TL;DR —
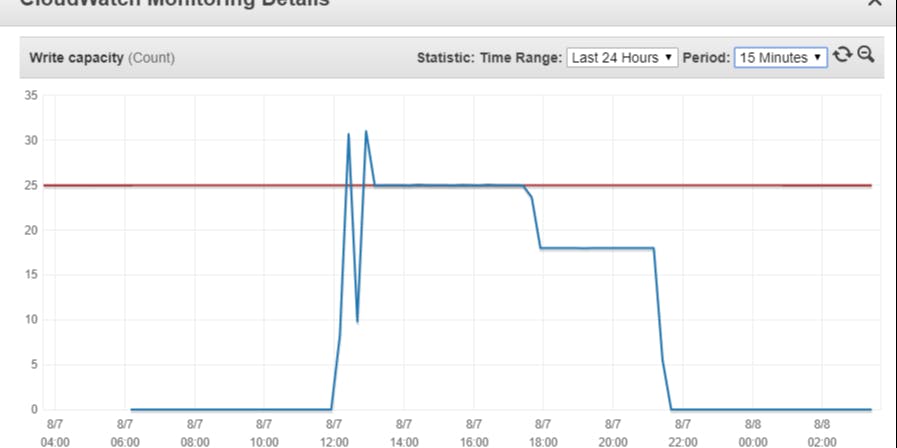
AWS data pipelines are one of the best mechanisms to transfer data from one storage to another storage with a different data type. While transferring data from pipelines, there are several techniques which can be used to optimize the process of copying data. In this article, the scenario would be copying 3 CSV format files which are stored in S3 bucket, to 3 Dynamodb tables. The performance is not up to what is expected. Even though we added an m4.large instance type as the EMR cluster, performance is lagging.
[story continues]
Written by
@lakindu
Software Engineer
Topics and
tags
tags
pipeline|aws|performance|dynamodb|s3|latest-tech-stories|software-development|programming
This story on HackerNoon has a decentralized backup on Sia.
Transaction ID: MFph3yKb4GfNlV2iJXbk7TjmfQ30bBnu313iJtl9Nf0