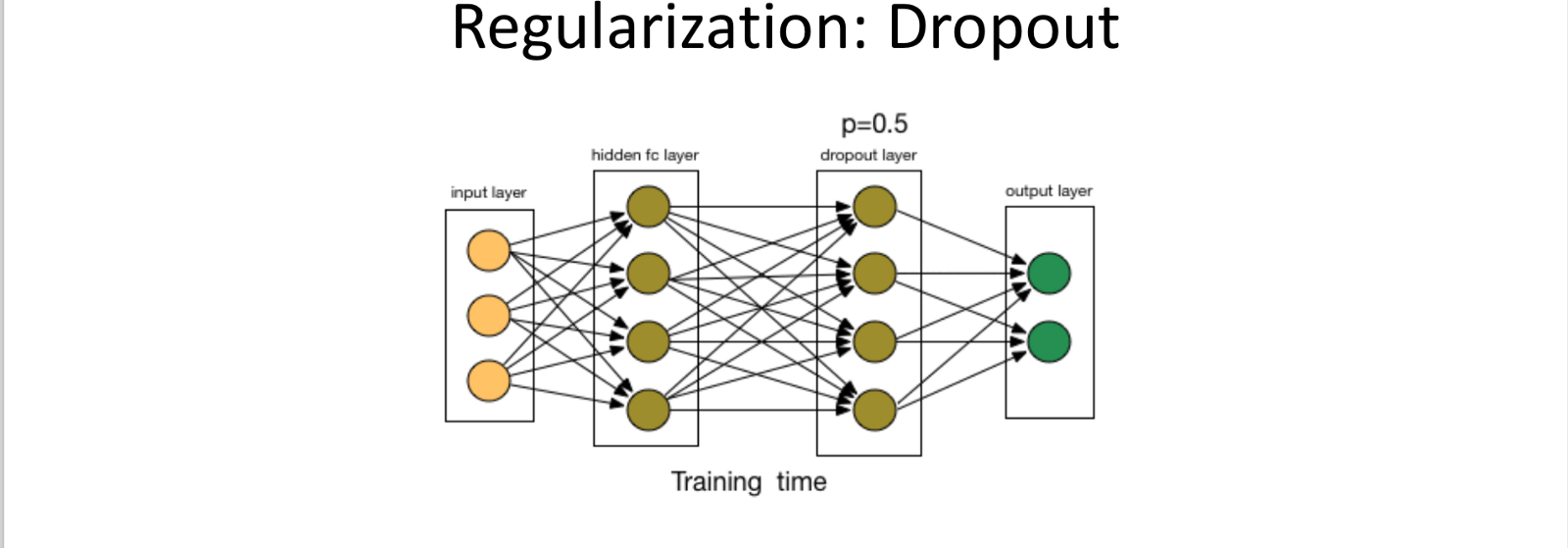
Dropout: Randomly Remove some of the nodes (along with the incoming and outgoing nodes)
- Denoted by Probability of keeping a node (p)
- Input Node p should be much higher.
Goal: To help generalise better.
Regularization Weight Penalty:
- L2 Penalty: Penalised squared weights:
- Keeps smaller weights unless error derivative is high.
- Prevents from fitting sampling error.
- Smoother Model.
- For 2 similar inputs, the weight gets distributed.
