
Why I care about cross-linguality (not just multilinguality)
Most LLM papers and many leaderboards lean on datasets originally constructed in English, and then translated into other languages. That offers convenience, but hides any cultural data present in texts. Languages encode idioms, local history, norms, and references that are not faithfully preserved by translation.
So I asked a stricter question:
If a model is truly cross-lingual, can it reason across languages and answer in the requested language when the knowledge itself is rooted in a different local culture?
To test that, I prioritized natively composed resources: KazMMLU (Kazakh), BertaQA (Basque), and BLEnD (under-represented languages with annotator metadata). I removed high‑resource subsets, harmonized schemas, translated from the source language to English when needed for the experimental conditions, and ended up with 5894 items for multiple-choice question answering (MCQA) and 7158 for short‑form question answering (SFQA) across 11 languages, all under ~1% of Common Crawl content.
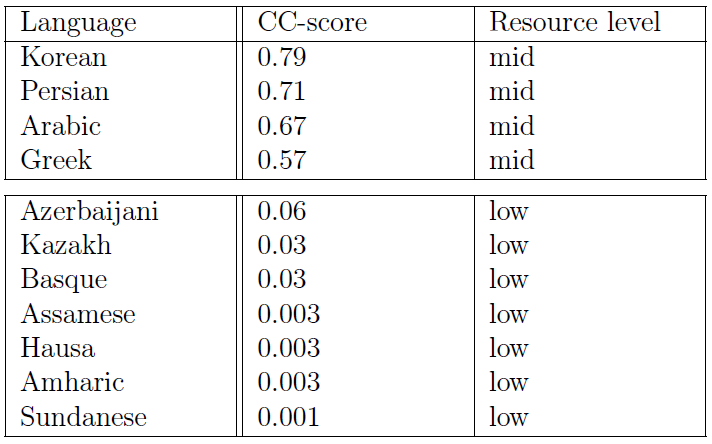
What I actually built
1) Culturally intact datasets
- All datasets were compiled in their respective languages, so any translation I performed was done only into English, and only when these versions were missing. This ensures the cultural data does not get corrupted.
- I used BertaQA’s "Euskal gaiak" subset (Basque culture) and BLEnD’s annotator flags ("idk", "not applicable", etc.) to prune irrelevant and low‑confidence items.
- Unified schema. I developed a schema for the two types of tasks: MCQA -
{question, options A–E, ground_truth, question_language, answer_language}; SFQA -{question, ground_truth, question_language, answer_language}.

2) Prompts that push models to reason
I used zero‑shot chain‑of‑thought for both MCQA and SFQA. I experimented with providing the models examples of the task in a few‑shot format, and while that did help some models, it also hurt others' performance, so I ultimately decided against it. Zero‑shot CoT was the most stable baseline across languages and sizes.
3) Reliable extraction
Large language models don’t always obey a simple "put the final answer in brackets". To ensure this behaviour, I paired a regex pass with an LLM extractor module as a fallback to reach near‑perfect extraction without humans.
In production, an easier solution to this would be utilizing structured output - passing a defined schema to the model and ensuring it produces the output in that format specifically.
Here, this method was not ideal as the work involved querying many open-source, smaller LLMs, which do not support such functionality.
4) A metric that checks what you say and in which language
The formula for the metric I used is defined as follows:
LASS = β · SemanticSimilarity + (1 - β) · LanguageMatch
- SemanticSimilarity is computed using LaBSE cosine similarity (language‑agnostic sentence space).
- LanguageMatch is a fastText language ID check: 1 if the answer is in the requested language, else 0.
- I set β = 0.8, since correctness matters most, but if the answer is in the requested language, the response is still awarded some points.
The reason I did not stop at measuring just BLEU or Exact Match is that cross‑lingual short answers are often paraphrases or inflections. Thus, metrics that account for surface overlap do not reliably pick up on this hidden meaning. The metric I introduced - LASS - rewards meaning and respects the linguistic constraint.
