Apache DolphinScheduler has already been deployed on a virtual machine.
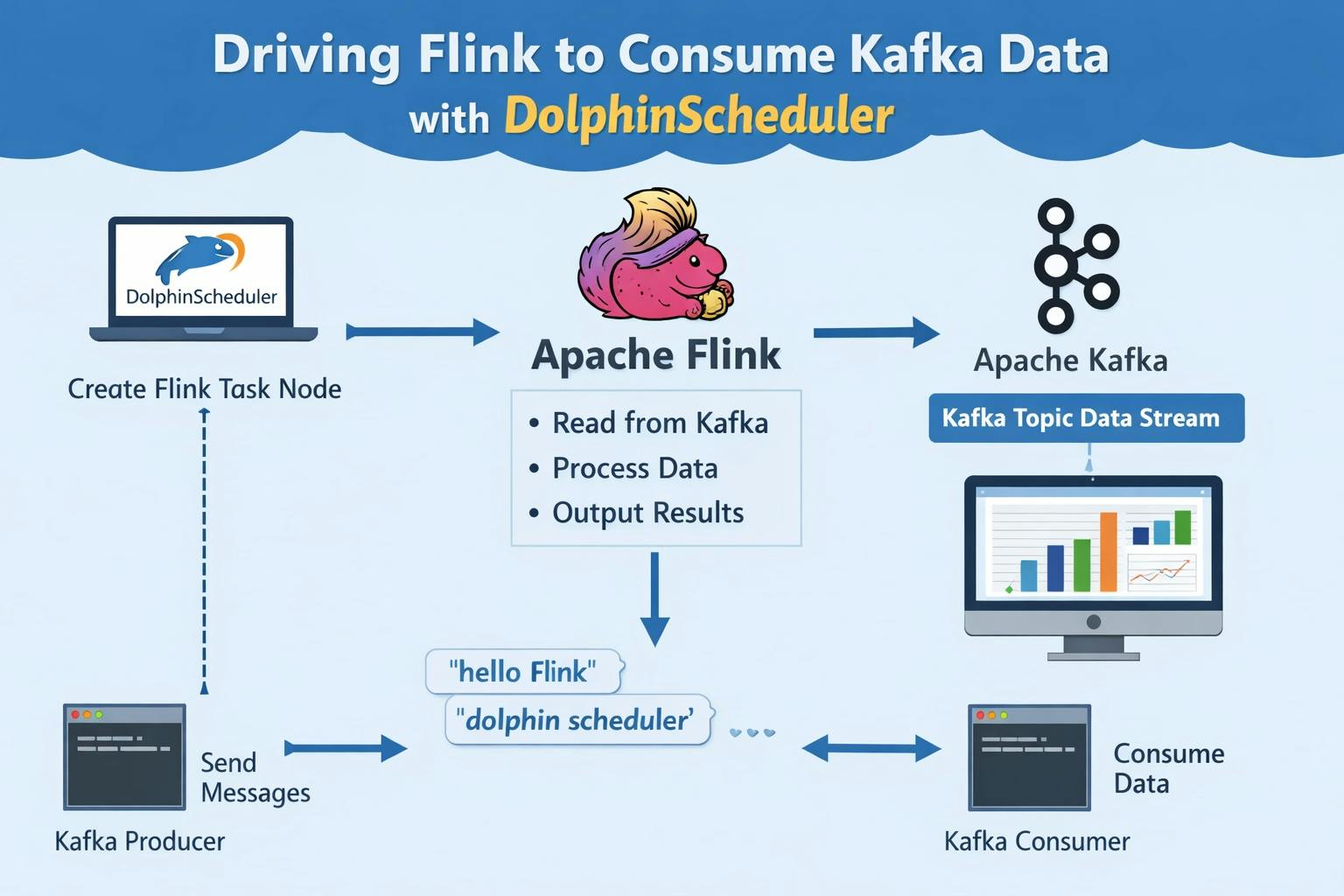
Next, we want to try creating a Flink task node in DolphinScheduler and use Flink to consume data from Kafka.
Apache DolphinScheduler is deployed in standalone mode.
