
Hi!
I'll start with the phrase:
The entire history of IT has been an attempt to hide from hardware, hiding behind the complexity of the concept. Now we're at a point where IT is returning to hardware.
Before you understand what I'm talking about, I recommend reading my first article. Here’s link:
In short, I created an open-source game engine, Light Acorn, with a unique architecture designed for older PCs and easy for beginners to Rust game development. The engine is based on Macroquad and Bevy ECS (there is also tobj for loading 3D models from Blender).
In the previous article, I described Light Acorn's features, the issues with GPU instancing, and asked for help with its implementation for old hardware.
But while the first article was being moderated (It was published on March 23), I wasn't sitting idle and wasting time solving the problem that was holding back the engine's development: draw calls.
And… I've been solving the problem for 1 week (that's how long the article was under moderation).
The result: 13.000+ Active 3D Entities at 60 FPS on an old 2013 laptop with 35% CPU usage.

Compare with the previous result: 1,300+ entities running at ~28% CPU and 26 FPS

To give you some context on the hardware:
- CPU: i3-3217U — 2 cores / 4 threads, 1.8 GHz max
- RAM: 6GB DDR3 (1600 MT/s vs modern DDR5 ~4800 MT/s)
- Storage: 720GB HDD (5400 RPM)
- GPU: GT 720M — 2GB DDR3, ~192 CUDA cores, 64-bit memory bus
Even most modern integrated graphics outperform this setup.
And yes, this machine has been my daily driver for 13 years.
For comparison, here are some approximate specifications of a modern budget laptop (2026):
- CPU: Intel Core Ultra 3 105UL — 8 cores (2 P-cores + 4 E-cores + 2 LP E-cores for ultra-low power) / 10 threads, 4.2 GHz max
- RAM: 8 or 16GB LPDDR5 (6400 МТ/с)
- Storage: 512 GB NVMe Gen 4 SSD
- GPU: integrated Intel Arc Graphics (but GT 720M is still much weaker)
So, a modern budget laptop is capable of a lot compared to mine. BUT, I was able to make the X550CC feel worthy in its owner's hands.
The most shocking thing for me is not the fact that I squeezed the maximum out of the minimum, but the fact under what conditions I did it and still achieved the desired result.
This article will contain a lot of benchmarks, and not only on old hardware!
I hope you find this interesting, so I'll start with a story.
The Solution
Vertex batching
I already said that the problem is in draw calls, so I started with the obvious approach: vertex batching. Take all acorns, merge them into one giant mesh, and draw with one draw call.
I also modernized the solution: instead of calculating 1 matrix in one function and then drawing 1 mesh --> I divided the function into two: calculating the matrices of all meshes, and then drawing them.
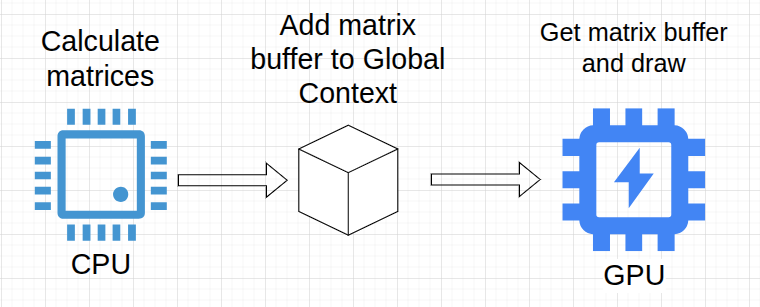
The matrix calculation function first calculates the matrices of all entities, sends a buffer, and then another function receives this buffer and draws it.
