In most data orchestration frameworks, the way data is treated is an afterthought. You build workflows, wire components together, and hope that the data behaves the way you expect. Under the hood, values are mutated, transformed implicitly, or hidden in stateful components.
But CocoIndex https://github.com/cocoindex-io/cocoindex flips that approach on its head.
Having worked in the field for many years, we observed that side effects in traditional systems often lead to increased complexity, debugging challenges, and unpredictable behavior. This experience drove us to embrace a pure data flow programming approach in CocoIndex, where data transformations are clear, immutable, and traceable, ensuring reliability and simplicity throughout the pipeline.
Instead of treating data as a black box that passes between tasks, CocoIndex embraces the Data Flow Programming paradigm — where data and its transformations are observable, traceable, and immutable. This shift makes a world of difference when you're working with complex pipelines — especially in knowledge extraction, graph building, and semantic search.
What Is Data Flow Programming?
Data Flow Programming is a declarative programming model where:
- Data “flows” through a graph of transformations.
- Each transformation is pure — no hidden side effects, no state mutations.
- The structure of your code mirrors the structure of your data logic.
This is fundamentally different from workflow orchestrators like Airflow or Dagster, where tasks are orchestrated in time and data is often opaque.
In CocoIndex, data is the primary unit of composition, not tasks.
A Simple Data Flow in CocoIndex
Let’s look at a conceptual data flow:
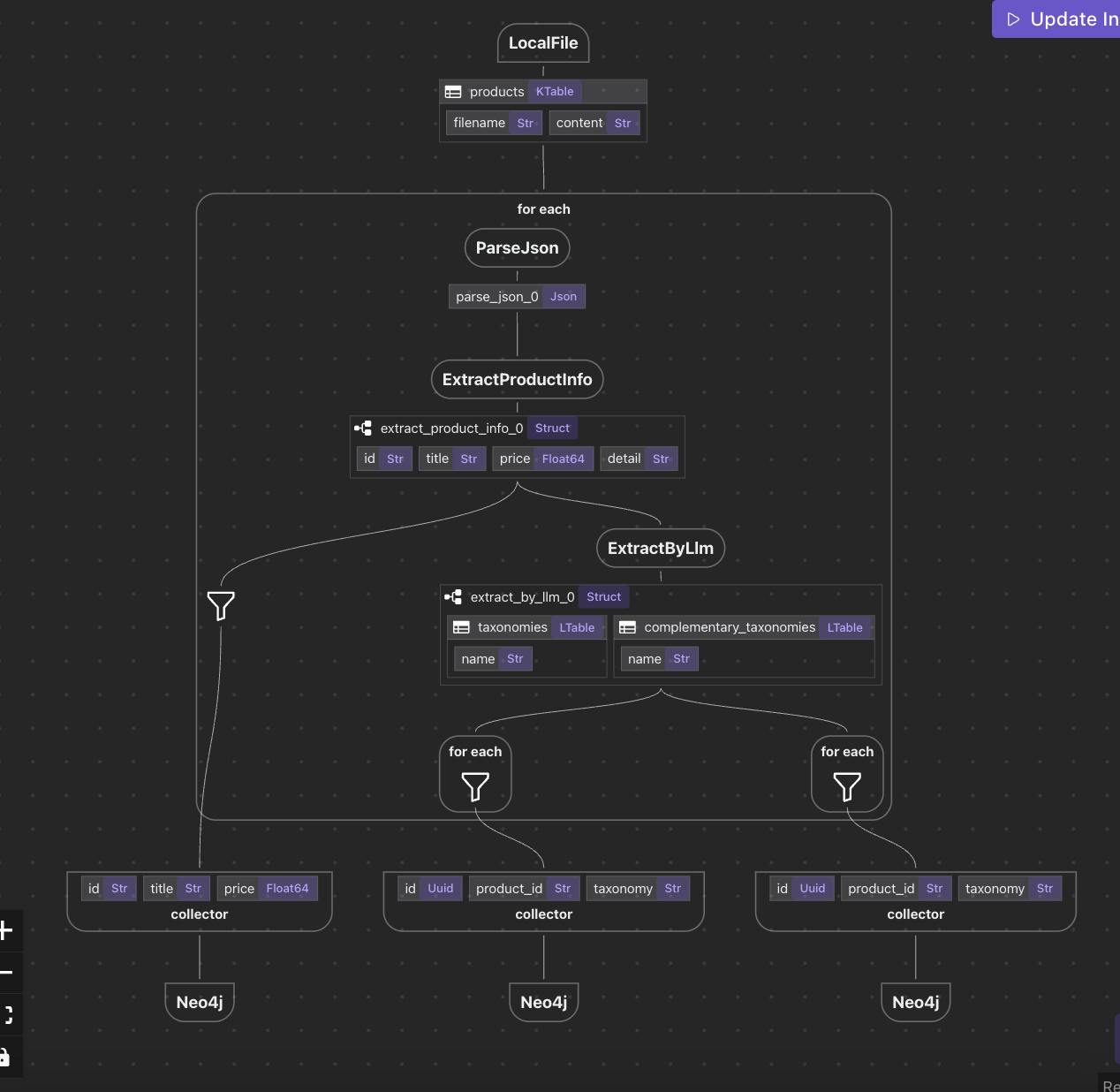
Parse files → Data Mapping → Data Extraction → Knowledge Graph
Each arrow represents a transformation: a function that takes in data and produces new data. The result is a chain of traceable steps where you can inspect both inputs and outputs — at every point.
Every box in this diagram represents a declarative transformation — no side effects, no hidden logic. Just clear, visible dataflow.
Code Example: Declarative and Transparent
Here’s what this flow might look like in CocoIndex:
# ingest
data['content'] = flow_builder.add_source(...)
# transform
data['out'] = data['content']
.transform(...)
.transform(...)
