TL;DR —
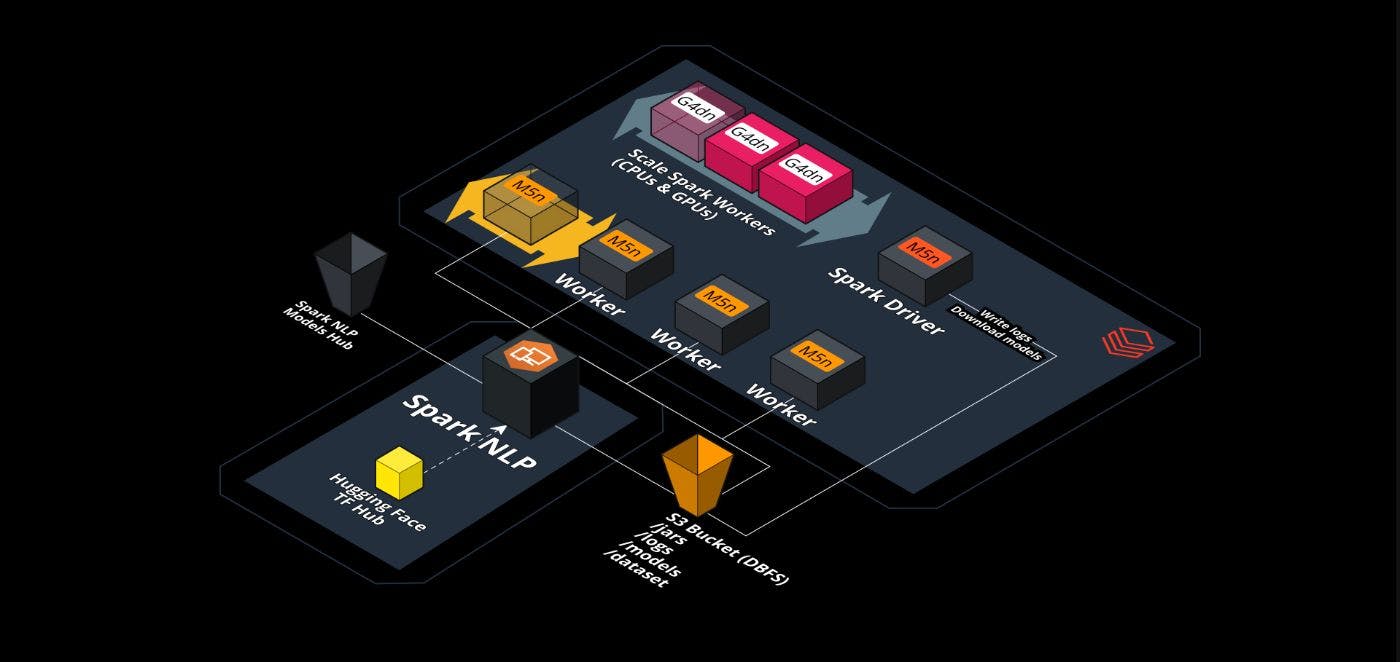
The purpose of this article is to demonstrate how to scale out Vision Transformer (ViT) models from Hugging Face and deploy them in production-ready environments for accelerated and high-performance inference. By the end, we will scale a ViT model from Hugging Face by 25x times (2300%) by using Databricks, Nvidia, and Spark NLP.
[story continues]
Written by
@maziyar
Principal AI/ML Engineer
Topics and
tags
tags
apache-spark|databricks|nlp|transformers|nvidia|pytorch|tensorflow|hackernoon-top-story|hackernoon-es|hackernoon-hi|hackernoon-zh|hackernoon-vi|hackernoon-fr|hackernoon-pt|hackernoon-ja
This story on HackerNoon has a decentralized backup on Sia.
Transaction ID: BXBocvt9d9LEPsYclG78aFybaJOdgkbxKVvZIFmuv9M