
This is a Plain English Papers summary of a research paper called SemanticGen: Video Generation in Semantic Space. If you like these kinds of analysis, join AIModels.fyi or follow us on Twitter.
The computational wall that video generation hit
Video generation sits at an awkward intersection of scale and complexity. A single image needs to be correct once. A video needs to be correct hundreds of times simultaneously, with every frame flowing naturally into the next, maintaining coherence across time while responding to natural language instructions. Current state-of-the-art models handle this by compressing videos into dense, low-level tokens using a VAE, then training a diffusion model to learn the distribution of those compressed representations. It sounds reasonable in theory, but it creates a problem in practice: even after compression, you're still dealing with thousands of tokens per video. Generating all of them in parallel using attention mechanisms is computationally brutal. The model has to learn everything at once, in one space, all interdependencies resolved simultaneously. It's slow to train and expensive to run.
This is where most approaches have hit a wall. More tokens, more computation. Longer videos, exponentially worse. The intuitive fix is usually to engineer better architectures or faster attention mechanisms. SemanticGen takes a different path entirely.
Planning before rendering
Instead of generating an entire video in one go, what if you first figured out what the video should look like at a high level, then filled in the visual details afterward? This is the core insight driving SemanticGen. Videos are redundant by nature. Much of the information in a video is predictable from high-level semantic content. If you know a cat is jumping from left to right, you already know the rough motion. What remains is the specific textures, lighting, and local details.
This suggests a radically different approach: decompose the problem into two stages. First, generate compact semantic features that capture global structure, what objects are where, how they move. Then, generate detailed visual latents conditioned on those semantic features. The semantic features are far more compact than raw VAE tokens. Fewer tokens to generate means faster training, fewer attention operations, and a fundamentally simpler optimization problem. The second stage can focus on local details without rediscovering global coherence because that's already solved.
The elegant part is that this isn't just theoretically faster, it's actually a cleaner way to think about video generation. You separate the problem of "what should happen" from "what should it look like." That separation makes both problems easier.
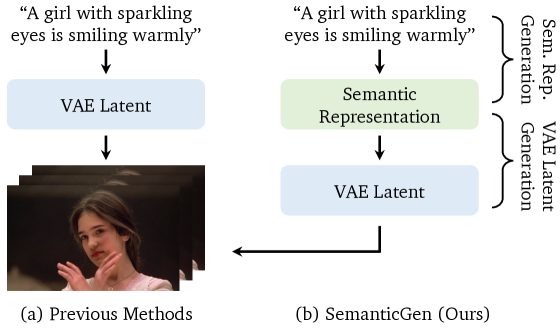
Illustration of the proposed SemanticGen
SemanticGen separates video generation into semantic planning and detail realization
How the two-stage process works
Stage 1: Semantic Foundation
The first stage generates semantic video features extracted from an off-the-shelf semantic encoder. These features already capture meaningful, high-level information about the video content. But SemanticGen compresses them further using a simple neural network. This compression is crucial. Instead of generating 2048-dimensional semantic vectors, the model might generate 64-dimensional or even 8-dimensional vectors. The compression forces the model to discard noise and focus only on what actually matters for final video quality.
A diffusion model learns to generate these compressed semantic features. During generation, it starts from pure noise and iteratively refines it into structured semantic features that match your text prompt and follow the learned distribution from the training data. This stage solves a much simpler problem than full video generation. The model only needs to decide what semantic content the video should contain, working in a compact, high-level space.
Stage 2: Detail Realization
Once semantic features exist, a second diffusion model takes over. This model generates VAE latents (the compressed pixel representation) conditioned on the semantic features from stage 1. The key difference from traditional generation is that it's not generating from scratch. It's generating constrained by the semantic features. The global planning has already happened. This stage doesn't need to rediscover what the video should show. It just needs to realize those semantic decisions in pixel space.
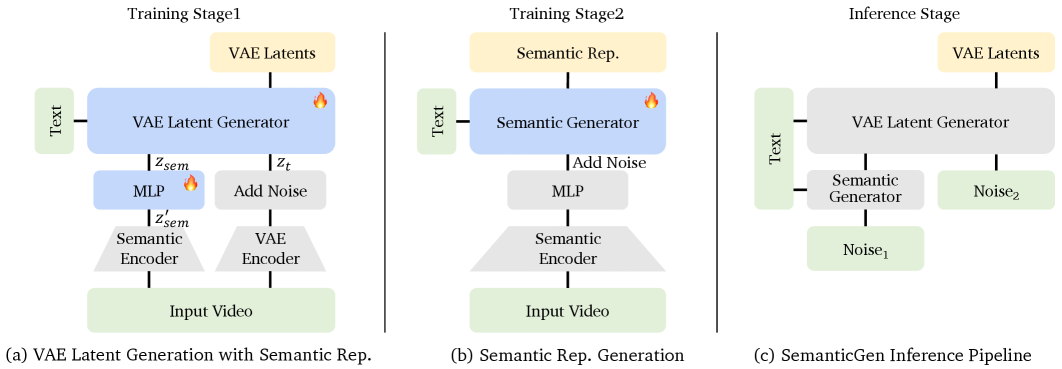
Overview of SemanticGen training process
Two-stage architecture: semantic generation followed by latent diffusion
Scaling without breaking
The real power of SemanticGen emerges when you try to generate longer videos. Current methods face a crushing computational bottleneck. Full attention across video tokens has quadratic complexity, meaning doubling video length quadruples the computation. For videos of meaningful length, this becomes physically impossible.
SemanticGen handles this asymmetrically. In stage 1, the semantic generation uses full attention across all semantic features. This works because semantic features are compact. Even a 10-minute video compressed to semantic space might contain only thousands of tokens instead of millions.
In stage 2, the model uses shifted-window attention (Swin attention), which approximates full attention by computing it only within local windows. This keeps computational cost roughly linear with video length instead of quadratic.
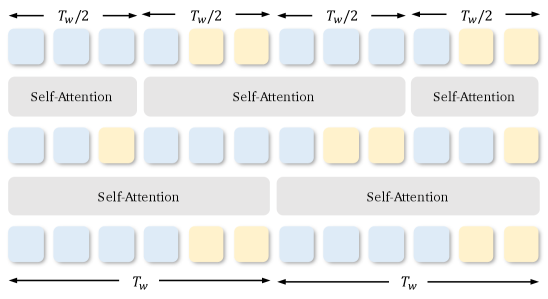
Implementation of Swin-Attention for long video generation
Asymmetric attention: full attention on semantic features, local window attention on VAE latents
This works because stage 1 has already solved the hard problem. The semantic features enforce global coherence across the entire video before any detail generation happens. Stage 2 doesn't need to see the entire video at once because long-range consistency has already been decided at the semantic level. Local detail generation guided by global semantic structure doesn't require expensive long-range modeling.
Evidence that it works
The convergence curve tells the story. When you train a model in semantic space versus training in VAE latent space for the same number of steps, the semantic space model consistently reaches good quality faster. It's not marginal either. The semantic space model reaches comparable quality in substantially fewer iterations. This proves the insight is real: a simpler space leads to faster learning.
On short videos, SemanticGen produces quality comparable to state-of-the-art baselines. More importantly, on long videos, it shows dramatically improved temporal consistency. Many current models suffer from drifting, where the video gradually degenerates or becomes incoherent over many frames. The semantic features prevent this by enforcing consistency across the entire video before details are added.

