Table of Links
3.2 Measuring Learning with Coding and Math Benchmarks (target domain evaluation)
3.3 Forgetting Metrics (source domain evaluation)
4 Results
4.1 LoRA underperforms full finetuning in programming and math tasks
4.2 LoRA forgets less than full finetuning
4.3 The Learning-Forgetting Tradeoff
4.4 LoRA’s regularization properties
4.5 Full finetuning on code and math does not learn low-rank perturbations
4.6 Practical takeaways for optimally configuring LoRA
Appendix
D. Theoretical Memory Efficiency Gains with LoRA for Single and Multi-GPU Settings
4.2 LoRA forgets less than full finetuning
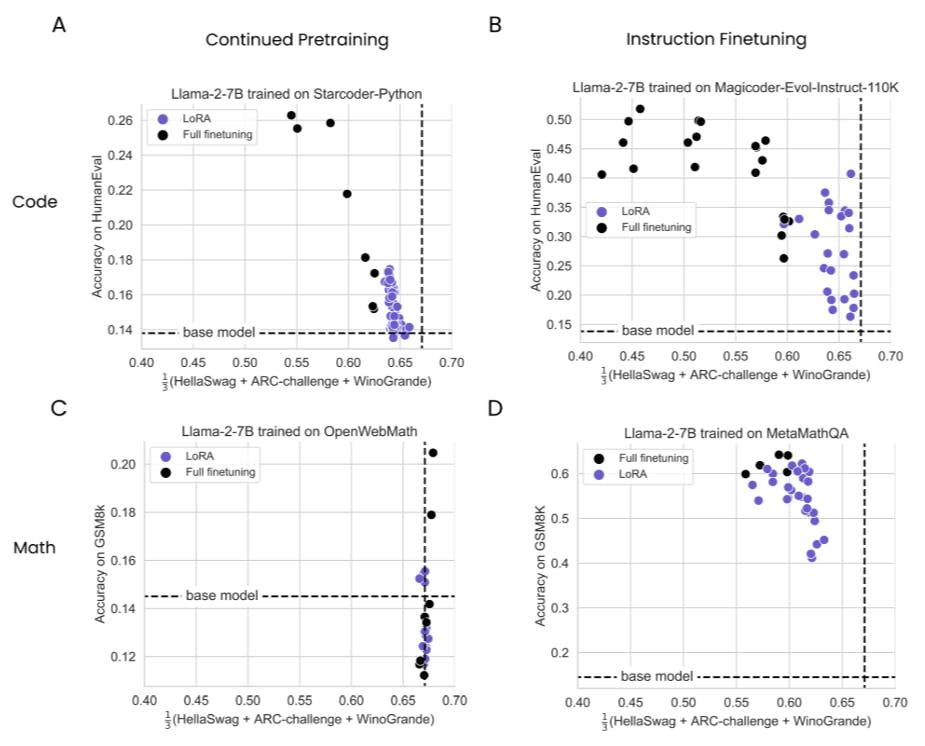
We define forgetting as the degradation in the average of HellaSwag, ARC-challenge, and WinoGrande benchmarks, and investigate its extent as a function of data in Fig. 3.
Overall, we observe that (1) IFT induces more forgetting than than CPT, (2) programming induces more forgetting than math, and (3) forgetting tends to increase with data. Most importantly, LoRA forgets less than full finetuning, and as in 4.1, the effects are more pronounced for the programming domain. In code CPT, LoRA’s forgetting curve is roughly constant, whereas full finetuning degrades with more data (the forgetting metric at peak HumanEval: Full finetuning=0.54 at 20B tokens, LoRA=0.64 at 16B tokens). In programming IFT, both methods degrade when trained for more epochs, and at their peak performance (4 and 8 epochs), LoRA scores 0.63 and full finetuning scores 0.45. For math, there are no clear trends on the OpenWebMath CPT dataset, except that both LoRA and full finetuning exhibit no forgetting. This is likely due to the fact that the OpenWebMath dataset is dominated by English sentences, unlike the StarCoder-Python dataset which is majority Python code (see 3.1 for details). In math IFT, LoRA again forgets less than full finetuning (0.63 versus 0.57, repectively, at epoch 4).
Authors:
(1) Dan Biderman, Columbia University and Databricks Mosaic AI (db3236@columbia.edu);
(2) Jose Gonzalez Ortiz, Databricks Mosaic AI (j.gonzalez@databricks.com);
(3) Jacob Portes, Databricks Mosaic AI (jportes@databricks.com);
(4) Mansheej Paul, Databricks Mosaic AI (mansheej.paul@databricks.com);
(5) Philip Greengard, Columbia University (pg2118@columbia.edu);
(6) Connor Jennings, Databricks Mosaic AI (connor.jennings@databricks.com);
(7) Daniel King, Databricks Mosaic AI (daniel.king@databricks.com);
(8) Sam Havens, Databricks Mosaic AI (sam.havens@databricks.com);
(9) Vitaliy Chiley, Databricks Mosaic AI (vitaliy.chiley@databricks.com);
(10) Jonathan Frankle, Databricks Mosaic AI (jfrankle@databricks.com);
(11) Cody Blakeney, Databricks Mosaic AI (cody.blakeney);
(12) John P. Cunningham, Columbia University (jpc2181@columbia.edu).
This paper is