
For a long time Java supported complex multi-threaded and concurrent capabilities, that allowed developers to effectively leverage multi-core CPUs architectures. This was done for a long time using construct called threads - more specifically under the hood these used Operating System (OS) threads a.k.a. platform threads. Application developer could create a thread to delegate a task to be executed in parallel to other thread, thus allowing to build scalable, asyncronous and performant application. Though the concurrency model in Java is powerful and flexible, it does come with difficulties, and relies heavily on the developers expertise and qualifications to write thread-safe code. These difficulties are primary due to the shared state concurrency model used by default by JVM. One has to resort to using syncronization techniques carefully to avoid the common concurrency pitfalls - deadlocks, livelocks, race conditions. A lot of research, blog posts, books have been written over the years to cover these topics, however for the longest time the underlying JDK implementation remained the same, until Project Loom revolutionised everything.
What is Project Loom?
Project Loom is to intended to explore, incubate and deliver Java VM features and APIs built on top of them for the purpose of supporting easy-to-use, high-throughput lightweight concurrency and new programming models on the Java platform
Project Loom is an OpenJDK initiative that aims to solve a very ambitious task - make concurrent in java easier and faster. This is done mainly by introducing Virtual Threads, vastly simplifying the thread per request application without relying on complex async/reactive libraries that introduce a new paradigm to projects. These lightweight entities reduce the overhead of thread management, allowing Java applications to handle significantly more concurrent operations efficiently.
Loom also explores a new API for Structured concurrency that treats a group of different tasks running in separate threads as single unit, vastly simplifying error handling and cancellation logic. Allows developers to write simple, blocking, synchronous code that's easier to read and debug, rather than complex reactive patterns, while still achieving high performance.
It is important to understand however that Loom does NOT aim to replace traditional threads, nor change the classic concurrency model. It does aim to enable server applications written in the simple thread-per-request style to scale with near-optimal hardware utilization.
Virtual Threads
As mentioned in the intro, there are 2 conceptually different thread types to understand here Platform thread and Virtual Thread. Platform threads run with the underlying OS threads, follow their full lifecycle and have a large allocated stack memory each - so they are expensive. Their number is limited and any concurrency book in java usually adreses this by advising the application developer to create new threads with care.
Virtual Threads also run in the OS thread, however they are not tied to OS threads lifecycle, and crutially whenever a virtual thread encounters a blocking I/O call (network call for example) the java runtime suspends the virtual thread and releases the OS thread to be used by other virtual threads. This effective decoupling of virtual threads from OS threads is the game changer.
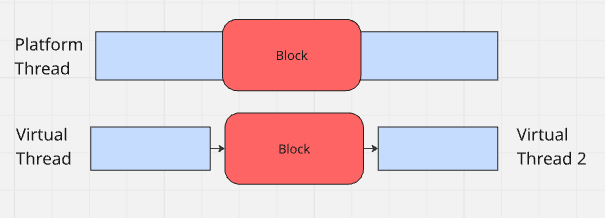
The shallow call stack of virtual threads suits them to perform few small operations - like calling an HTTP url once or running a single JDBC query. Thus, even though there is support for ThreadLocal variables and even InheritedThreadLocal variables, they should be used with care as a single JVM may support millions of virtual threads.
Virtual threads are suitable for running tasks that spend most of the time blocked, often waiting for I/O operations to complete. However, they aren't intended for long-running CPU-intensive operations.
Use virtual threads in high-throughput concurrent application, especially those where concurrent task spend a lot of time waiting for example Server Application often have many blocking requests such as performing database fetching, but still require a high-throughput - making them a perfect candidate to use virtual threads.
To create and use virtual thread both you can use both Thread and Thread.Builder but also java.util.concurrent.Executors defines a way to create an ExecutorService that starts a new virtual thread for each task.
// Using Thread
Thread thread = Thread.ofVirtual().start(() -> System.out.println("Virtual Hello"));
thread.join();
//Using Thread.Builder
Thread.Builder builder = Thread.ofVirtual().name("VirtualBuilderThread");
Runnable task = () -> {
System.out.println("Running virtual thread");
};
Thread thread2 = builder.start(task);
System.out.println("Thread2 name: " + thread2.getName());
thread2.join();
//ExecutorService
try (ExecutorService myExecutor = Executors.newVirtualThreadPerTaskExecutor()) {
Future<?> future = myExecutor.submit(
() -> System.out.println("Running virtual thread -> ExecutorService")
);
future.get();
System.out.println("Task completed");
}
Structured Concurrency
Virtual threads on their own already make concurrency easier and more scalable, but Project Loom goes one step further and introduces the concept of structured concurrency. While virtual threads focus on how tasks run (lightweight, cheap, many of them), structured concurrency focuses on how we organisethose tasks.
In traditional Java code it is very easy to “fire and forget” some background work – submit a task to an executor, return from the method, and hope that somewhere later this task will finish, log errors correctly, and be cancelled when no longer needed. In practice this quickly becomes hard to reason about:
you don’t know which tasks are still running, exceptions get lost in some logging framework, and cancellation becomes a mess of flags and checks scattered everywhere.
