
Why I ditched the standard Python stack to run Qwen3-VL on an OrangePi 4 — and the hardware-specific "horror stories" that nearly broke me.
Let’s be real: the AI world is currently high on "clever prompts." Everyone is a "Prompt Engineer" until they have to build a safety system for a warehouse robot or a real-time monitor for a smart city. In the high-stakes world of Industry 4.0, a prompt is just a string. To actually do something, you need a system.
Analysts say IoT devices will puke out 79.4 zettabytes of data by 2025. Sending all that to the cloud is suicide. If your latency spikes by 500ms while a robotic arm is moving, you don't just get a slow response; you get a broken machine.
This is the post-mortem of FogAI — a distributed inference platform I built to prove that if you want AI to interact with the physical world, you have to ditch Python and get closer to the metal.
The Setup: Trading Places (i7 vs. OrangePi)
I didn't just build this on a laptop. I built a heterogeneous "Fog" bench to test the limits of scale:
- The Heavyweight: A 13th Gen Intel Core i7-13700H (20 cores) acting as the API Gateway while an OrangePi 4 handled the edge inference.
- The Underdog: I flipped it. The OrangePi 4 ran the Vert.X Gateway, orchestrating requests to the i7 server.
The Lesson: The "Fog" is a zoo. Nodes connect and vanish constantly. To survive this, I implemented a nodes.json registry where each node reports its local model manifest. The Gateway doesn't just "throw" a request; it knows which "beast" in the network has the RAM to handle a Qwen3-VL-4B and which can only handle a tiny sensor-fusion model.
The "Jekyll and Hyde" Architecture
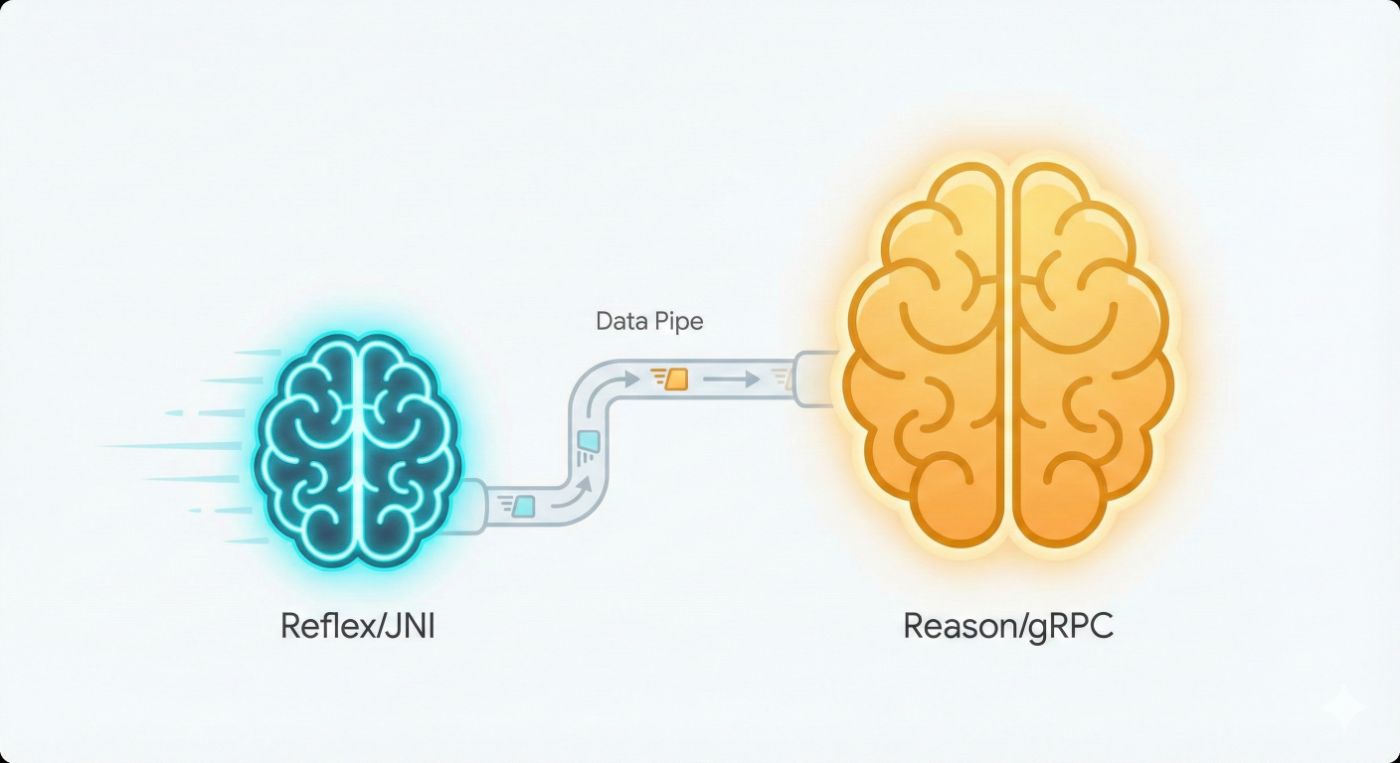
To solve the conflict between low latency (deterministic safety) and scalability (chat), I split the system into two node types:
Type A: The Speed Demon (In-Process JNI)
Network calls are too slow for "Reflex" tasks. Even a localhost loopback adds milliseconds you can't afford.