# collect data
collector.collect(...)
# export to db, vector db, graph db ...
collector.export(...)
The beauty here is that:
- Every
.transform()is deterministic and traceable. - You don’t write CRUD logic — CocoIndex figures that out.
- You can observe all data before and after any stage.
No Imperative Mutations — Just Logic
In traditional systems, you might write:
if entity_exists(id):
update_entity(id, data)
else:
create_entity(id, data)
But in CocoIndex, you say:
data['entities'] = data['mapped'].transform(extract_entities)
And the system figures out whether that implies a create, update, or delete. This abstracts away lifecycle logic, allowing you to focus on what really matters: how your data should be derived, not how it should be stored.
Why This Matters: Benefits of Data Flow in CocoIndex
🔎 Full Data Lineage
Want to know where a piece of knowledge came from? With CocoIndex’s dataflow model, you can trace it back through every transformation to the original file or field.
🧪 Observability at Every Step
CocoIndex allows you to observe data at any stage. This makes debugging and auditing significantly easier than in opaque pipeline systems.
🔄 Reactivity
Change the source? Every downstream transformation is automatically re-evaluated. CocoIndex enables reactive pipelines without additional complexity.
🧘♀️ Declarative Simplicity
You don’t deal with mutation, errors in state sync, or manual orchestration. You define the logic once — and let the data flow.
A Paradigm Shift in Building Data Applications
CocoIndex’s data flow programming model isn’t just a feature — it’s a philosophical shift. It changes how you think about data processing:
- From task orchestration → to data transformation
- From mutable pipelines → to immutable observables
- From imperative CRUD code → to declarative formulas
This makes your pipeline easier to test, easier to reason about, and easier to extend.
Final Thoughts
If you're building pipelines for entity extraction, search, or knowledge graphs, CocoIndex’s data flow programming model offers a new kind of clarity. You no longer have to juggle storage operations or track state changes — you just define how data transforms.
And that’s a future worth building toward.
We are constantly improving, and more features and examples are coming soon. If you love this article, please drop us a star ⭐ at GitHub repo to help us grow.