Authors:
(1) Vladislav Trifonov, Skoltech (vladislav.trifonov@skoltech.ru);
(2) Alexander Rudikov, AIRI, Skoltech;
(3) Oleg Iliev, Fraunhofer ITWM;
(4) Ivan Oseledets, AIRI, Skoltech;
(5) Ekaterina Muravleva, Skoltech.
Table of Links
2 Neural design of preconditioner
3 Learn correction for ILU and 3.1 Graph neural network with preserving sparsity pattern
5.1 Experiment environment and 5.2 Comparison with classical preconditioners
5.4 Generalization to different grids and datasets
7 Conclusion and further work, and References
6 Related work
In this section, we discuss the most important research on learning-based preconditioners that helped us to properly organise our work. While there is a dozen of different preconditioners in linear algebra, for example Saad [2003], Axelsson [1996]: block Jacobi preconditioner, Gauss-Seidel preconditioner, sparse approximate inverse preconditioner, algebraic multigrid methods, etc. The choice of preconditioner depends on the specific problem and practitioners often rely on a combination of theoretical understanding and numerical experimentation to select the most effective preconditioner. Even a brief description of all of them is beyond the scope of a single research paper. One can refer to related literature for more details.
The authors of Li et al. [2023] present a novel approach to preconditioner design using GNN and a new loss function that incorporates inductive bias from PDE data distributions. This learning-based method aims to approximate the matrix factorization and use it as a preconditioner, exploiting the common sparsity pattern between the left-hand side A and the output of GNN. The proposed approach is shown to be more efficient than classical linear algebra preconditioners when their pre-computation time is much higher than GNN inference.
The recent FCG-NO Rudikov et al. [2024] approach to solving linear systems of PDEs by combining neural operators with the conjugate gradient method acts as a nonlinear preconditioner for the flexible conjugate gradient method. This approach exploits the strengths of both neural networks and the FCG method to create a computationally efficient, data-driven approach. The authors use the FCG with a proven convergence bound for a nonlinear preconditioner and use it as a training loss.
A paper Kopanicáková and Karniadakis [2024] introduces a novel class of hybrid preconditioners ˇ for solving parametric linear systems of equations by combining DeepONet with standard iterative methods. The proposed framework consists of two approaches: direct preconditioning (DP) and trunk basis (TB), which use DeepONet to address low-frequency error components and conventional iterative methods to mitigate high-frequency error components.
The in Zhang et al. [2022] proposed HINTS method combines traditional relaxation methods with the Deep Operator Network (DeepONet) to solve differential equations more efficiently and accurately. It targets different regions of the spectrum, ensuring a uniform convergence rate and exceptional performance. Authors reported that HINTS is fast, accurate and applicable to various differential equations, domains, discretizations and can be transferred to different discretizations.
7 Conclusion and further work
We proposed a novel learnable approach for preconditioner construction – PreCorrector. PreCorrector successfully demonstrated the potential of neural networks in the construction of effective preconditioners for solving linear systems, that can outperform classical numerical preconditioners. By learning the corrections to classical preconditioners, we developed a novel approach that combines the strengths of traditional preconditioning techniques with the flexibility of neural networks. We suggest that there exists a learnable transformation that will be universal for different sparse matrices for construction of ILU decomposition that will significantly reduce κ(A).
Our observation about approximation of low-frequency components in the used loss function lacks theoretical analysis. Moreover we did not found any traces of the seeking relationship in the specialized literature. We suppose that this loss analysis is the key ingredient for successful learning general form transformation.
We also suggested a complexity metric for our dataset and showed superiority of the PreCorrector approach over classical preconditioners of ILU class on complex datasets.
Further work may be summarized as follows:
• Theoretical investigation of the used loss function.
• Analysis of possible variations of the target objective in other norms.
• Generalization of the PreCorrector to transformation in the space of sparse matrices with general sparsity pattern.
References
Yousef Saad. Iterative methods for sparse linear systems. SIAM, 2003.
Alexander Rudikov, Vladimir Fanaskov, Ekaterina Muravleva, Yuri M Laevsky, and Ivan Oseledets. Neural operators meet conjugate gradients: The fcg-no method for efficient pde solving. arXiv preprint arXiv:2402.05598, 2024.
Maksym Shpakovych. Neural network preconditioning of large linear systems. PhD thesis, Inria Centre at the University of Bordeaux, 2023.
Alena Kopanicáková and George Em Karniadakis. Deeponet based preconditioning strategies for ˇ solving parametric linear systems of equations. arXiv preprint arXiv:2401.02016, 2024.
Chen Cui, Kai Jiang, Yun Liu, and Shi Shu. Fourier neural solver for large sparse linear algebraic systems. Mathematics, 10(21):4014, 2022.