It was easy to implement, but I quickly ran into the limits of OpenGL ES 2.0:
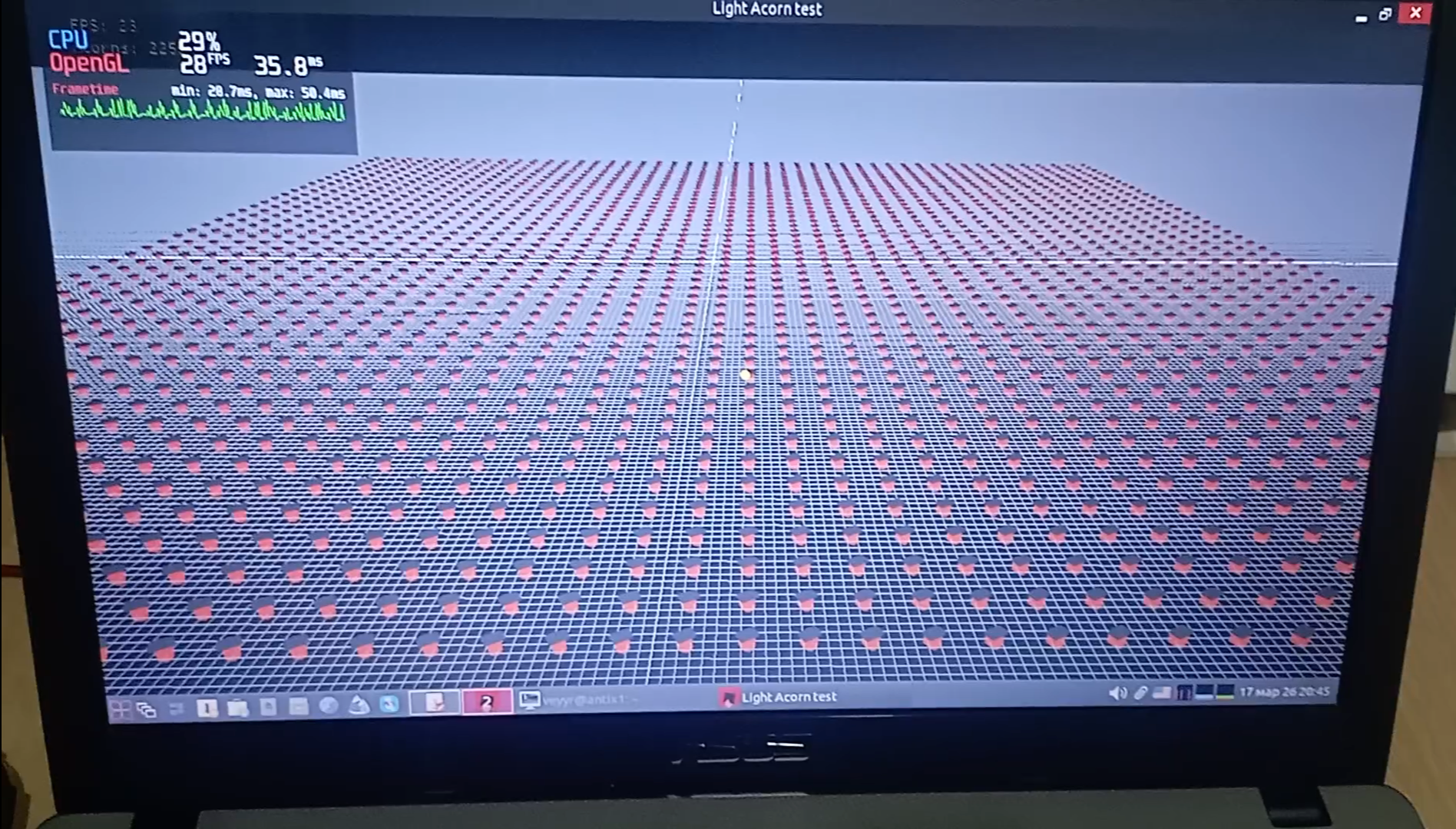
The result: ~2.250 entities at 28 FPS.
I hit the 96KB buffer limit of OpenGL ES 2.0. 2379 vertices. 38 acorns per batch.
Trying to increase the number of acorns in one draw call resulted in a message appearing in the console: geometry() exceeded max drawcall size, clamping
But it wasn't enough. I wanted more.
In any case, I will leave Vertex Batching for those people who can only afford OpenGL ES 2.0
GPU instancing
For reference: GPU instancing is when you send a command to the video card to render your model in multiple positions with just 1 command (1 draw call). The CPU simply passes a buffer of your 3D model positions to the GPU.