-
The Tech: I load Alibaba MNN and ONNX Runtime directly into the JVM memory space via JNI.
-
The Zero-Copy Magic: Using Vert.X (Netty), I read the HTTP body into an off-heap
DirectByteBuffer. I pass the raw memory address (alongpointer) straight to C++. -
Result: The inference engine reads the data exactly where it sits. Zero memory copies.
-
Latency: Overhead per call? 20–50 microseconds.
Type B: The Heavy Lifter (gRPC)
You can’t run a massive LLM inside the same process as your safety controller. If the LLM hits an OOM (Out of Memory), it takes the whole factory down.
- The Tech: Standalone C++ microservices communicating via gRPC (Protobuf).
- Result: Fault isolation. The "Reasoning" system can crash, but the "Reflex" system stays up.
Engineering Hell: Hardware-Specific Nightmares

Standard AI tutorials tell you to just "install the library." In the Fog, you compile for the soul of the machine.
1. The Intel "AVX-512 Lie"
On the i7-13700H, I initially tried to force DMNN_AVX512=ON. Big mistake. Intel disabled AVX-512 in 13th gen consumer chips because the E-cores (Efficiency cores) don't support it.
- The Fix: Use
-DMNN_VNNI=ONto activate Intel DL Boost. This is the secret sauce for i7 13th gen; it accelerates quantized integer operations (INT8) by up to 3x. - The Bonus: I used
-DMNN_OPENCL=ONto offload LLM decoding to the integrated UHD 770 graphics, keeping the CPU free for Vert.X orchestration.
2. ARM "KleidiAI" Magic
For the OrangePi (Rockhip), generic binaries are trash. I used -DMNN_KLEIDIAI=ON to leverage ARM's latest operator-level optimizations. This gave me a 57% pre-fill speedup on models like Qwen2.5-0.5B.
The "Blood" on the Screen: JNI Segfaults

Integration was a nightmare. If you free memory in C++ while Java is still looking, the world ends.
The Log of Doom: SIGSEGV (0xb) at pc=0x00007a6fac7bed8c, problematic frame: C [libllm.so+0xfcd8c] MNN::Transformer::Tokenizer::encode.
No stack trace. No "Helpful Exception." Just the JVM falling into the arms of the Linux kernel. I had to build a custom Reference Counting system to ensure the JVM didn't GC the buffers while MNN was still chewing on them.
Performance: Why We Win
I benchmarked FogAI (Kotlin/Vert.X + JNI MNN) against a standard FastAPI/Python wrapper on the same hardware.
|
Metric |
Python (FastAPI + PyTorch) |
FogAI (JNI Type A) |
Improvement |
|---|---|---|---|
|
Idle RAM |
~180 MB |
~45 MB |
4x Lower |
|
Request Overhead |
2.5 ms |
0.04 ms |
60x Faster |
|
Throughput (Qwen2.5 0.5B) |
45 req/sec |
320 req/sec |
7x Higher |
The "saturation cliff" where Python's GIL chokes performance under load? Gone. Vert.X lets me launch hundreds of Worker Verticles, each isolated and mapped to an event loop that feeds the C++ engine as fast as the silicon allows.
Conclusion: Get Closer to the Metal
Stop treating Edge AI like "Cloud AI but smaller." At the edge, latency isn't a UX metric — it's a safety requirement.
Building FogAI was painful. Dealing with CMake flags like -march=native and fighting JNI pointers is not "developer friendly." But if you want to build autonomous systems that actually work without a cloud tether, you have to leave the comfort of Python.
The code (Gateway + C++ services) is open source. Join the suffering:
[story continues]
tags