
In aviation, "breaking things" is not an option.
If a server crashes, you restart it. If a jet engine fails mid-flight, the consequences are catastrophic. This is why the aviation industry is shifting from Preventive Maintenance (replacing parts on a schedule whether they need it or not) to Predictive Maintenance (PdM) (replacing parts exactly before they break).
For Data Scientists, this is the ultimate Time Series regression problem. The goal is to calculate the Remaining Useful Life (RUL) of an engine based on sensor data (temperature, pressure, vibration).
Traditionally, this required complex physics models or manually tuned Deep Learning architectures (LSTMs). But recently, Automated Machine Learning (AutoML) has matured to the point where it can outperform manual tuning.
In this guide, based on analysis using the NASA C-MAPSS dataset, we will build a pipeline to predict engine failure using two open-source heavyweights: AWS AutoGluon and H2O.ai.
The PdM Pipeline
We aren't just classifying images here; we are dealing with multivariate time-series data. The pipeline requires transforming raw sensor logs into a regression target (RUL).
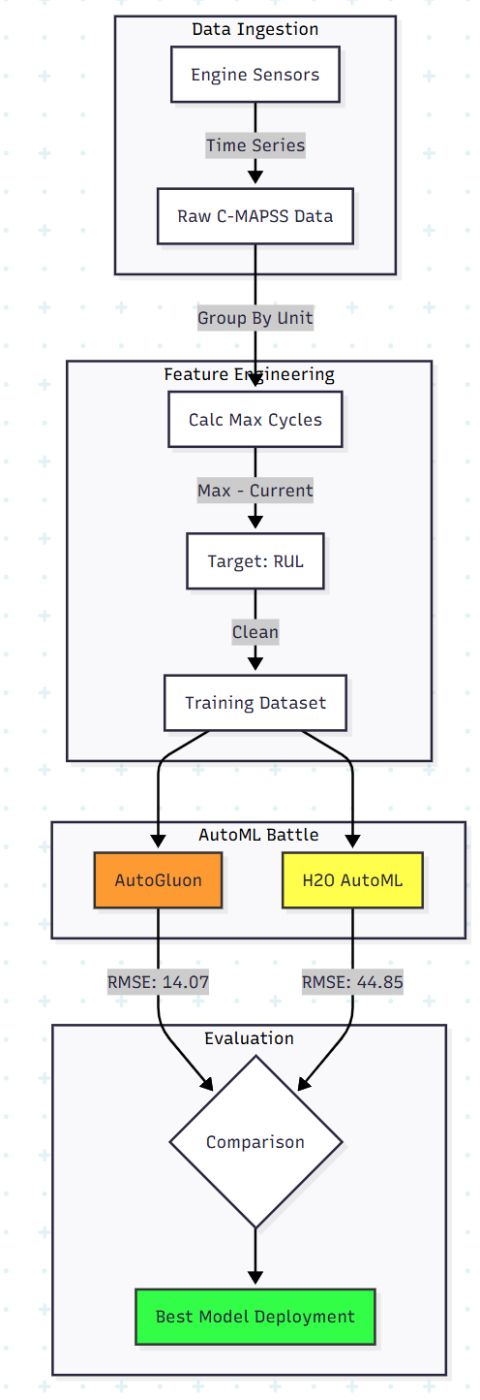
Phase 1: The Data (NASA C-MAPSS)
We are using the famous NASA Commercial Modular Aero-Propulsion System Simulation (C-MAPSS) dataset. It contains run-to-failure simulated data.
- Input: 21 Sensors (Total Temperature, Pressure at Fan Inlet, Core Speed, etc.).
- Target: Remaining Useful Life (RUL).
Calculating the RUL
The dataset doesn't explicitly give us the RUL; it gives us the current cycle. We have to calculate the target.