The models I evaluated
I compared 11 contemporary LLMs, mixing sizes (7–9B, 24–32B, ≥70B), families (Llama/Mistral/Qwen/DeepSeek/GPT), and openness (open weights vs closed APIs). Some marketed themselves as explicitly "multilingual".
Here is the full list of models I compared:
- DeepSeek R1 (distill-llama-70B)
- GPT 4.1
- GPT 4.1 mini
- GPT o4 mini
- Llama 3 (70B)
- Llama 3 (8B)
- Qwen QwQ (32B)
- Mistral Saba (24B)
- Babel (9B)
- Aya Expanse (8B)
- Pangea (7B)
What stood out in the results
1) Scale helps, but with diminishing returns
Averaged by class, the LASS score is:
- Large (≥70B) ~69.4%
- Medium (24–32B) ~62.8%
- Small (≤9B) ~57%
The jump from medium to large increases the metric by ~7 percentage points. This is undoubtedly an increase, but keep in mind - the models from the two size categories differ by 40B+ parameters. More parameters doesn't seem to be a silver bullet for cross‑lingual reasoning grounded in culture.
2) Reasoning is a force multiplier
A 32B reasoning‑oriented model beat a 70B non‑reasoning model. Across the board, reasoning models (distilled from larger teachers or trained with reasoning traces) outperformed non‑reasoning peers by ~10 points on average. In cross‑lingual settings, scaffolding the answer seems to matter as much as sheer scale.
3) Open models are close behind
The best open‑weight model trailed the best closed‑weight by ~7% on my benchmark, which is close enough that targeted finetunes or better instruction data could plausibly close the gap.
4) "Multilingual" ≠ "truly cross‑lingual"
Models marketed for broad language coverage underperformed when the tasks were culturally specific and evaluated cross‑lingually. My explanation for this points to the same dataset issues - both training, and evaluation datasets were English‑sourced and translated. When making an effort to keep culturally specific data intact, and checking both semantics and language identity, many models perform surprisingly worse.
Why the findings matter
- If your user base spans mid/low‑resource languages, don’t assume "multilingual" marketing translates to high-quality cross‑linguality. You should always test with native content and enforce answer‑language constraints. This prevents surprises like your chatbot replying in the wrong language with the right idea, or vice versa.
- In developing and evaluating new multilingual and cross-lingual large language models, it is best to avoid translated‑from‑English benchmarks. If cultural data is not preserved, the resulting model may not perform as well as it could have.
- Investing in reasoning alignment can beat adding tens of billions of parameters for these kinds of tasks.
- When performing multilingual and cross-lingual evaluations, use both a semantic metric and a language‑identity factor. This is cheap to run and produces results closer to human judgment for cross‑lingual short answers.
What I would improve next
- In a few cases (e.g., Basque, Kazakh), the Exact Match and LASS metrics diverged. Two metrics were used to cover both multiple-choice and short-form QA tasks, but ideally, there should be one harmonized, language‑aware metric across all tasks.
- Cosine similarity can potentially over‑reward near paraphrases that flip polarity. For future work, it is best to calibrate with negation‑aware checks and make the language penalty probabilistic.
- This work covered only 11 languages, so there is a lot of room to expand. It would be especially interesting and meaningful to cover languages from typologically distant families to those already represented in the final datasets.
- I focused on knowledge and generation, but societal bias is equally important to test and probe.
Reproducibility
All code and data used in the work can be found in this GitHub repository (evaluation scripts, prompts, extraction rules, metric code, parquet datasets, and model configs).
Direct links to the original datasets: KazMMLU, BertaQA, BLEnD.
I welcome critique and expansions on my work. If you can improve my code, prompt templates, or the LASS β‑weighting for a given language family, please open an issue or PR in the GitHub repository linked in the article.
[story continues]
tags