Table of Links
-
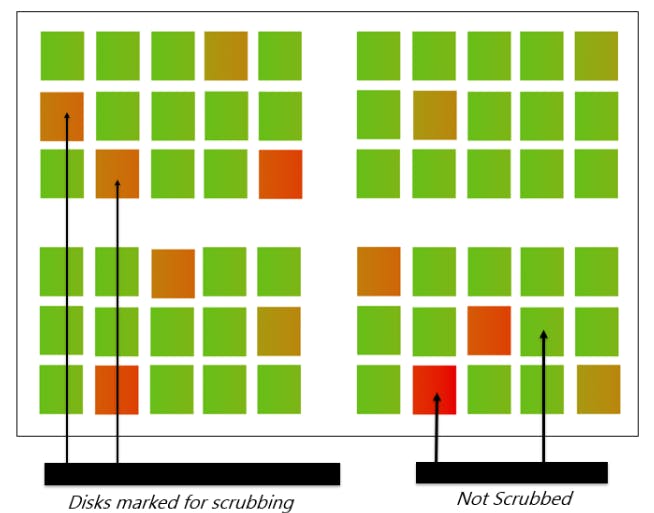
Mondrian conformal prediction for Disk Scrubbing: our approach
5.1. System and Storage statistics
-
7.1. Optimal scheduling aspect
7.2. Performance metrics and 7.3. Power saving from selective scrubbing
Abstract
Disk scrubbing is a process aimed at resolving read errors on disks by reading data from the disk. However, scrubbing the entire storage array at once can adversely impact system performance, particularly during periods of high input/output operations. Additionally, the continuous reading of data from disks when scrubbing can result in wear and tear, especially on larger capacity disks, due to the significant time and energy consumption involved. To address these issues, we propose a selective disk scrubbing method that enhances the overall reliability and power efficiency in data centers. Our method employs a Machine Learning model based on Mondrian Conformal prediction to identify specific disks for scrubbing, by proactively predicting the health status of each disk in the storage pool, forecasting n-days in advance, and using an open-source dataset. For disks predicted as non-healthy, we mark them for replacement without further action. For healthy drives, we create a set and quantify their relative health across the entire storage pool based on the predictor’s confidence. This enables us to prioritize selective scrubbing for drives with established scrubbing frequency based on the scrub cycle. The method we propose provides an efficient and dependable solution for managing enterprise disk drives. By scrubbing just 22.7% of the total storage disks, we can achieve optimized energy consumption and reduce the carbon footprint of the data center.
1. Introduction
A large-scale data center is a complex ecosystem primarily consisting of various types of storage devices, such as hard disk drives (HDD), solid-state drives (SSD), and hybrid storage devices, spread over multiple geographic locations. As the number of storage components grows in the storage ecosystem, it becomes increasingly difficult to manage its business continuity (Bajgori´c et al., 2022) because of the underlying complexity and uncertainty associated with each individual component’s internal working mechanics. For instance, a data center can have a mixed workload of transactional databases, network-attached storage (NAS), and archival storage. Each workload has its unique characteristics and impact on the reliability and remaining useful life of the storage system. Inadequate management of these storage components can result in data loss and eventually business disruption (Pinheiro et al., 2007). Monitoring the health of storage components is a common proactive approach to maintaining the reliability of storage systems. This is typically achieved through system logs and SMART logs of HDDs and SSDs (Zhang et al., 2023).
In the context of data centers, many device manufacturers and vendors (Ma et al., 2015; Vishwakarma and Perneti, 2021) utilize drive failure analysis as a metric to assess the overall reliability of the data center. Drive failure analysis typically categorizes failures into two types: complete failure and latent failure of the disk drive. Complete failure is relatively easy to detect and enables a transparent approach for replacing failed disks. However, latent failure is nearly undetectable and can lead to sudden failure and loss of critical data (Bairavasundaram et al., 2007; Schroeder et al., 2010).