At first, I avoided GLSL shaders. I thought vertex batching would be enough. But eventually, I realized I'd have to move mountains, get down to miniquad, and figure out how to write shaders.
I studied GLSL and realized that a shader is simply a command to the GPU. Shaders themselves are divided into vertices (how to draw dots) and fragments (how to paint pixels). The whole point is that the GPU waits for data from the CPU.
I didn't wait for inspiration to write my first shader, so I immediately moved on to practicing in my engine.
Problems arose. The first problem was that the macroquad mesh was not suitable for instancing. This meant storing raw mesh data to pass to miniquad.
I created the following structure:
pub struct AcornPreparedMesh {
pub v_buffer: mq::BufferId,
pub i_buffer: mq::BufferId,
pub index_count: i32,
pub texture: mq::TextureId,
}
And also the structure that stores all these meshes:
pub struct AcornMeshInstanceDB {
pub gpu_meshes: Vec<AcornPreparedMesh>,
}
Next, I needed to write the pipeline. But that was easy too.
To ensure that the 96 KB buffer was not a limitation, I chose OpenGL 3.3, where instancing is the standard.
And the last thing left was to write the shaders:
pub const VERTEX_SHADER_SRC: &str = r#"#version 330 core
layout(location = 0) in vec3 aPos;
layout(location = 1) in vec2 aTex;
layout(location = 2) in vec4 aCol;
layout(location = 3) in vec4 aNormal;
layout(location = 4) in mat4 aModelMat;
uniform mat4 uViewProjection;
out vec2 vTex;
out vec4 vCol;
void main() {
vTex = aTex;
vCol = aCol;
gl_Position = uViewProjection * aModelMat * vec4(aPos, 1.0);
}
"#;
pub const FRAGMENT_SHADER_SRC: &str = r#"#version 330 core
in vec2 vTex;
in vec4 vCol;
out vec4 fragColor;
uniform sampler2D uTexture;
void main() {
vec3 linearColor = vCol.rgb / 255.0;
vec3 finalColor = pow(linearColor, vec3(0.65));
fragColor = vec4(finalColor, 1.0);
}
"#;
Note the linearColor = vCol.rgb / 255.0. This was necessary to normalize the Byte4 data type to Float. Otherwise, the color of the acorns would be burned out, turning black into white and brown into yellow.
Here I've shown a small portion of the code that allowed me to run 13,000 acorns. But the shader code was sufficient for this result. In any case, you can view the entire code in the repository.
I confess, I used AI for mentoring and brainstorming, then adapted the code to fit Light Acorn's architecture.
Edge of The Acorn
After that, I became interested in what the limit of my engine was.
In DEBUG mode on an old laptop, there were 3,000 entities at 30 FPS. But what is the limit in RELEASE mode?
The limit: ~20,000 entities at 50 fps at the same 30-35% load.
https://youtu.be/hZNqd5Cipxk?embedable=true
I didn't increase the number of acorns further, since 50 FPS is already the lowest comfortable threshold for the game.
My confession
I could stop there but… I admit that in fact all this time I had a mid-range PC at home.
Yes, I am creating an engine for weak PCs, even if I have a Ryzen 7 5700X, GTX 1070, 32 GB DDR4 3600 MT/s.
And I became interested in how my engine would behave on modern hardware.
First, let's compare my two friends. Although, to be honest, that's unfair. I could just take the GTX 1070 and compare it to my laptop:
- GTX 1070: 6.5 TFLOPS
- i3-3217u: ~28–30 GFLOPS
- GT 720m: 0.3 TFLOPS
In raw numbers, 6.500 GFLOPS versus 330 GFLOPS is a 20-fold difference, and the GTX 1070 is already more powerful than my entire laptop.
The numbers themselves are already frightening, so let's move on to the benchmarks.
The result: 64.206 entities at 50 fps and 6% CPU load in DEBUG mode.

The next benchmark results in RELEASE mode. The only thing I'll mention is a drop in FPS to 5-7 when changing the number of acorns in DEBUG.
The result: 65.280 entities at 60 fps and 6% CPU load in RELEASE mode.
