The Cloud is Just Someone Else’s Bottleneck
There’s a common idea that if you need to move a lot of data fast, you have to hand it off to a cloud provider. I’ve always preferred edge computing — I like API keys, but I hate usage limitations and high call costs. I wanted to see if the cloud was actually necessary or if we’re just over-complicating our local setups.
The Problem
Most home or office setups struggle with high-speed data because the “pipes” — the software and hardware overhead — get clogged. If you have a 10Gbps link but your CPU can’t keep up with the data partitioning, you’re effectively stuck at 1Gbps speeds. The hardware is fast, but the management is slow.
The Experiment
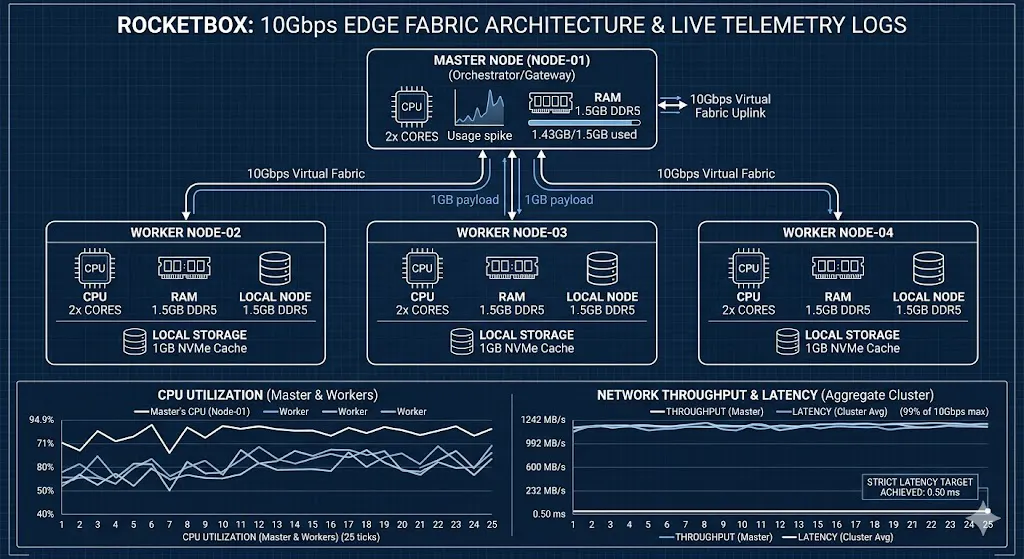
I’ve been watching how some industry veterans handle hardware constraints. They bet on lean, high-efficiency clusters, and I wanted to see if they were right. I set up a four-node cluster (one master, three workers) and gave each node only 2 CPU cores and 1.5GB of RAM. I deliberately mimicked these tight constraints to see if the orchestration could stay ahead of the hardware.
I tried to shove a 1GB file through a 10Gbps virtual bridge. I wasn’t looking for “efficiency” in a vague sense. I was looking for two specific numbers:
- Saturation: Could I hit 1250 MB/s (the theoretical 10Gbps limit)?
- Stability: Could I keep the delay (latency) under 0.5 milliseconds?
What the Data Showed
The Master node had to work. Its CPU usage spiked to 94.9% because it was busy chopping up the file and throwing shards at the workers. But it didn’t choke.
The Master hit a peak of 1242.55 MB/s. In plain terms, that is 99% of the theoretical maximum. It used almost all of its 1.5GB of RAM (peaking at 1.43GB), but it didn’t crash or swap.
The Average Performance:
- Master Speed: ~1188 MB/s
- Worker Speed: ~393 MB/s (each)
- Latency: 0.50 ms
The delay stayed flat. Usually, when you stress a system, the latency “jitters” or climbs as the buffer fills up. Here, it stayed right at the 0.5ms mark throughout the entire 1GB transfer.
Why This Matters
If you can move a gigabyte of data in a single second with sub-millisecond delay on hardware this lean, you don’t need a massive data center for heavy lifting. You can do distributed AI or massive data processing locally.
It proves that the “weight” of the data isn’t the problem — it’s the orchestration. By keeping the path short and the instructions simple, the hardware finally runs at the elite speeds it was built for.
As always, I do have the code and the results on GitHub.
GitHub - damianwgriggs/Rocketbox-Orchestration
Contribute to damianwgriggs/Rocketbox-Orchestration development by creating an account on GitHub.
Also want to be very clear that these are simulated results, a demo/logic check. In no way do I claim definitively that my software is able to provide results in the real world. I believe strongly in logically thinking through and prototyping concepts before further resources and effort are put into production, and this is one of those prototypes/proof of concepts.