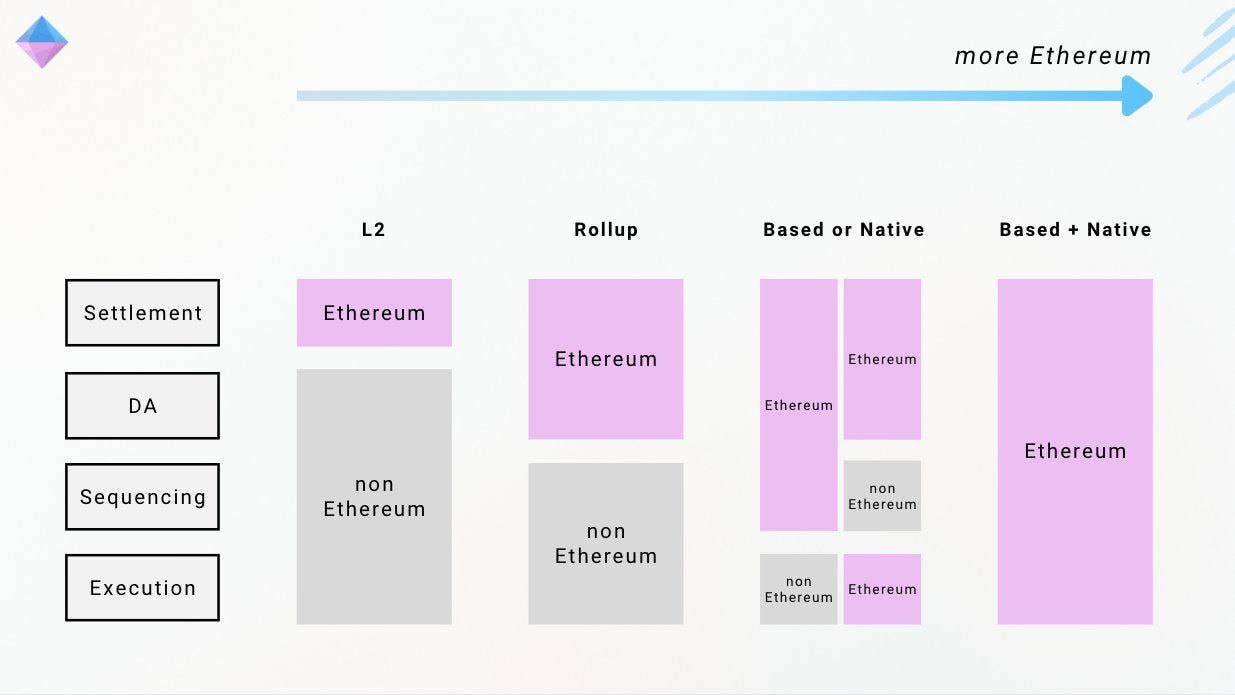
The image I used as the banner for this article was created by the beautiful folks at Spire Labs. It provides a great visual overview of how different Layer 2 solutions utilize Ethereum's infrastructure. In this article, I will be expanding on Native and Based Rollups to give you a complete picture of how these architectures work and fit together.
The Rollup Landscape: Four Key Components
Any Layer 2 solution has four critical components, as shown in the left column of the image:
-
Settlement - Where the final state is recorded and secured
-
Data Availability (DA) - Where transaction data is stored
-
Sequencing - Who decides the order of transactions
-
Execution - Who processes the transactions
Traditional L2s might use Ethereum for settlement and DA, but handle sequencing and execution independently. The "Based" and "Native" approaches aim to leverage more of Ethereum's infrastructure for increased security.
Based Rollups: Ethereum-Powered Sequencing
What Are Based Rollups?
Based Rollups use Ethereum not just for settlement and data availability, but also for transaction sequencing. This means the order of transactions in a Based Rollup is determined directly by Ethereum's validators rather than by a separate sequencer.