This is where things get interesting… Instead of boring you with photos, just watch the benchmark video:
https://youtu.be/3A-OBNc7mZY?embedable=true
Overall benchmark results:
- 65,280@60fps 6% CPU usage
- 150,930@60fps 6% CPU usage
- 200.166@60fps 6% CPU usage
- 250.901@50fps 6% CPU usage
The facts:
- The FPS decrease is linear.
- Ryzen 7 5700X hasn't reached its full potential; it's running on one thread (it has 8 cores/16 threads and 4.6 GHz). It literally pulls itself up on the little finger 50 times per second.
- The GTX 1070 is only running at ~60-70% load (1920 CUDA cores). And its RAM is only ~500 MB occupied.
The only downside is the 3.9 RAM occupied. For me, that's a huge number, but I think it's a trade-off for 250,000 active 3D entities. However, if you think about it, 250 thousand is the population of a large city in 1 thread.
The Secret of Optimization
Guess the secret to my optimization? I simply did nothing, and the processor only did useful work. Seriously!
I'll lay out all the facts:
- All transformation matrices (Transition, Scale, Rotation) are calculated exclusively on the processor in 1 thread.
- This runs on OpenGL 3.3 (2010), which only uses 1 CPU thread. No Metal, no Vulkan, just the full power of 2010!
- Light Acorn makes the GPU bottleneck faster, not the CPU.
- The 20,000 Acorns benchmark on an old laptop heated it up to 70 degrees Celsius, even though the thermal paste was dry (I seriously haven't changed the thermal paste for 13 years).
- Everything was done on the REACORN architecture, where you can change the order of functions at runtime (This means that the compiler cannot do aggressive function inlining).
- Each acorn rotates and is an independent unit. This means the processor must run through the list of all acorns and rotate them by 0.1 degrees per frame. (The processor does this 50 times per second!)
- No frustum culling - objects behind the camera are drawn.
- No backface culling - the back sides of triangles are drawn.
- No occlusion culling - objects behind others are drawn.
- No LOD - distant objects draw full geometry even if they are reduced to 3 pixels.
I also had Bevy schedule enabled every frame, but there wasn't a single system there, meaning it was running idle (I forgot to disable it during benchmarks)
If we calculate the "Acorn Power": 250,901 acorns * 50 FPS * 3 Matrix (Translation, Rotation, Scale) = 37,635,150 pure power per second.
Yes, Light Acorn achieved these results with a regular Brute Force. Also, Light Acorn made industry standards like LOD and culling optional (only in this case)!
The Acorn philosophy
You shouldn't compare Light Acorn to benchmarks on Unity, Bevy, or Unreal Engine. It's not because Light Acorn is better or worse, but because it has a different philosophy and different requirements. I appreciate the work of other engines.
Light Acorn's philosophy:
New hardware generations should open doors to greater possibilities, not just serve as a ticket to run increasingly bloated software.
I created this engine to bring simple graphics to life, so I could finally play my own RTS games on this laptop. I'm not trying to make this engine kill Unity or Unreal Engine. I just like the Rust language and want to play.
But even so, Light Acorn demonstrates that:
Good code and architecture no longer require optimization. At least, it makes it optional.
The main advantage of Light Acorn
You might think that Light Acorn has the formula: High performance = High entry barrier
But I already said that it has a low entry barrier.
Light Acorn’s formula is inversely proportional:
High performance = Low entry barrier
In the first article, I already admitted that I'm a beginner learning Rust because of its complexity. Light Acorn itself is built on similarly simple concepts like vectors and loops.
There is a code of Kernel:
pub type AcornFunction = fn(&mut World, &mut AcornZoneContext, &mut AcornGlobalContext);
/// Location is group of functions
pub struct Location {
pub functions: Vec<AcornFunction>,
}
/// Zone is group of Locations
pub struct Zone {
pub locations: Vec<Location>,
}
This code is the quintessence of Acorn. There's nothing superfluous here: no unsafe blocks, smart pointers, or macros.