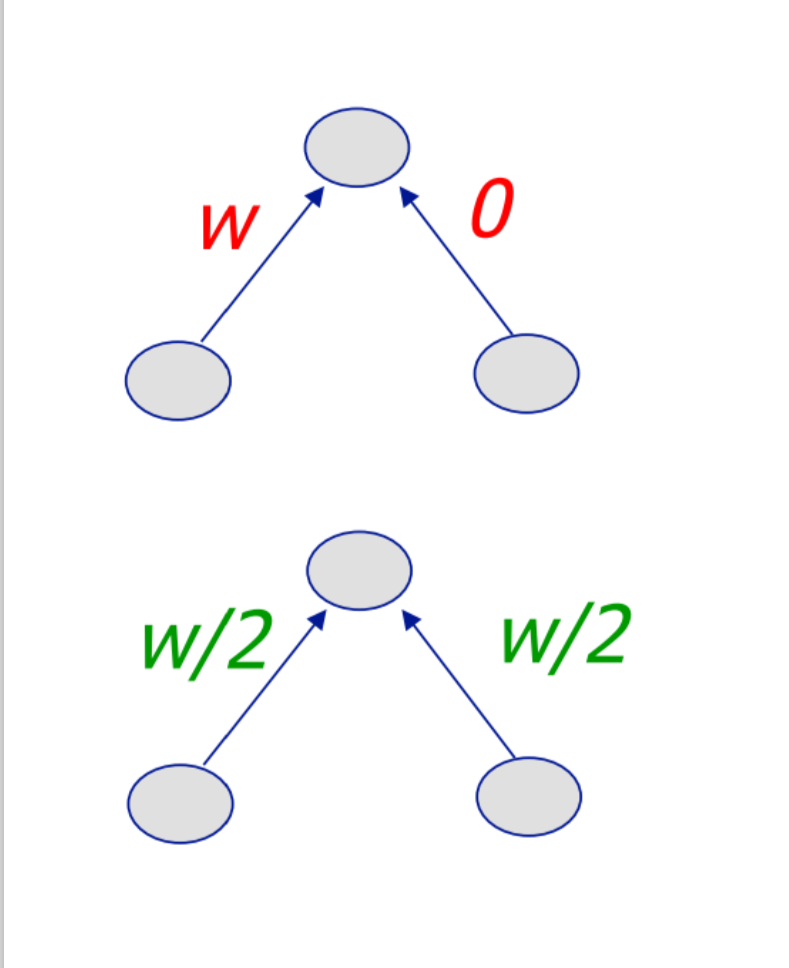
- L1 Penalty: Penalise absolute weight:
- Allows weights to remain large.
Neural Network Playground: To play around with techniques and practise
Deep Learning Breakthroughs
What Changed?
- Compute Power increased.
- Large Organised Datasets available.
- Algorithms and Research in GPU Utilization.
- Software and Infrastructure.
- Financial Backing.
DL is hard
Human Comparision:
- Human Vision: Devoloped 540,000,000 years of data.
- Bipedal Movement: 230,000,000 years of data.
- Abstract Thoughts: 100,000 years of data.
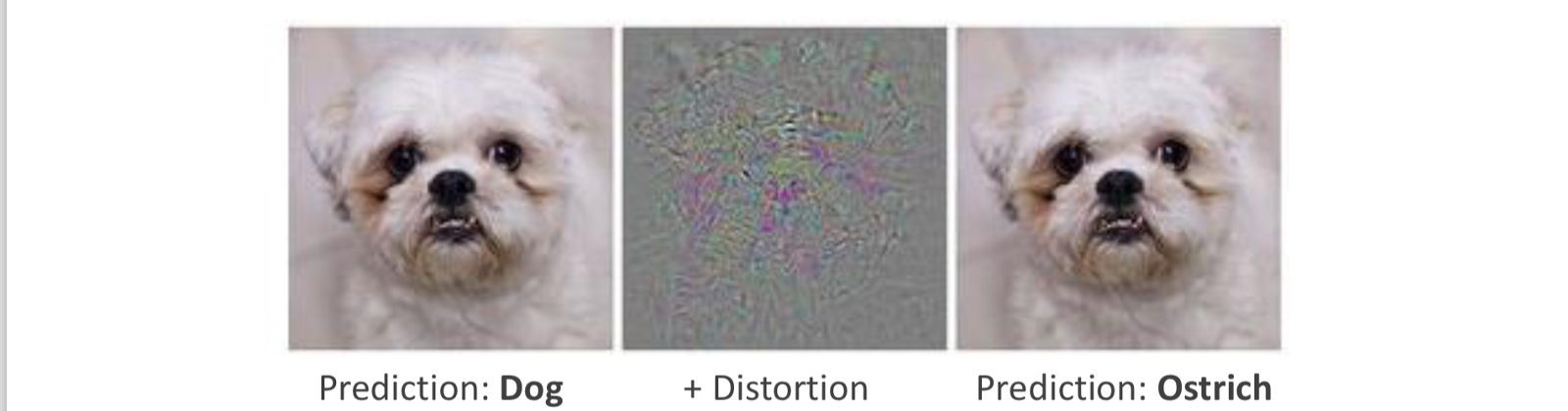
Neural Net:
- Add Distortion to pixel data, causes incorrect predictions.
- Vision Problems: Illuminabilty, Poses, Occlusions, Intra class variations.


Object Recognition/Classifcation:
Goal: Input an image and predict an output
ImageNet: 14M+ categories with 21.8k+ Categories
Competition: ILSVRC:
AlexNet (2012) made a significant jump in accuracy.
