Table of Links
X. Conclusion, Acknowledgment, and References
V. OPTIMIZATIONS
In this section, we discuss optimizations that significantly improve the throughput of SCL. Because of the high overhead of various cryptographic operations when constructing DataCapsule fields, we propose an actor-based architecture to pipeline the cryptographic operations. The proposed pipeline also enables high-throughput batching and message prioritization. We discuss our circular buffer, a design that efficiently passes messages across application-enclave boundary.
A. Actors and Batching
For security, one DataCapsule transaction involves encryption, signing and hashing. These cryptographic operations combined introduce large computational overhead to the critical path when the client issues a put. Because frameworks such as Intel SGX SDK [13] and Asylo [21] do not support async operations, SCL introduces actors to amortize the overhead.
When the client issues put(k, v), SCL piggybacks a timestamp t to the key-value pair and pushes the (k, v, t) tuple to a thread-safe Data Queue. The control and coordination messages, such as RTS and EOE, are sent to a thread-safe Control Queue. We call the Data Queue and Control Queue together the Crypto Actor Task Pool. SCL starts multiple
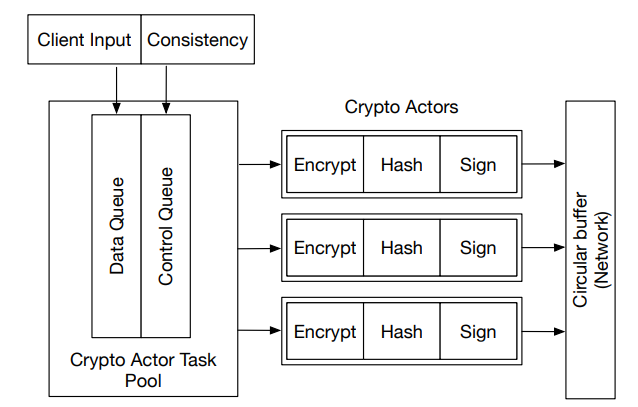
threads as crypto actors. These actors take the messages from the task pool, first drawing from the higher priority Control Queue due to latency constraints, and process them into encrypted, hashed, and signed DataCapsule transactions. The generated DataCapsule records are put into the circular buffer and propagated to other enclaves.
Batching: To optimize the overall throughput and amortize the cost of transmission, SCL can batch multiple key-value pairs in the same DataCapsule record. A crypto actor takes (k, v, t) tuples from the Task Pool. The batch size is the max of the user-preset batch size and the remaining tuples in the task pool. The actor serializes all the control messages and key-value tuples into a Comma-Separated Values (CSV) string and feed into cryptographic pipeline.
B. Circular Buffer
All secure enclave applications are partitioned into trusted enclave code and untrusted application code. The trusted enclave code can access encrypted memory, but cannot issue system calls; the reverse is true for untrusted application code. The boundary of this application-enclave partition is marked by ecalls, and ocalls. In order to transfer the data crossing the application-enclave boundary, a standard and straightforward approach is to invoke ecalls and ocalls directly, which is adopted by popular SGX container framework GrapheneSGX [43], and even enclave runtime environment Asylo [22]. The untrusted application establishes a socket and uses send and recv to pass messages on behalf of the enclave code. However, this approach incurs extremely high overhead. The high cost of a context switch is coupled with byte-wise copying the buffer in and out (contrasted with zero-copying). An ecall usually takes 8,000 to 20,000 CPU cycles, and an ocall usually takes 8,000 CPU cycles on average.
application and enclave by allocating two single-publisher single-consumer circular buffers (one for each communication direction) in untrusted plain-text memory. The memory addresses of the allocated buffers are sent to the enclave by ecalls. The circular buffer contains a number of slots, each of them containing a pointer to the data and its size. Because the enclave allocates and uses encrypted pages on EPC, the outof-enclave application cannot read the content directly given the pointer. SCL allocates and manages several chunks of free plaintext memory and uses pointers to the plaintext memory chunk for the circular buffer.
Using a circular buffer avoids unnecessary ecall and ocall context switches, and, unlike switchless calls [28], the writers also do not need to wait for readers to finish reading the message. This allows the writers to write multiple messages concurrently and asynchronously to the circular buffer.
Authors:
(1) Kaiyuan Chen, University of California, Berkeley (kych@berkeley.edu);
(2) Alexander Thomas, University of California, Berkeley (alexthomas@berkeley.edu);
(3) Hanming Lu, University of California, Berkeley (hanming lu@berkeley.edu);
(4) William Mullen, University of California, Berkeley (wmullen@berkeley.edu);
(5) Jeff Ichnowski, University of California, Berkeley (jeffi@berkeley.edu);
(6) Rahul Arya, University of California, Berkeley (rahularya@berkeley.edu);
(7) Nivedha Krishnakumar, University of California, Berkeley (nivedha@berkeley.edu);
(8) Ryan Teoh, University of California, Berkeley (ryanteoh@berkeley.edu);
(9) Willis Wang, University of California, Berkeley (williswang@berkeley.edu);
(10) Anthony Joseph, University of California, Berkeley (adj@berkeley.edu);
(11) John Kubiatowicz, University of California, Berkeley (kubitron@berkeley.edu).
This paper is
[story continues]
tags