
If you are a developer, no matter the technologies you use, at some point, you will face the challenge of handling large Excel files.
Most commonly, you will see the “out of memory” error when handling these files.
Here is the requirement.
You get a workbook with 100 spreadsheets, and each of them has 1 million records with a minimum of 100 columns.
For your reference: here's how many rows each Excel version can support:
- 1048576 rows- Excel 365,2013,2010,2007
- 65,536 rows - Excel 2003 and earlier versions.
Cost & Hosting Server Limitations
- Third-party license purchase is not feasible. Open source is allowed.
- Deployment should be on average-tier cloud environments (4 GB disk/4 GB RAM or less) or on-prem Windows server (16/32 GB RAM) already loaded with 10+ running applications.
How would you handle this situation?
Let’s explore the current digital market. Are there any open source solutions available to this requirement?
I can say that the most popular library is the “Apache POI” streaming library.
I can’t use “interop” when your cloud runs on “Linux OS”, and it also causes intermittent hang issues in multi-threaded applications.
Let’s proceed with a practical implementation using Apache POI
To get the large dataset (Excel) file, we have N number of websites, such as awesome-public-datasets, Google Dataset Search, and World Bank Data.
I frequently travel to Kaggle.
Let’s download the container dataset as a 1.9GB CSV file, and then save it as an Excel file (.XSLX), which then becomes around a 600 MB XLSX file.
The sheet includes 87 columns and 1048576 rows.
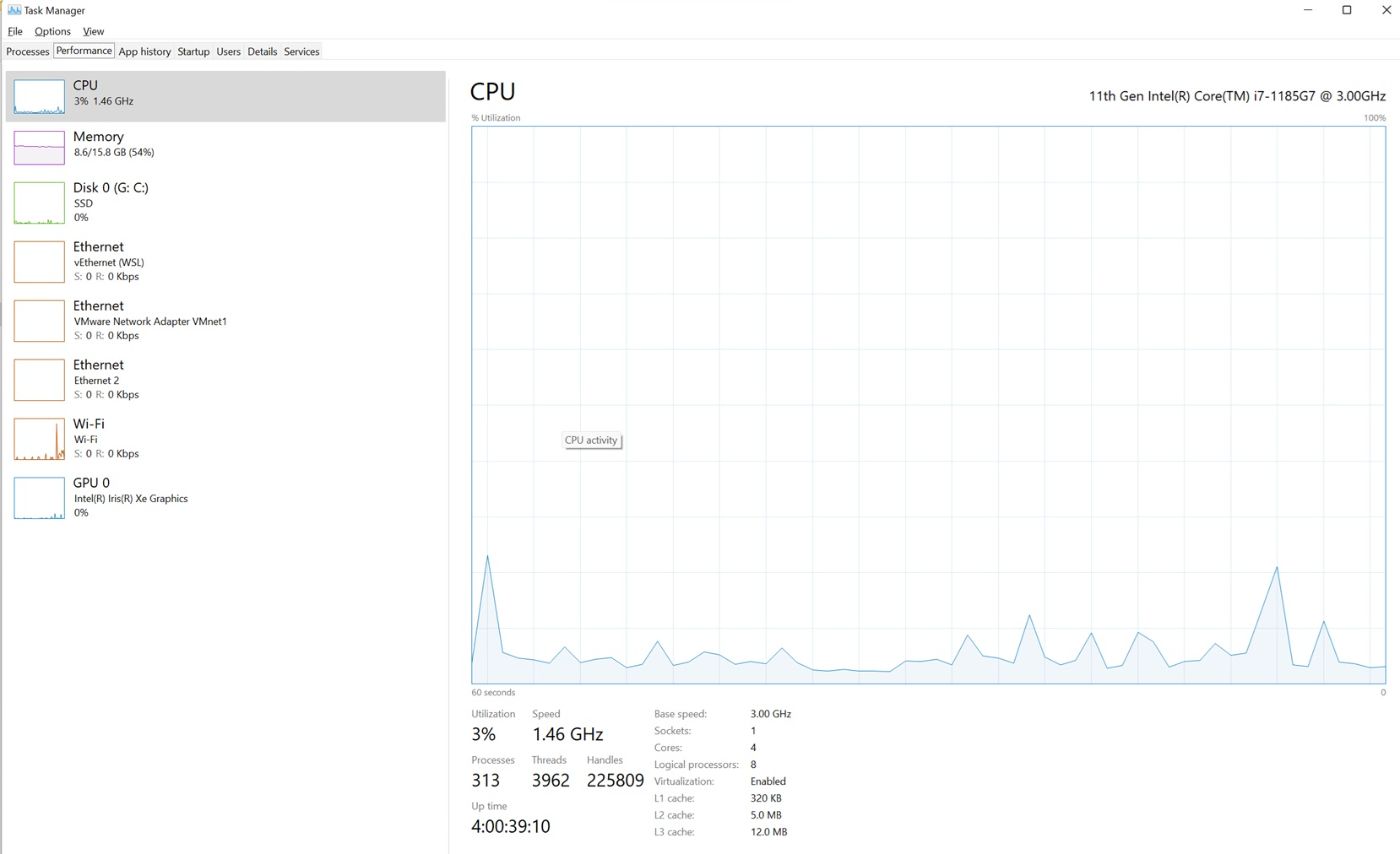
Before we run the solution, let me capture my laptop’s resource usage so that we can compare later.