Structured concurrency tries to fix this by applying a very simple idea:
All concurrent tasks that logically belong together should also have a shared lifetime and error handling.
Instead of starting threads all over the place, we start them inside a scope, wait for them as a group, and only then move on. If one task fails, we can cancel the others. If the parent operation is cancelled, all children tasks are cancelled as well. This is similar to how we write structured code with try/finally and blocks – but now applied to concurrency.
Project Loom introduces java.util.concurrent.StructuredTaskScope as the main API to implement structured concurrency in Java. A StructuredTaskScope you can coordinate a group of concurrent subtasks as a unit by forking each subtask, which runs them in their own individual thread. Afterwards, you join them back as a single unit. As a result, StructuredTaskScope ensures that the subtasks are completed before the main task continues without introducing bloat through a bunch of Futures and cancellation logic (alternatively you can also specify that the application can continue when one specific subtask is completed, and not wait for all).
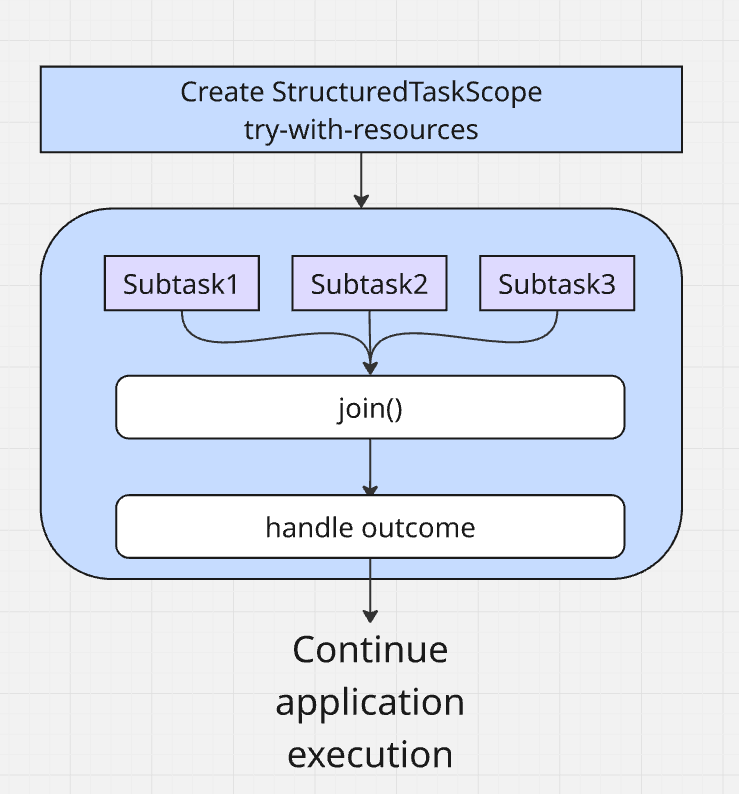
A very common example is calling several remote services in parallel and combining their results. Without structured concurrency, we would manually manage a bunch of Futures and cancellation logic. With Loom it becomes much cleaner:
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
// Run both calls in parallel using virtual threads:
StructuredTaskScope.Subtask<UserProfile> profileTask =
scope.fork(() -> profileClient.fetchProfile(userId));
StructuredTaskScope.Subtask<UserOrders> ordersTask =
scope.fork(() -> ordersClient.fetchOrders(userId));
// Wait for both to finish, or for one to fail:
scope.join(); // wait for all subtasks
scope.throwIfFailed(); // propagate first failure (if any)
// At this point both tasks completed successfully
UserProfile profile = profileTask.get();
UserOrders orders = ordersTask.get();
return new CombinedUserData(profile, orders);
}
StructuredTaskScope comes with a couple of built-in strategies that cover common patterns:
StructuredTaskScope.ShutdownOnFailure– the example above: as soon as one task fails, we shut down the others. Great when all subtasks are required for the final result.StructuredTaskScope.ShutdownOnSuccess– opposite behaviour: once one task completes successfully, the rest are cancelled. This is useful for “race” style scenarios, such as querying multiple replicas or endpoints and using whichever responds first.
The main benefit of structured concurrency is not just nicer syntax, but more predictable behaviour - errors have a clear owner (if a subtask fails the enclosing scope is the place we handle it avoiding silent failures in the background executors), cancelation flows naturally (if the outer operation times out, you can interrupt hte scope and propagate the cancellation to all children tasks), no “orphan” tasks (once the scope exists, all subtasks in that scope are either finished or cancelled).
Combined with virtual threads, this allows you to model complex concurrent workflows using very straightforward, blocking-style code. Each task looks like normal imperative Java, but under the hood the runtime has all the necessary information to manage lifetimes, propagate errors and make efficient use of OS threads.
In other words, virtual threads make concurrency cheap, and structured concurrency makes it manageable. Together, they provide a much simpler mental model compared to classical thread pools plus callbacks, or to fully reactive stacks, while still letting your application scale to a very high number of concurrent operations.