Resnet (2015): Human Level Performance was defeated.
Subtle example: DL is still distant from ‘Human Generalisation Ability’
Same Architecture, Many Applications: We can change the predict layer to make predictions to as many number of classes as per requirements.
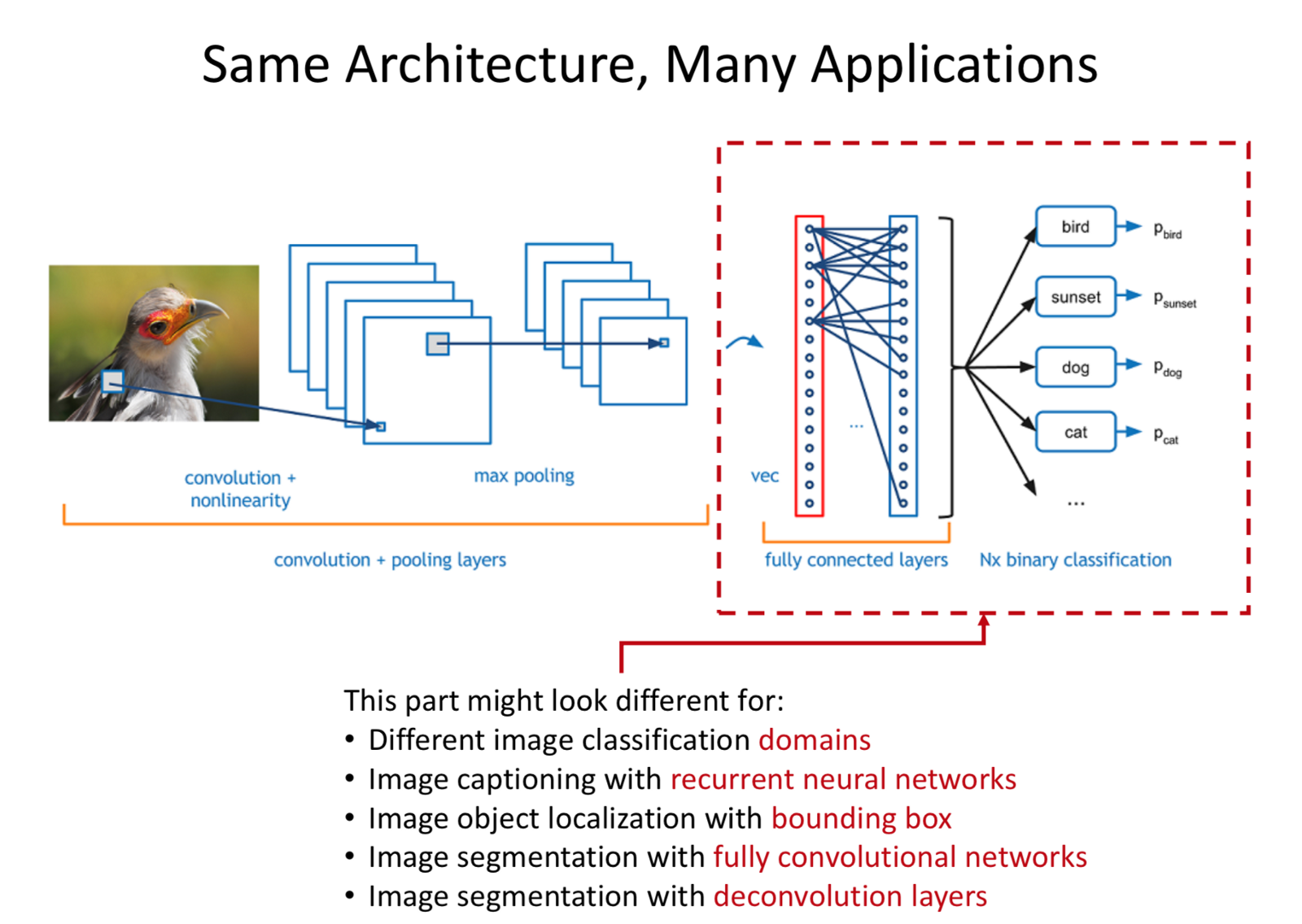
- Image Classification.
- Image Captioning.
- Object Localisation.
- Image Segmentation.
FCNN:
Every pixel is assigned a class and it inputs an image and produces another image as output.