Resource Usage
IDE
I am using Eclipse IDE (v: 4.36.0).
Apache POI
I am using the latest Apache POI 5.2.5 and other dependency JARS available from Apache POI.
Source Code
Here, I am just attempting to read the sheet name from the workbook, not the rows.
public static void main(String[] args) throws Exception {
String filePath = "C:\\POC\\Containers_Dataset.xlsx";
ReadExcelbyApachePOI(filePath);
}
/*List out sheet name*/
static void ReadExcelbyApachePOI(String filePath) throws Exception {
try (OPCPackage opcPackage = OPCPackage.open(new File(filePath), PackageAccess.READ)) {
XSSFWorkbook workbook = new XSSFWorkbook(opcPackage);
XSSFReader xssfReader = new XSSFReader(opcPackage);
StylesTable styles = xssfReader.getStylesTable();
XSSFReader.SheetIterator iter = (XSSFReader.SheetIterator) xssfReader
.getSheetsData();
while (iter.hasNext()) {
InputStream stream = iter.next();
String sheetName = iter.getSheetName();
System.out.println("Sheetname: " + sheetName);
}
} catch (IOException e) {
e.printStackTrace();
}
}
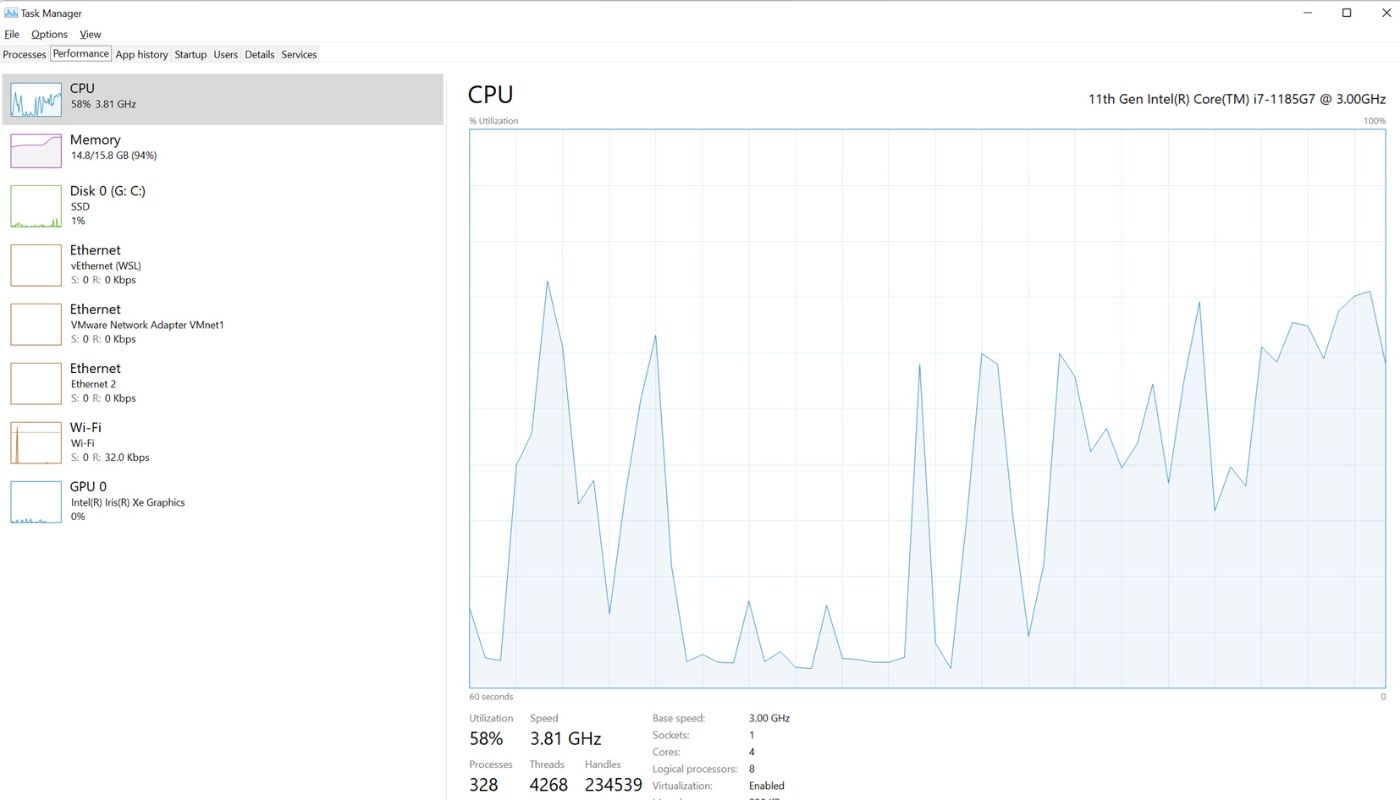
Result
Encountering Java heap space "Out of memory error."
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
Resource Usage
- CPU: 58%
- Memory: 94%
sjxlsx open-source API
It’s an open-source Java API Source code; this project was first published on Google Code, and it seems unmaintained.
