Scalability with AI: Lessons from Real Production Systems
Scalability in software engineering used to be a largely solved problem. If your web service was struggling under load, the playbook was straightforward: add more servers behind the load balancer, shard your database, implement some Redis caching, and balance the traffic.
Then, machine learning models entered our synchronous production pipelines—and everything broke.
Scaling is no longer just a hardware problem. It is a multi-dimensional balancing act of latency, cost, reliability, and dynamic model behavior. In this deep dive, I’ll share practical architectural lessons and patterns from scaling production AI systems, complete with the strategies you can apply to your own pipelines today.
The Paradigm Shift: Why Traditional Scaling Fails AI
Before AI, a classic distributed system relied on stateless application servers and centralized storage. The logic was deterministic, latency was predictable, and horizontal scaling was as simple as spinning up more Kubernetes pods. We monitored CPU, memory, and network I/O, and if those were green, the system was healthy.
When you introduce AI—especially large language models (LLMs) or complex deep learning pipelines—into the critical path, the entire paradigm shifts.
Traditional vs. AI Systems
| Metric | Traditional Web Service | AI/ML Inference System |
| Compute Bottleneck | CPU / Network I/O | GPU VRAM / Memory Bandwidth |
| Latency | Predictable (often <50ms) | Highly variable (often >1000ms) |
| Scaling Mechanism | Auto-scale stateless pods | Dynamic batching, model quantization |
| Failure Mode | 500 Server Error | Silent degradation (hallucinations) |
- Inference Latency is Non-Deterministic: Model calls are expensive and highly variable. Generating 10 tokens takes a fraction of the time of generating 1,000, meaning your P99 tail latency becomes a massive bottleneck. You now have to monitor TTFT (Time To First Token) and TPOT (Time Per Output Token).
- Cost Explodes Non-Linearly: In traditional systems, compute is cheap. In AI, GPU and TPU usage grows rapidly with traffic. Serving a heavy transformer model to millions of users daily will destroy your cloud budget if scaled like a traditional microservice.
- State and Drift: Traditional code doesn't "degrade" unless you introduce a bug. AI models degrade silently. As real-world input distributions shift over time, the model's accuracy drops.
Architectural Patterns for AI-Ready Scalability
To survive in production, we cannot rely on brute-force hardware scaling. We need intelligent infrastructure. Here are the core patterns we use to scale AI reliably.
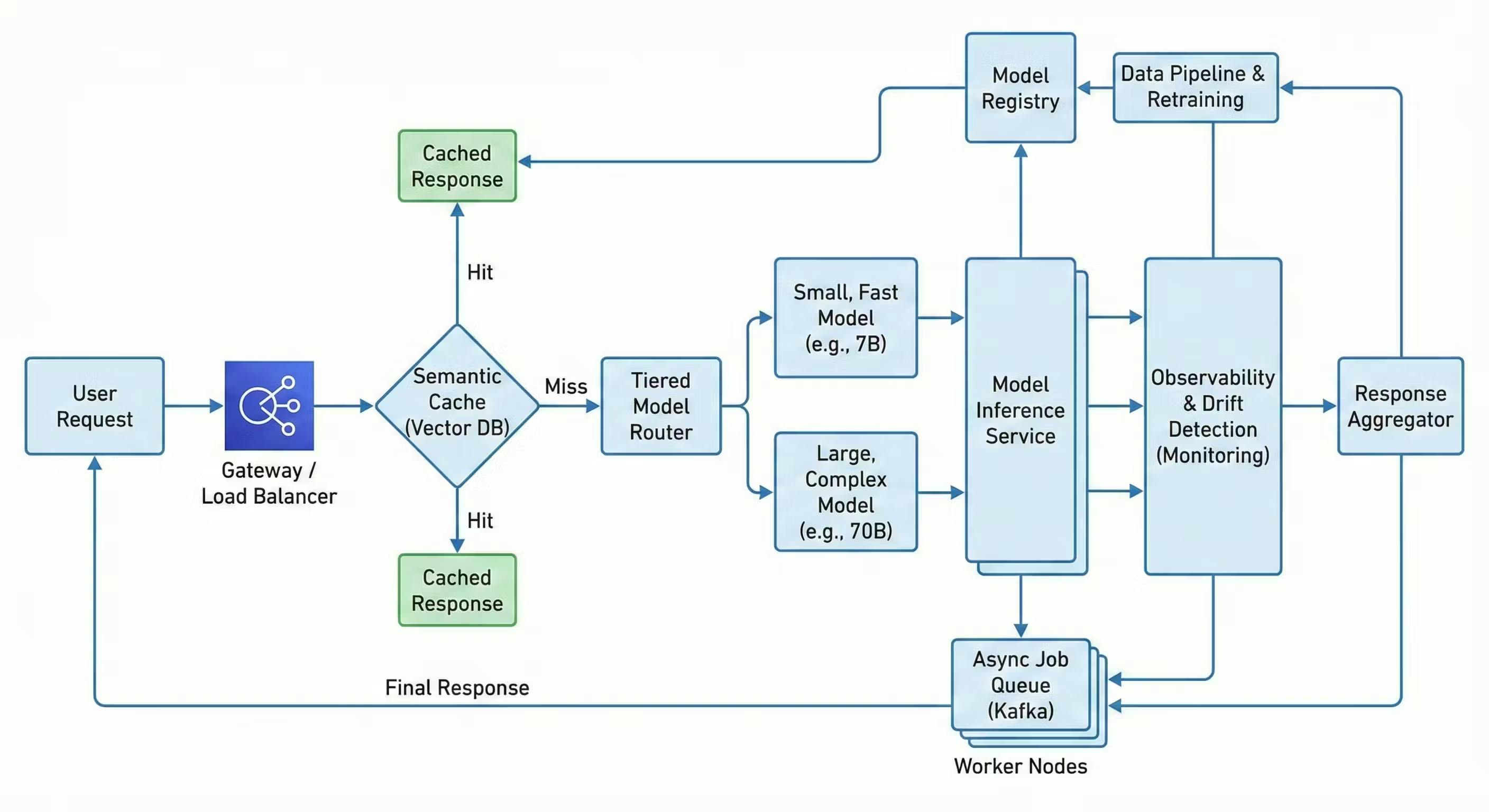
1. The Tiered Model Architecture (Routing for Cost and Latency)
Scaling a massive parameter model for 100% of user traffic is a fast track to bankrupting your infrastructure budget. In production, not all queries require massive computational overhead. The solution is a Tiered Routing Architecture.