Goal: Image to Image Mapping.
Use-Cases:
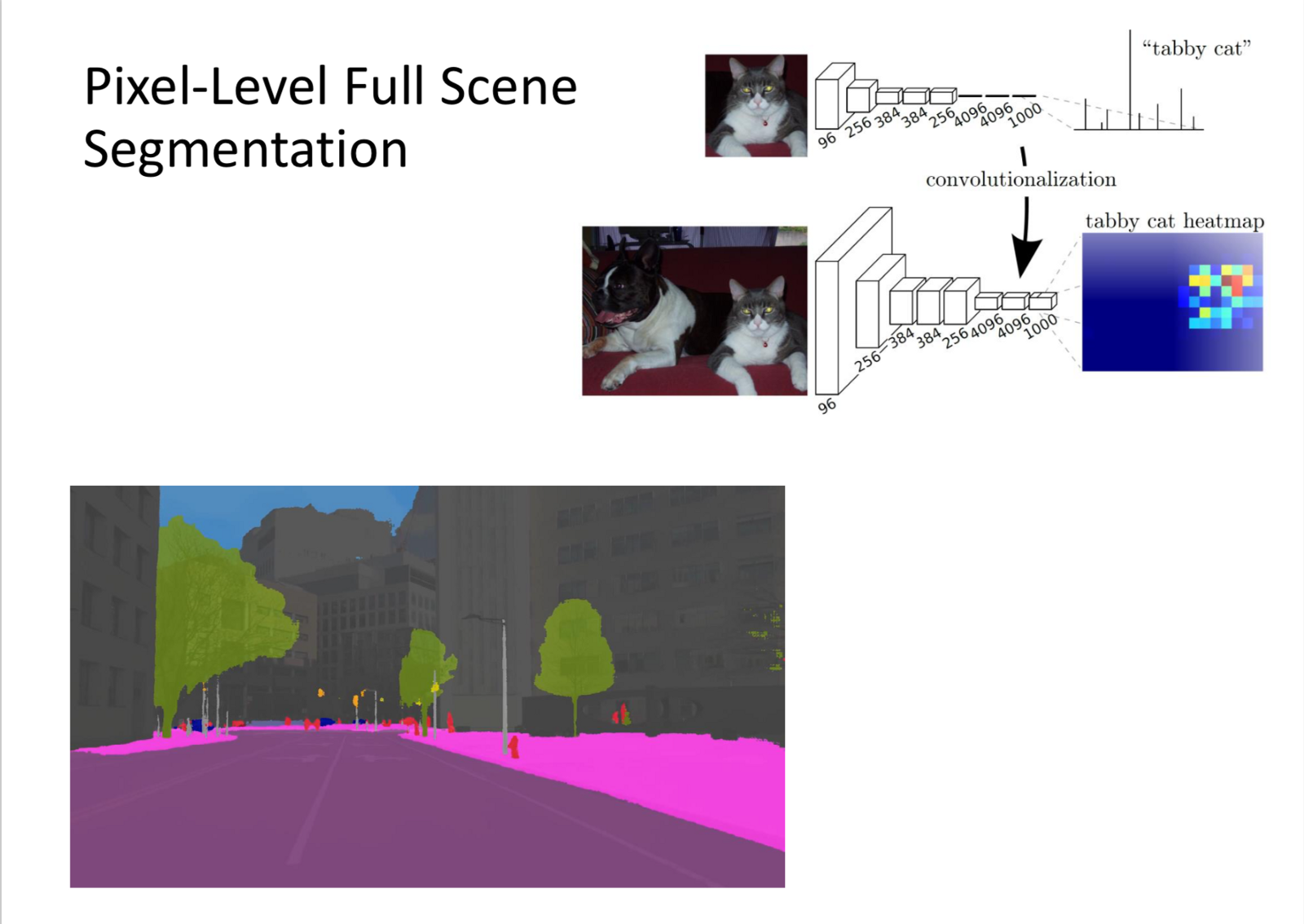
- Pixel-Level Full Scene Segmentation.

- Colorisation Mapping.