For detailed installation steps, please refer to the official documentation:
DolphinScheduler | Documentation Center
https://dolphinscheduler.apache.org/zh-cn/docs/3.3.2/guide/installation/standalone
Prerequisites
The following components have already been installed:
- Java 11
- Apache DolphinScheduler 3.3.2
- Apache Flink 1.18.1
- Apache Kafka 3.6.0
- ZooKeeper (using the built-in Kafka version)
It is recommended to download and install binary packagesdirectly on the virtual machine. Installing via system package managers may introduce uncontrollable dependencies.
The downloaded binary packages are shown below:
Configure Flink Environment Variables
1. Edit environment variables
sudo vim ~/.bashrc
Add the Flink installation path:
2. Make the configuration effective
# Reload environment variables
source ~/.bashrc
# Verify Flink environment variable
echo $Flink_HOME
Modify Kafka, Flink, and DolphinScheduler Configuration Files
Since this setup runs inside a virtual machine, configuration changes are required so that services can be accessed from the host machine.
1. Modify Kafka configuration
Navigate to the config directory under the Kafka installation path and edit server.properties.
The listeners and advertised.listeners settings must be modified so that Kafka can be accessed externally. Otherwise, Kafka will default to localhost, which may cause connection failures.
broker.id=0
listeners=PLAINTEXT://0.0.0.0:9092
# Replace with your VM IP address
advertised.listeners=PLAINTEXT://192.168.146.132:9092
2. Modify Flink configuration
Go to the conf directory under the Flink installation path and edit flink-conf.yaml.
Replace all localhost addresses with 0.0.0.0 so the Flink Web UI can be accessed externally.
Additionally, adjust JobManager and TaskManager memory settings.
jobmanager.rpc.address: 0.0.0.0
jobmanager.bind-host: 0.0.0.0
jobmanager.cpu.cores: 1
jobmanager.memory.process.size: 1600m
taskmanager.bind-host: 0.0.0.0
taskmanager.host: 0.0.0.0
taskmanager.memory.process.size: 2048m
taskmanager.cpu.cores: 1
3. Modify Apache DolphinScheduler configuration
From the dolphinscheduler-daemon.sh startup script, we can see that DolphinScheduler loads environment variables from:
bin/env/dolphinscheduler_env.sh
View dolphinscheduler-daemon.sh:
Edit dolphinscheduler_env.sh and add Java and Flink paths:
# Replace with your actual Java and Flink paths
export JAVA_HOME=/data/jdk-11.0.29
export Flink_HOME=/data/Flink-1.18.1
Disable Firewall and Start Services
Start all required services, including ZooKeeper, Kafka, Flink, and Apache DolphinScheduler.
# Disable firewall
sudo systemctl stop firewalld
# Start Flink cluster
bin/start-cluster.sh
# Start ZooKeeper
bin/zookeeper-server-start.sh config/zookeeper.properties &
# Start Kafka broker
bin/kafka-server-start.sh config/server.properties &
# Create Kafka topic
bin/kafka-topics.sh --create --topic test \
--bootstrap-server localhost:9092 \
--partitions 1 --replication-factor 1
# Produce messages
bin/kafka-console-producer.sh --topic test \
--bootstrap-server localhost:9092
# Consume messages
bin/kafka-console-consumer.sh --topic test \
--from-beginning --bootstrap-server localhost:9092
# Start DolphinScheduler Standalone Server
bash ./bin/dolphinscheduler-daemon.sh start standalone-server
Verification
1. Verify Flink Web UI
Access the Flink dashboard at:
http://<VM-IP>:8081
2. Verify DolphinScheduler Web UI
Access DolphinScheduler at:
http://<VM-IP>:12345/dolphinscheduler/ui
Default credentials:
- Username:
admin - Password:
dolphinscheduler123
Sample Implementation
This example demonstrates how Flink consumes data from Kafka, packages the job, uploads it to DolphinScheduler, and executes it as a Flink task.