Instead of a single monolithic model, we deploy a lightweight semantic router (often a fine-tuned BERT model or a fast zero-shot classifier) in front of a tier of models:
- Tier 1 (The Gatekeeper): A fast, cheap heuristic or highly quantized edge model (e.g., Llama-3 8B quantized to 4-bit). It handles simple requests, standard FAQs, or high-confidence repetitive tasks. Typical Latency: ~50ms.
- Tier 2 (The Heavy Lifter): If the Tier 1 model's confidence score falls below a strict threshold (e.g., < 0.85), or if the router detects complex reasoning requirements, the request is handed off to the larger, more expensive model (e.g., a 70B+ parameter model). Typical Latency: ~800ms+.
At scale, you will often find that 60% to 80% of user traffic can be handled by Tier 1 without any degradation in perceived quality.
2. Asynchronous Inference Pipelines
Never block your main application thread waiting for a heavy model to return a result.
Instead of synchronous REST calls, decouple the client from the inference engine using an event-driven architecture:
- The client sends a request.
- The API Gateway drops the payload into a message broker (like Apache Kafka or Google Cloud Pub/Sub) and immediately returns a
202 Acceptedstatus with a Job ID. - Dedicated GPU worker nodes consume messages from the queue at their own pace, utilizing continuous batching to maximize hardware utilization.
- The result is delivered back to the user via WebSockets, Server-Sent Events (SSE), or long-polling.
This prevents your web servers from dropping connections during complex, long-running generation tasks.
3. Intelligent Semantic Caching
Traditional caching (like Memcached or Redis) relies on exact string matches. In AI, users rarely ask the exact same question twice, but they frequently ask semantically identical questions.
By putting a Vector Database in front of your LLM, you can cache responses based on mathematical meaning. We calculate the distance between the embedded vectors of the incoming query ($\mathbf{A}$) and cached queries ($\mathbf{B}$) using Cosine Similarity:
- A fast, cheap embedding model converts the user's query into a vector.
- We check the Vector DB for a high-similarity match (e.g., $> 0.95$).
- If a match exists, we return the cached response (Latency: 20ms, Cost: almost $0).
- If no match exists, we hit the heavy LLM, generate the response, and cache the new vector-result pair.
4. Graceful Degradation and Dynamic Batching
AI systems must fail safely. When your GPU cluster is saturated during a traffic spike, you cannot afford to have the entire system crash. Implement ML-specific circuit breakers:
- Dynamic / Continuous Batching: Instead of waiting for a fixed number of requests to form a batch, the inference server dynamically injects new requests into the GPU's execution pipeline as soon as previous sequences finish generating their tokens.
- Load Shedding: Dynamically reduce the context window or enforce strict token output limits during high traffic.
- Hard Fallback: If the Tier 2 model is overwhelmed, fall back entirely to the Tier 1 model, or even a static rules-based response ("We are experiencing high volume, please try again in a few moments").
The Observability Stack: Beyond CPU and Memory
In traditional systems, if CPU and Memory are fine, your service is healthy. In AI systems, your infrastructure can be perfectly healthy while your model silently hallucinates or outputs garbage. To scale safely, your observability stack must monitor the statistical behavior of the model in real-time.
- Data Quality & Feature Skew: We monitor the incoming data pipeline. If the input diverges from the training data baseline, we trigger a Feature Skew alert.
- Prediction Drift (Concept Drift): We continuously calculate statistical distances on the model's output predictions to detect silent degradation. For instance, we track the Kullback-Leibler (KL) Divergence between the training distribution $Q$ and the live production distribution $P$:
- If a classification model that historically output 15% "Fraud" suddenly outputs 45% "Fraud," our drift monitors page the on-call ML engineer long before customer support notices.
- Confidence Thresholds: A sudden drop in average model confidence across the board is our fastest leading indicator that user behavior has shifted, requiring an immediate model retraining trigger.
The Scalability Equation
Ultimately, scaling AI is not just about throughput. It is a multi-objective engineering problem. We can define this reality with a simple equation:
Trade-offs are strictly inevitable. Pushing for higher accuracy usually demands larger models, which increases cost and latency. Optimizing for latency might require aggressive quantization, which lowers accuracy. The job of the modern AI engineer is to balance these variables based on the specific business context.
Final Thoughts
Scalable AI systems are the backbone of modern software. The difference between a proof-of-concept that works on a local laptop and a system that serves millions of users is intelligent systems engineering, not just brute-force infrastructure.
Stop treating AI models like standard REST APIs. Architect for failure, cache semantically, route intelligently, and monitor obsessively.