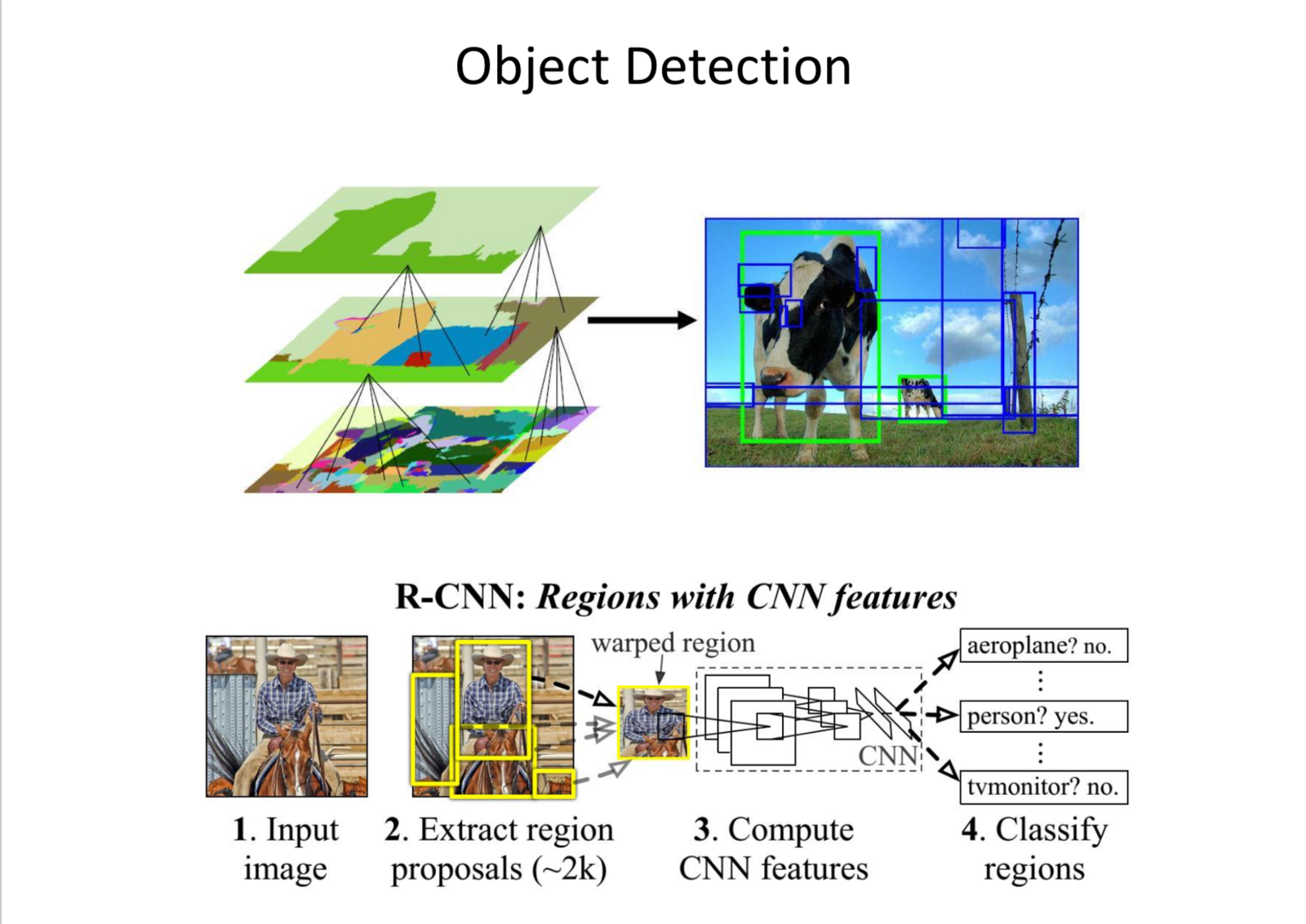
- Object Detection.
- Background Removal.
- Pix2PixHD: Generate High Res Photo Realistic images from semantic label maps.
- RNN: Work with Sequences
Use-Cases:
- Handwriting Generation
- Image Caption Generation.
- Video Description Generation.
- Modeling Attention Steering.
- Drawing with Selective Attention.