In GitHub, it is available for anyone who can download & update the changes for their needs.
“Memory” & “Speed” are the Primary goals of this API.
It provides two modes: “classic” & “stream.”
- Classic - All records of the sheet will be loaded.
- Stream – Read one record at a time.
Microsoft XLSX uses XML+zip (OOXML) to store the data. So, to be fast, sjxlsx uses STAX for XML input and output.
Source Code
public static void main(String[] args) throws Exception {
String filePath = "C:\\POC\\Containers_Dataset.xlsx";
SimpleXLSXWorkbook workbook = newWorkbook(filePath);
testLoadALL(workbook);
}
private static SimpleXLSXWorkbook newWorkbook(String filePath) {
return new SimpleXLSXWorkbook(new File(filePath));
}
/*Read Each Row*/
private static void printRow(int rowPos, com.incesoft.tools.excel.xlsx.Cell[] row) {
int cellPos = 0;
for (com.incesoft.tools.excel.xlsx.Cell cell : row) {
System.out.println(com.incesoft.tools.excel.xlsx.Sheet.getCellId(rowPos, cellPos) + "=" + cell.getValue());
cellPos++;
}
}
/*Load & Read workbook
* false => Read each row
* true => Load all rows
*/
public static void testLoadALL(SimpleXLSXWorkbook workbook) {
com.incesoft.tools.excel.xlsx.Sheet sheetToRead = workbook.getSheet(0,false);