1. Sample Code
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>Flink-Kafka-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<Flink.version>1.18.1</Flink.version>
<scala.binary.version>2.12</scala.binary.version>
<Kafka.version>3.6.0</Kafka.version>
</properties>
<dependencies>
<!-- Flink core dependency -->
<dependency>
<groupId>org.apache.Flink</groupId>
<artifactId>Flink-java</artifactId>
<version>${Flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.Flink</groupId>
<artifactId>Flink-streaming-java</artifactId>
<version>${Flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.Flink</groupId>
<artifactId>Flink-clients</artifactId>
<version>${Flink.version}</version>
</dependency>
<!-- Connector Base Dependency -->
<dependency>
<groupId>org.apache.Flink</groupId>
<artifactId>Flink-connector-base</artifactId>
<version>${Flink.version}</version>
</dependency>
<!-- Kafka Connector (Key Change) -->
<dependency>
<groupId>org.apache.Flink</groupId>
<artifactId>Flink-connector-Kafka</artifactId>
<version>3.1.0-1.18</version>
</dependency>
<dependency>
<groupId>org.apache.Kafka</groupId>
<artifactId>Kafka-clients</artifactId>
<version>${Kafka.version}</version>
</dependency>
<!-- Logging Dependency -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
<scope>runtime</scope>
</dependency>
</dependencies>
<repositories>
<repository>
<id>aliyun</id>
<url>https://maven.aliyun.com/repository/public</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>apache-releases</id>
<url>https://repository.apache.org/content/repositories/releases/</url>
</repository>
</repositories>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>${maven.compiler.source}</source>
<target>${maven.compiler.target}</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.Flink:force-shading</exclude>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
FlinkKafkaConsumerExample.java
import org.apache.Flink.api.common.functions.FlatMapFunction;
import org.apache.Flink.api.java.tuple.Tuple2;
import org.apache.Flink.api.java.utils.ParameterTool;
import org.apache.Flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.Flink.streaming.api.datastream.DataStream;
import org.apache.Flink.streaming.api.functions.ProcessFunction;
import org.apache.Flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.Flink.util.Collector;
import org.apache.Flink.streaming.connectors.Kafka.FlinkKafkaConsumer;
import org.apache.Flink.api.common.serialization.SimpleStringSchema;
import org.apache.Kafka.clients.consumer.ConsumerConfig;
import org.apache.Kafka.common.serialization.StringDeserializer;
import java.util.Properties;
import java.util.concurrent.CompletableFuture;
public class FlinkKafkaConsumerExample {
private static volatile int messageCount = 0;
private static volatile boolean shouldStop = false;
public static void main(String[] args) throws Exception {
// Set the execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Kafka configuration
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.146.132:9092"); // Kafka broker 地址
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "test-group"); // Consumer group
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// Create Kafka Consumer
FlinkKafkaConsumer<String> KafkaConsumer = new FlinkKafkaConsumer<>("test", new SimpleStringSchema(), properties);
KafkaConsumer.setStartFromEarliest(); // Consume from the earliest messages
DataStream<String> stream = env.addSource(KafkaConsumer);
// Process data: tokenization and counting
DataStream<Tuple2<String, Integer>> counts = stream
.flatMap(new Tokenizer())
.keyBy(value -> value.f0)
.sum(1);
counts.addSink(new RichSinkFunction<Tuple2<String, Integer>>() {
@Override
public void invoke(Tuple2<String, Integer> value, Context context) {
System.out.println(value);
messageCount++;
// Check whether the stop condition is met
if (messageCount >= 2 && !shouldStop) {
System.out.println("Processed 2 messages, stopping job.");
shouldStop = true; // Set a flag to indicate that the job should stop
}
}
});
// Execute the job and obtain JobClient
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
try {
// Start the job and obtain JobClient
org.apache.Flink.core.execution.JobClient jobClient = env.executeAsync("Flink Kafka WordCount");
System.out.println("Job ID: " + jobClient.getJobID());
// Monitor the condition and cancel the job
while (!shouldStop) {
Thread.sleep(100); // Check every 100 milliseconds
}
// Cancel the job when the stop condition is met
if (shouldStop) {
System.out.println("Cancelling the job...");
jobClient.cancel().get(); // Cancel the job
}
} catch (Exception e) {
e.printStackTrace();
}
});
// Wait for the job to finish in the main thread
future.join(); // Wait for the job to finish
}
// Tokenizer Class for converting input strings into words
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] tokens = value.toLowerCase().split("\\W+");
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}
2. Package and Upload to DolphinScheduler
3. Create and Run a Flink Task Node
Kafka Producer and Flink Output
Start the Kafka producer in the virtual machine and send messages.
Flink successfully consumes and processes the Kafka data.
[story continues]
tags