Danger Zone! - problem with syncronized blocks?
Up to this point everything sounds almost magical: millions of virtual threads, clean structured concurrency, blocking I/O without fear…
But there is a sharp edge in this new world that is easy to overlook — synchronized.
Virtual threads suspend themselves only when they hit blocking I/O or particular runtime safepoints that allow the scheduler to unmount them from the carrier (OS) thread. However, the Java runtime cannot unmount a virtual thread while it is executing inside a synchronized block. This is a potential production-grade catastrophic disaster.
Why does this matter?
synchronized is a JVM primitive built on mutual exclusion. Once a virtual thread enters a synchronized block, it parks the carrier thread and holds it until the block exits. This has several consequences:
- The carrier thread is blocked and cannot run other virtual threads.
- If the
synchronizedsection has blocking I/O inside, the carrier thread remains blocked the whole time. - If there are enough of such
synchronizedoperations in flight, your virtual-thread-based system can degrade into a classical thread-per-request model, or worse, stall entirely.
And here is the kicker:
The synchronized usage does not need to be in your code to cause this!
It can come from: a JDBC driver, HTTP client, JSON library, caching client (Redis, Memcached), an ORM like Hibernate or any random legacy third-party library. Once a virtual thread hits it - boom - scaling benefits evaporate.
Worst-case scenario: library induced deadlock cascade
Imagine a server that handles thousands of concurrent requests using virtual threads.
Each request:
- fetches something from the DB
- performs JSON parsing
- writes something to Redis
If any of those libraries use synchronized around critical paths (yes, many still do), you may end up in a scenario where: all carrier threads become occupied → requests pile up → no virtual threads get scheduled → timeouts increase → retry storms amplify load → system grinds to a halt
This is not hypothetical - I’ve seen blog posts of early adopters describing exactly this behaviour in staging environments when migrating legacy stacks to Loom.
Why can’t the Virtual Thread just yield?
JVM syncronization mechanism guaranties called happens-before semantics. In simple terms it basically defines a partial ordering of operations in concurrent systems, guaranteeing that if one action (A) happens-before another (B), all effects of A are visible and ordered before B, even with compiler/CPU optimizations that reorder instructions behind the scenes. It establishes a cause-effect link, crucial for shared memory in multi-threaded programs to ensure consistency, using synchronizers (locks, volatiles, atomics) to enforce this order across threads.
Because the JVM must preserve the atomicity guarantees that synchronized provides. Pre-emptively unmounting a virtual thread mid-held monitor would break Java’s happens-before semantics. So the runtime plays it safe and keeps the carrier pinned.
This is why the Loom docs emphasize that synchronized blocks are best used for small, CPU-bound, short critical sections - not around blocking calls.
In other words this:
synchronized (lock) {
// blocks for 100ms (I/O)
performDatabaseQuery();
}
Is catastrophic under load.
And here is where a lot of teams get blindsided:
You don’t control other people’s code.
You might have a JSON library that uses synchronized on parsing buffers, or a JDBC driver that synchronizes on a connection object or an HTTP client that serializes request writes under a lock etc. These issues might not appear locally, or under 10 req/s load, but show up brutally at 2k–50k req/s under real concurrency.
If you adopt virtual threads in a non-trivial system, you must do locking analysis. Either Grep / Search manually your deps for syncronized and analyse it for potential blocking calls (obviously not ideal for large projects) or use async-profiler / JFR (Java Flight Recorder) to inspect thread states.
JFR actually exposes a specific event VirtualThreadPinned exactly meant to highlight these situation. For example following event:
VirtualThreadPinned {
reason = "monitor-enter"
duration = 83ms
location = com.some.jdbc.Driver.executeQuery()
}
Means that a JDBC query was executed under lock for 83ms, pinning the carrier and NOT releasing the virtual thread.
So what should developers do?
Avoid these under virtual threads:
- synchronized around I/O
- synchronized around network calls
- synchronized around logging
- synchronized around JDBC / caches
- synchronized around filesystem access
Prefer:
- ReentrantLock (doesn’t pin)
- I/O libraries known to be Loom-friendly
- async drivers that block in Loom-aware manner
- structured concurrency to group tasks
- immutable, thread-safe, lock-free data structures
Conclusion
Project Loom introduces virtual threads and structured concurrency — two powerful additions that finally make the classic thread-per-request model scalable again without forcing developers into callback-driven reactive APIs.
Virtual threads dramatically reduce the cost of blocking I/O, while structured concurrency brings back simplicity and predictable reasoning around task lifecycles, cancellation and error propagation.
They are not a silver bullet however: Loom is not intended for CPU-heavy workloads, and migrating existing systems requires awareness of hidden synchronization primitives in third-party libraries that can silently pin carrier threads and destroy scalability under load.
With the right understanding and careful evaluation, adopting Loom can significantly simplify concurrent Java applications and unlock throughput that previously required complex reactive frameworks.
[story continues]
tags