Yichen Li, Peter Yichen Chen, Tao Du, and Wojciech Matusik. Learning preconditioners for conjugate gradient pde solvers. In International Conference on Machine Learning, pages 19425–19439. PMLR, 2023.
Paul Häusner, Ozan Öktem, and Jens Sjölund. Neural incomplete factorization: learning preconditioners for the conjugate gradient method. arXiv preprint arXiv:2305.16368, 2023.
Lloyd N Trefethen and David Bau. Numerical linear algebra. SIAM, 2022.
Michael F Hutchinson. A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines. Communications in Statistics-Simulation and Computation, 18(3):1059–1076, 1989.
Jie Zhou, Ganqu Cui, Shengding Hu, Zhengyan Zhang, Cheng Yang, Zhiyuan Liu, Lifeng Wang, Changcheng Li, and Maosong Sun. Graph neural networks: A review of methods and applications. AI open, 1:57–81, 2020.
Johannes Brandstetter, Daniel Worrall, and Max Welling. Message passing neural pde solvers. arXiv preprint arXiv:2202.03376, 2022.
EJ Carr and IW Turner. A semi-analytical solution for multilayer diffusion in a composite medium consisting of a large number of layers. Applied Mathematical Modelling, 40(15-16):7034–7050, 2016.
Michael L Oristaglio and Gerald W Hohmann. Diffusion of electromagnetic fields into a twodimensional earth: A finite-difference approach. Geophysics, 49(7):870–894, 1984.
Ekaterina A Muravleva, Dmitry Yu Derbyshev, Sergei A Boronin, and Andrei A Osiptsov. Multigrid pressure solver for 2d displacement problems in drilling, cementing, fracturing and eor. Journal of Petroleum Science and Engineering, 196:107918, 2021.
Jan Mayer. A multilevel crout ilu preconditioner with pivoting and row permutation. Numerical Linear Algebra with Applications, 14(10):771–789, 2007.
Owe Axelsson. Iterative solution methods. Cambridge university press, 1996.
Enrui Zhang, Adar Kahana, Eli Turkel, Rishikesh Ranade, Jay Pathak, and George Em Karniadakis. A hybrid iterative numerical transferable solver (hints) for pdes based on deep operator network and relaxation methods. arXiv preprint arXiv:2208.13273, 2022.
A Appendix
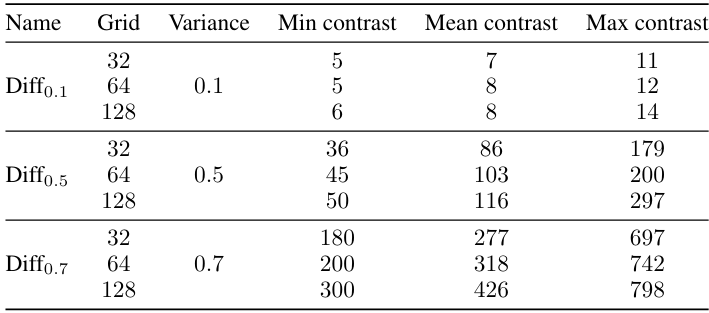
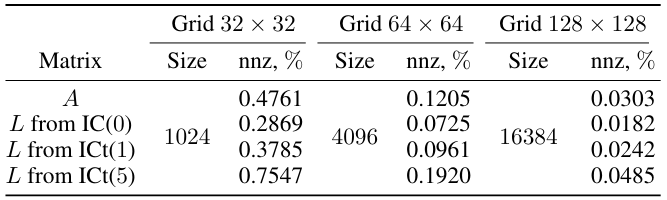
A.1 Details on training data
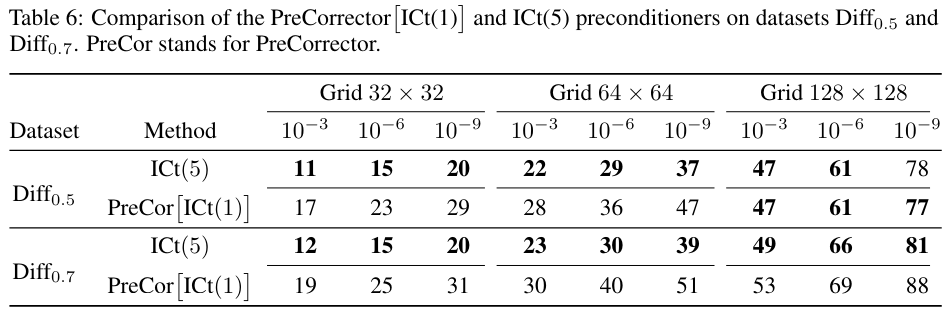
A.2 Additional experiments with ICt(5) preconditioner
A.3 Details about correction coefficient α
This paper is
[story continues]
tags