The Logic: RUL = Max_Cycle_of_Engine - Current_Cycle
import pandas as pd
# Load dataset (Simulated example structure)
# Columns: ['unit_number', 'time_in_cycles', 'sensor_1', ... 'sensor_21']
df = pd.read_csv('train_FD001.txt', sep=" ", header=None)
# 1. Calculate the maximum life of each engine unit
max_life = df.groupby('unit_number')['time_in_cycles'].max().reset_index()
max_life.columns = ['unit_number', 'max_life']
# 2. Merge back to original dataframe
df = df.merge(max_life, on='unit_number', how='left')
# 3. Calculate RUL (The Target Variable)
df['RUL'] = df['max_life'] - df['time_in_cycles']
# Drop columns we don't need for training (like max_life)
df = df.drop(columns=['max_life'])
print(df[['unit_number', 'time_in_cycles', 'RUL']].head())
Phase 2: The Metric (Why Accuracy is Wrong)
In predictive maintenance, simple "Accuracy" doesn't work. We need to measure how far off our prediction is.
We rely on RMSE (Root Mean Square Error).
- If the engine has 50 days left, and we predict 45, the error is 5.
- If we predict 100, the error is 50 (Huge penalty).
import numpy as np
def calculate_rmse(y_true, y_pred):
"""
y_true: The actual Remaining Useful Life
y_pred: The model's prediction
"""
mse = np.mean((y_true - y_pred)**2)
return np.sqrt(mse)
Note: The analysis also highlights RMSLE (Logarithmic Error). This is crucial because under-predicting life (predicting fail earlier) is safe, but over-predicting (predicting fail later than reality) is dangerous. RMSLE handles relative errors better across different scales.
Phase 3: The AutoML Showdown
We tested two frameworks to see which could handle the complex, noisy sensor data better without extensive manual tuning.
Contender 1: AutoGluon (The Winner)
AutoGluon (developed by AWS) uses a strategy of stacking and ensembling multiple models (Neural Nets, LightGBM, CatBoost) automatically.
The Code:
from autogluon.tabular import TabularPredictor
# AutoGluon handles feature engineering automatically
# 'RUL' is our target label calculated in Phase 1
predictor = TabularPredictor(label='RUL', eval_metric='root_mean_squared_error').fit(
train_data=df_train,
time_limit=600, # Train for 10 minutes
presets='best_quality'
)
# Inference
y_pred = predictor.predict(df_test)
results = predictor.evaluate(df_test)
print(f"AutoGluon RMSE: {results['root_mean_squared_error']}")
Contender 2: H2O AutoML
H2O is a veteran in the space, known for its scalable distributed computing capabilities.
The Code:
import h2o
from h2o.automl import H2OAutoML
h2o.init()
# Convert pandas df to H2O Frame
hf_train = h2o.H2OFrame(df_train)
hf_test = h2o.H2OFrame(df_test)
# Train
aml = H2OAutoML(max_models=20, seed=1)
aml.train(y='RUL', training_frame=hf_train)
# Inference
preds = aml.predict(hf_test)
perf = aml.leader.model_performance(hf_test)
print(f"H2O RMSE: {perf.rmse()}")
Phase 4: The Results
The analysis revealed a massive disparity in performance when applied to this specific sensor dataset.
|
Library |
Metric |
Target: RUL |
Result (Lower is Better) |
|---|---|---|---|
|
AutoGluon |
RMSE |
RUL |
14.07 |
|
H2O |
RMSE |
RUL |
44.85 |
**Analysis: \ AutoGluon outperformed H2O significantly (14.07 vs 44.85). In the context of jet engines, an error margin of 14 cycles is acceptable for scheduling maintenance. An error margin of 44 cycles renders the model useless.
Why did AutoGluon win?
- Stacking: AutoGluon excels at multi-layer stacking, combining the strengths of tree-based models and neural networks.
- Feature Handling: It handled the raw sensor noise better without requiring manual denoising steps.
Conclusion: Stop Tuning, Start Stacking
For industrial applications involving complex multivariate data, AutoML is no longer just a prototyping tool—it is a production capability.
By switching from manual model selection to an automated ensemble approach like AutoGluon, developers can reduce the engineering time from weeks to hours while achieving superior accuracy.
Key Takeaway for Developers: When building Industrial IoT apps, focus your effort on Phase 1 (Data Engineering) cleaning the sensor logs and calculating the correct RUL. Let the AutoML handle the model selection.
[story continues]
tags