How Based Rollups Work
-
Transaction Submission: Users submit transactions directly to Ethereum L1
-
Ethereum Sequencing: Ethereum miners/validators determine transaction order
-
Data Storage: Transaction data gets stored on Ethereum (in calldata or blobs)
-
Off-Chain Execution: The transactions are still executed off-chain by the rollup
-
State Commitment: The results are posted back to Ethereum for settlement
Benefits of Based Rollups
-
Censorship Resistance: No separate sequencer means no single point of control for transaction ordering
-
MEV Protection: Leverages Ethereum's MEV (Maximal Extractable Value) protections
-
Quick Soft Confirmations: Transactions gain some security as soon as they appear in the Ethereum mempool
-
Permissionless: Anyone can submit transactions without going through a controlled sequencer
Challenges of Based Rollups
-
Higher Latency: Transactions must wait for Ethereum block times
-
Higher Costs: Every transaction pays for Ethereum gas directly
-
Limited Throughput: Bounded by Ethereum's transaction capacity
Native Rollups: Ethereum-Powered Execution
What Are Native Rollups?
Native Rollups use Ethereum not just for settlement and data availability, but for execution verification through the proposed EXECUTE precompile. This means the processing of transactions is directly verified by Ethereum validators.
How Native Rollups Work
-
Off-Chain Sequencing: Transactions can be sequenced by a separate entity
-
Data Storage: Transaction data gets stored on Ethereum
-
Native Execution Verification: The EXECUTE precompile verifies state transitions
-
Settlement: Results are secured by Ethereum's consensus
Benefits of Native Rollups
-
Full Security Inheritance: Rollup security is equivalent to Ethereum's
-
No Security Councils: Eliminates need for trusted operators or multisigs
-
Automatic EVM Compatibility: Native rollups automatically stay compatible with Ethereum upgrades
-
Simplified Development: Much simpler to build and maintain
Challenges of Native Rollups
-
Requires Ethereum Protocol Changes: The EXECUTE precompile must be added to Ethereum
-
Potentially Higher Costs: Native verification may be more expensive than optimized custom solutions
-
Potentially Limited Customization: Must follow Ethereum's execution rules
Ultra Sound Rollups: Based + Native
Ideally, what we want are what Ethereum researcher Justin Drake called "Ultra Sound Rollups". These are L2 solutions that are both Based AND Native. These would use Ethereum for all four critical components:
-
Settlement on Ethereum
-
Data availability on Ethereum
-
Sequencing by Ethereum
-
Execution verified by Ethereum (via the EXECUTE precompile)
This represents maximum security and decentralization, though likely with tradeoffs in performance and cost. However, these would more closely mirror the Ethereum L1 architecture in terms of security and decentralization than other options.
The Spectrum of Trust
What's fascinating about this approach is how it creates a spectrum of trust:
-
Traditional L2s: Trust the sequencers, execution mechanisms, and security councils
-
Based Rollups: Trust the execution, but sequencing is secured by Ethereum
-
Native Rollups: Trust the sequencing, but execution is secured by Ethereum
-
Ultra Sound Rollups: Both sequencing and execution secured by Ethereum
Practical Implications
For Users
-
Security Choice: Can choose the L2 with the right balance of security vs performance
-
Consistent Experience: Native rollups will behave exactly like Ethereum
-
MEV Protection: Based rollups offer better protection against transaction manipulation
For Developers
-
Simplified Stack: Native rollups dramatically simplify the tech stack needed to run an L2
-
Sequencing Options: Can choose between the censorship resistance of Based sequencing or the performance of dedicated sequencers
-
Migration Path: Existing rollups could gradually adopt Based or Native components
The Future Landscape
As you can see from the Spire Labs diagram, there is a clear progression toward "more Ethereum" - with rollups leveraging more of Ethereum's infrastructure for increased security guarantees. This evolution depicts what the endgame of the Ethereum L2-centric roadmap would look like. A future where Layer 2s are not separate systems, but rather extensions of Ethereum itself, with different configurations of which components are based on Ethereum's infrastructure. Whether a rollup chooses to be Based, Native, or both will likely depend on its specific use case:
-
High-Security Applications: Might choose Ultra Sound Rollups (Both Based + Native)
-
Performance-Focused Applications: Might use selectively Based OR Native components
-
Custom Applications: Might use traditional rollup architecture with specialized components
By understanding these architectural choices, users and developers can make more informed decisions about which L2 solutions best meet their needs for security, decentralization, cost, and performance.
Hope you found this helpful.