Comparison of short video generation quality
SemanticGen maintains quality comparable to state-of-the-art methods on short videos

Long video generation showing temporal consistency
Long video generation maintains coherence without the temporal drifting seen in baseline methods
Which parts actually matter
Good research isolates which components drive the results. The paper tests semantic features at different compression levels: full 2048 dimensions, compressed to 64 dimensions, and compressed to 8 dimensions. The results show compression helps, and there's a sweet spot. Too much compression loses important information. Too little compression loses the computational benefits. The compression works because it forces semantic features to be meaningful and focused.

Ablation study on semantic space compression
Compression reduces noise in semantic representations while maintaining essential information
The crucial comparison tests generating in semantic space directly against baseline approaches in compressed VAE latent space, given identical training steps. The semantic space approach converges faster and reaches better quality. This isn't about architectural cleverness. It's about the fundamental space you're generating in. By choosing a better space, you make the generation problem simpler.

Convergence comparison: semantic space versus VAE latent space
Semantic space converges faster to higher quality than VAE latent space with the same training steps
The deeper principle
The insight here extends beyond video generation specifically. Many generative models struggle because they try to model unnecessarily detailed spaces. SemanticGen suggests that the right approach is to hierarchically decompose the problem. Handle high-level meaning first, then low-level details. This is not just more efficient, it's conceptually clearer. You're separating concerns rather than bundling them together.
For long video generation, this shows a path forward that doesn't require revolutionary new attention mechanisms or exotic hardware. Instead, it asks a simpler question: can we generate in a different space that's more amenable to current tools? The answer is yes. This kind of problem reformulation often delivers more impact than incremental engineering improvements.
The method also hints at a more general principle about generative models. Redundancy doesn't need to be brute-forced. If you recognize that much of what you're generating is predictable from high-level structure, you can separate the problems and solve them independently. The first solver constrains the second. Both become easier.
[story continues]
tags