For example, to draw a circle in the game, you need to write a function:
fn acorn_example_draw_circle(
_world: &mut World,
_zones: &mut AcornZoneContext,
_context: &mut AcornGlobalContext
) {
draw_circle(
screen_width()/2.0,
screen_height()/2.0,
60.0,
BLUE
)
}
And register it:
let after_2d_zone = Zone::default()
.with_locations(vec![
Location::from_fn_vec(vec![
acorn_example_add_circle_function
]),
Therefore, the official requirements to start writing in Light Acorn are 5 chapters of the Rust book. Specifically:
- Variables.
- Data types.
- Functions.
- Structs.
- ECS (It is enough to know how SQL works, since ECS has the same principle).
The last Thing
And also the REACORN architecture, which allows logic to be enabled and disabled at runtime without overhead:
- Disabling certain functions in your logic will not cost the CPU anything, as they are removed from the thread rather than receiving a True/False flag.
- This can be used for dynamic optimization or unique game logic.
- You don't need to recompile the project to test how the world behaves without gravity or friction.
Also, this is a victory over Branch Misprediction!
The Future of Light Acorn
The engine's power is astounding, and its potential even more so. However, Light Acorn is still very much in its infancy. The engine still lacks usable tools, and GPU instancing is still experimental.
Anyway, the engine's foundation has already been laid. Now, Light Acorn is “Proof of Concept”.
Future plans:
- Taffy integration for the UI.
- Optional Shaders for Shadows and Lighting.
- The ability to create not only games but also apps.
- The ability to port to phones.
- Tools for implementing multithreading (in fact, it is already possible, but only manually via std::threads or Rayon)
If you think about it, I've been working on the engine itself for a month. In five hours, I was able to implement vertex batching and GPU instancing. So, give me one month, and then Light Acorn will be suitable for simple games.
My Gratitude
I often say I created this engine alone, but that’s not entirely true.
Light Acorn is the result of a vast ecosystem of brilliant tools and communities. My deepest gratitude goes to:
- Fedor Logachev for Miniquad and Macroquad. I'm grateful for the simplicity of these libraries.
- Carter Anderson and the Bevy contributors. Their ECS is the easiest thing I've learned in programming, and the ability to filter queries using Zero-sized Types is a killer feature.
- Will Usher and contributors of the tobj library for the ability to load 3D models. When I first managed to load a cube into Macroquad, I was very happy.
- Anticapitalista and the antiX community for the wonderful OS. I even installed antiX on a Ryzen 7 5700X.
- Blender Foundation and its contributors for the opportunity to create the engine’s logo.
- The AI assistants who helped me create the engine.
- Hackernoon and its editors for believing in my work and publishing my first article.
In conclusion
Light Acorn has enormous potential for growth. The fact that a single CPU thread can handle a huge number of entities means the rest of the CPU is free for AI, physics, and complex logic.
I can say that 250 thousand entities is not the limit of possibilities, but the beginning.
Light Acorn has the potential to be used for:
- Scientific simulations on a home PC.
- For large-scale Real-Time Strategy games with simple graphics.
- For hardware’s throughput stress testing.
- For prototypes and game jams.
- For unique gameplay due to changing the order of code execution at runtime without overhead.
- For Green IT.
Overall, Light Acorn is a unique combination of:
- Low entry threshold.
- Runtime dynamics.
- Extreme performance.
- Minimalism without heavy graphics.
Light Acorn isn't just software; it's an attempt to restore programmers' sense of the machine that's been lost in the face of stable frameworks.
How to try the power of Light Acorn
I'm sure you'd like to try Light Acorn too. I've put together a guide.
Clone repository and run:
git clone https://github.com/Veyyr3/Light_Acorn.git
cd Light_Acorn
git checkout game_experimental
cargo run --release
Control hint:
- WASD: Move the camera.
- Mouse: Look around.
- E / Q: Increase the acorn grid.
- R: Decrease the grid.
- Z: hide cursor.
- C: show cursor.
If a crash occurs during a test, try increasing the MAX_ACORNS value in main.rs
At the end
By the way, update 0.2.0 was recently released, which made the API more user-friendly.
If you need the GitHub repository itself, here is the link: https://github.com/Veyyr3/Light_Acorn
If you need a clean architecture without Macroquad and tobj, the link is here: https://github.com/Veyyr3/Pure_Acorn
Thanks to everyone who read my article to the end!
[story continues]
tags