SheetRowReader rowreader = sheetToRead.newReader();
int rowPos = 0;
while (rowreader != null) {
com.incesoft.tools.excel.xlsx.Cell[] row = rowreader.readRow();
printRow(rowPos, row);
rowPos++;
}
}
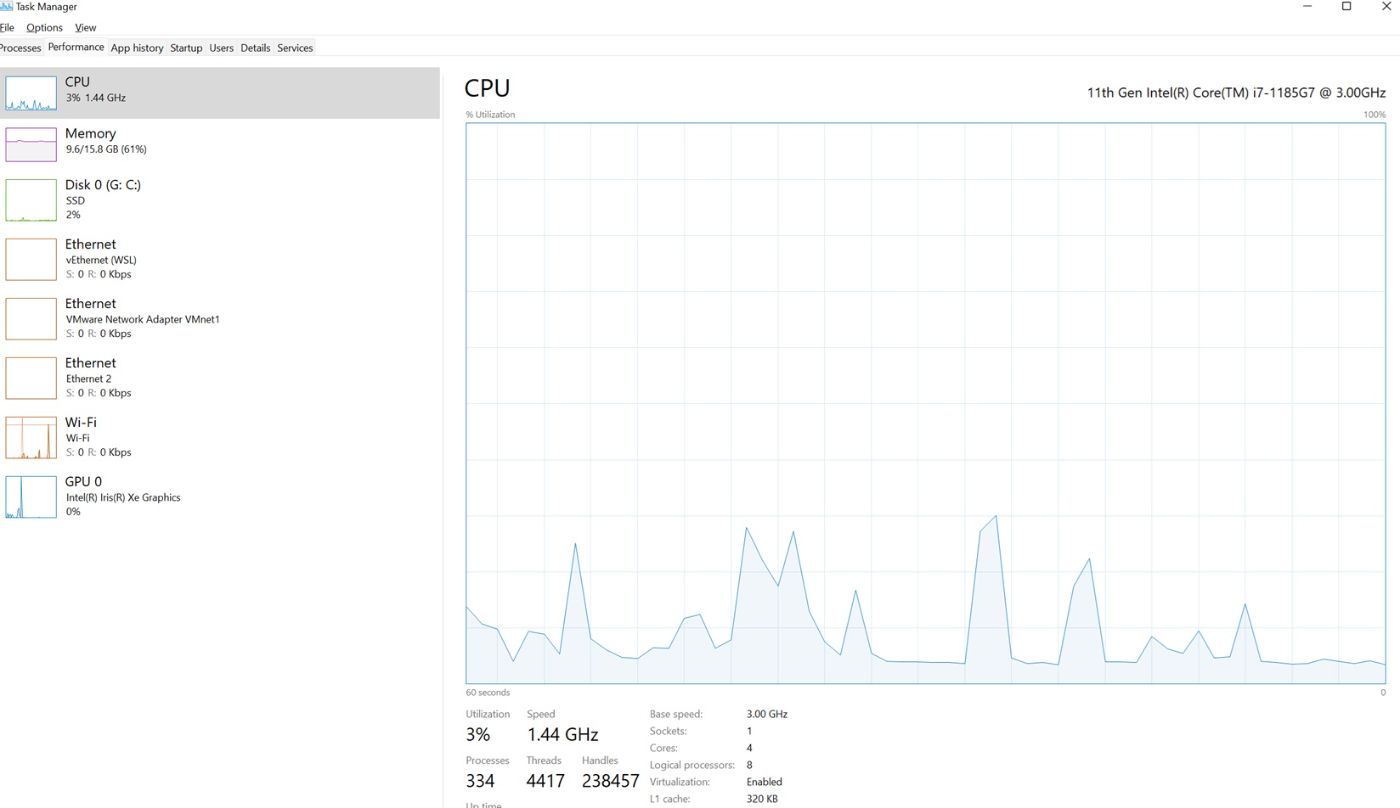
Resource Usage
CPU : 3% (No changes)
RAM: 61% (7% usage: 1 GB Usage)
Output
BN1048519=40298
BO1048519=0
BP1048519=0
BQ1048519=0
BR1048519=0
BS1048519=610
BT1048519=0
BU1048519=1
BV1048519=64240
BW1048519=923
BX1048519=158
BY1048519=32
BZ1048519=0
CA1048519=0
CB1048519=0
CC1048519=0
CD1048519=0
CE1048519=0
CF1048519=0
CG1048519=0
CH1048519=10000206
CI1048519=0
A1048520=100.64.0.2-10.16.0.9-35919-8080-6
B1048520=100.64.0.2
C1048520=35919
D1048520=10.16.0.9
E1048520=8080
F1048520=6
G1048520=45266.83932053241
H1048520=41626
I1048520=6
J1048520=5
K1048520=515
L1048520=357
M1048520=515
N1048520=0
O1048520=85.8333333333333
P1048520=210.24786958888899
Q1048520=357
R1048520=0
S1048520=71.400000000000006
Performance Results
The winner is “sjxlsx.” It’s clearly proven that this library consumes less than 1 GB of memory, compared to the higher usage by Apache POI.
It is an excellent open-source Java API for reading large Excel datasets.
Summary
sjxlsx provides an efficient and lightweight way to read large Excel files without infrastructure headaches.
[story continues]
tags