Major Break Throughs
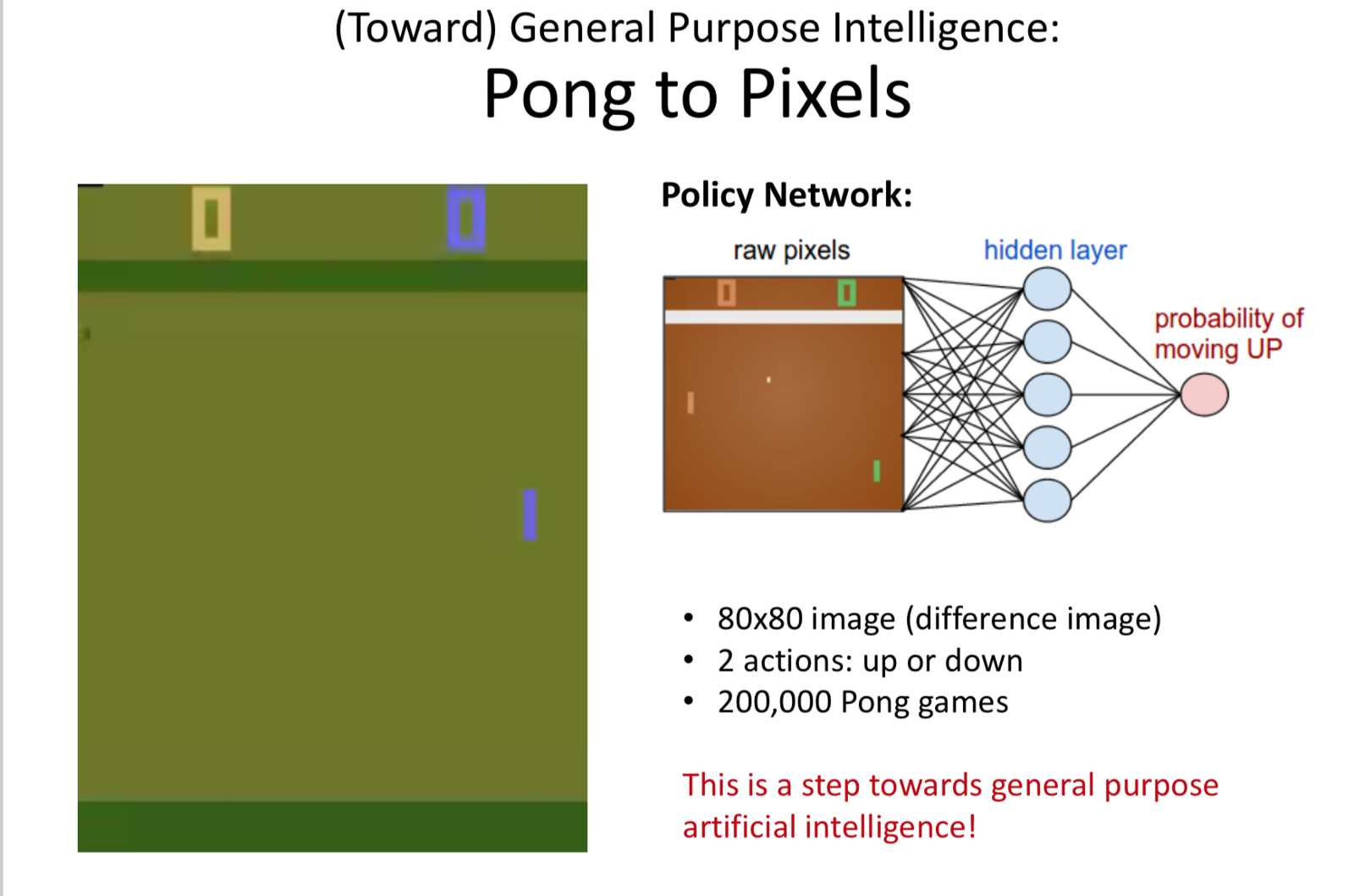
- Pong to Pong (2012): A step towards AGI.
- AlphaGo (2016): Learned from Human Expert Games
- AlphaGo Zero (2017): Beat AlphaGo and Co and it was trained without any Data! (It learned by practising against itself).