Traditional system-level approaches, such as storage virtualization technology like Redundant Array of Independent Disks (RAID), tend to focus on passive fault tolerance rather than proactive approaches. Alternatively, many statistical (Hamerly et al., 2001; Singh and Vishwakarma, 2023) and machine learning (Pitakrat et al., 2013; Sun et al., 2019) approaches have been explored to enhance the reliability of the storage system. Machine learning approaches, while powerful, face challenges when it comes to making accurate predictions on unseen data, as production data is subject to change over time (Lu et al., 2018), requiring continuous model updates. One argument to consider is that even a small false positive rate (FPR), such as 0.1%, can be a concern when implementing the model in real-world data centers that may have millions of disk drives. Instead of using drive failure analysis for reliability enhancement, an alternative approach could be to leverage disk drive scrubbing (Iliadis et al., 2008, 2011) in a more fine-grained manner to identify specific disks that require further attention.
Disk scrubbing is a process of performing full media pack sweeps across allocated and unallocated disks to detect and rebuild latent medium errors (Ryu and Park, 2009), reducing the chances of bad block media detection during host I/O activity. However, running scrubbing tasks for the entire disk population in an array can significantly increase the load on the data storage system, potentially degrading its performance. Additionally, if the disk has a larger capacity (e.g., 12TB), it will take a considerable amount of time to complete the operation.
Our proposed method aims to optimize disk scrubbing by selectively targeting only the disks that require the operation. We use a learning framework based on Mondrian conformal prediction, which is agnostic to the specific machine learning algorithm, to identify specific disks for scrubbing. The method involves forecasting the health of a disk n-days ahead through binary classification. A set of healthy drives is created, and the health status of the entire storage pool is quantified based on the predictor’s confidence. Drives marked as unhealthy are then sent for treatment based on the administrator’s decision. The metrics obtained from Mondrian conformal prediction are used to prioritize selective scrubbing for the drives. This proposed method has two main advantages: first, it leverages the underlying drive failure analysis, and second, the quantified output from the forecast engine can be used as input for the disk scrubbing scheduler engine, optimizing the scrubbing process and enhancing reliability in the data center environment. A summary of our contributions is as below:
• Introducing a fine-grained approach for identifying disk drives to be scrubbed by complementing the existing failure analysis engine on the storage sub-system with an algorithm-agnostic framework based on Mondrian conformal prediction.
• Translating the output of the framework, i.e. the confidence of prediction for new data points, into a ranking mechanism that sorts the healthy drives in descending order for further treatment by the decision engine.
• Implementing a scrubbing frequency schedule for the entire storage array based on n-step ahead system load prediction using probabilistic weighted fuzzy time series, which is mapped to the scrubbing engine for optimized disk scrubbing.
The method contributes to a proactive approach that provides value for business continuity, such as resource and power savings in data centers during data scrubbing by selectively spinning disks down. This means that only the required disks are scrubbed on a priority basis, while the healthy disks can be scrubbed less frequently or not at all. This optimized approach helps improve operational efficiency and reduces unnecessary disk wear, resulting in potential cost savings and enhanced reliability for the data storage system.
This paper is structured as follows: section 2 provides the motivation for our work and outline the design considerations. In section 3, we present a review of related work in the field. We provide a definition and algorithmic overview of conformal prediction in section 4. In section 5, we deliver a synopsis of our proposed solution, followed by the presentation of experimental results in section 6. The usability and interpretation of disk drive health metrics are discussed in section 7, and we conclude with section 8, summarizing our findings.
This paper is available on arxiv under CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) license.
Authors:
(1) Rahul Vishwakarma, California State University Long Beach, 1250 Bellflower Blvd, Long Beach, CA 90840, United States (rahuldeo.vishwakarma01@student.csullb.edu);
(2) Jinha Hwang, California State University Long Beach, 1250 Bellflower Blvd, Long Beach, CA 90840, United States (jinha.hwang01@student.csulb.edu);
(3) Soundouss Messoudi, HEUDIASYC - UMR CNRS 7253, Universit´e de Technologie de Compiegne, 57 avenue de Landshut, 60203 Compiegne Cedex - France (soundouss.messoudi@hds.utc.fr);
(4) Ava Hedayatipour, California State University Long Beach, 1250 Bellflower Blvd, Long Beach, CA 90840, United States (ava.hedayatipour@csulb.edu).