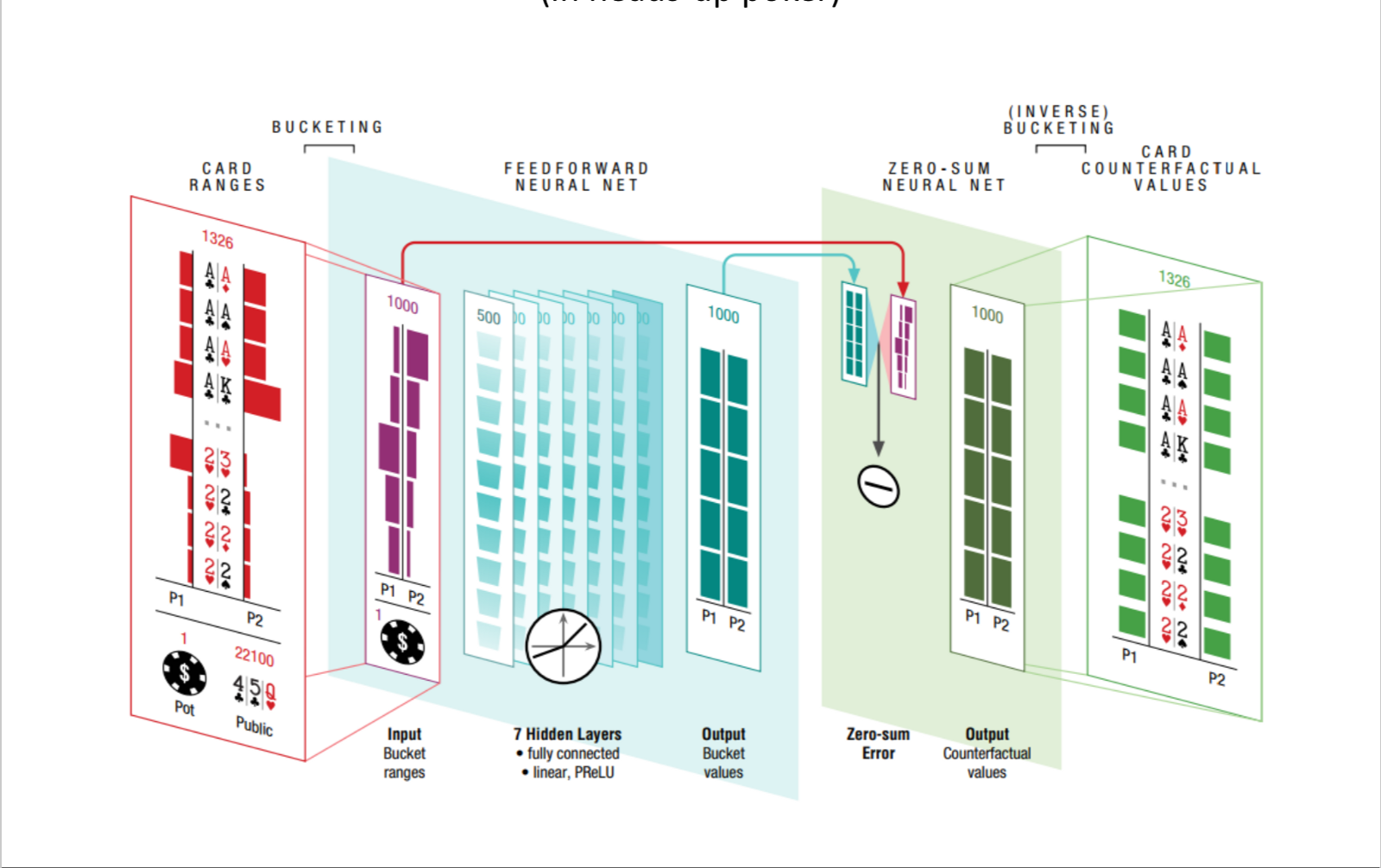
- DeepStack (2017): First to beat Professional Poker Players (in Heads up Poker)
Current Drawbacks
- Defining good Reward Function is difficult. (Coast Runner Examples), The outcomes can be surprising.
- Lack of Robustness: Adding noise to Pixels cause wrong predictions.
Current Challenges:
- Transfer Learning: Works well with domains closely related. Challenge: Cross-Domain Transfer learning is missing. Reason: Understanding of reasonsing or ability to derive understanding
- Huge Amount of data needed.
- Annotated Data is required.
- Not fully automated: Hyperparameter tuning
- Reward: Defining a good reward function is difficult.
- Transparency: NN are mostly blackboxes (even after we visualise the under the hood processes).
- Edge cases: DL is not good at dealing with edge cases. (Specially when it comes to Autonomous driving).
Re: Why DL?
It’s an oppurtunity to apply techniques to real world problems effectively. (And DL is the most effective at these).
You can find me on Twitter @bhutanisanyam1, connect with me on Linkedin hereHere and Here are two articles on my Learning Path to Self Driving Cars
Subscribe to my Newsletter for a Weekly curated list of Deep learning, Computer Vision Articles
[story continues]
tags