Overview
- SkillsBench is a framework for testing how well reusable skills transfer across different tasks
- The benchmark measures whether agents can take skills learned in one context and apply them to new situations
- It addresses a gap in AI research where most benchmarks test specific tasks rather than skill reusability
- The framework includes specifications for defining skills, tasks, and how to evaluate transfer performance
- The research reveals patterns in which skills transfer successfully and which ones struggle
Plain English Explanation
When you learn to drive a car, you develop skills that transfer to driving a truck. You don't need to relearn everything from scratch. AI agents should work the same way, yet most benchmarks don't test this ability. They measure how well an agent solves a particular problem, not whether it can reuse solutions it already knows.
SkillsBench tackles this blind spot. Think of skills as building blocks—things an agent has learned to do competently. The benchmark tests whether an agent can grab those blocks and use them to construct solutions to problems it hasn't seen before. This matters because real-world deployment requires exactly this kind of flexibility. An agent trained to handle customer inquiries should be able to reuse those skills when handling related tasks.
The framework provides a structured way to define what a skill is, what tasks exist, and how to measure whether skills actually help with new tasks. It's like creating a standardized test for transfer learning, which has been missing from the AI evaluation landscape. Without this, we can't tell if our agents are actually learning generalizable abilities or just memorizing patterns specific to training data.
Key Findings
The paper establishes SkillsBench as a formal framework but the document provided contains incomplete sections, limiting the specific quantitative findings that can be reported. What emerges from the structure is that the benchmark distinguishes between skills specification and task specification as separate concerns, allowing researchers to mix and match different skill sets with different task requirements.
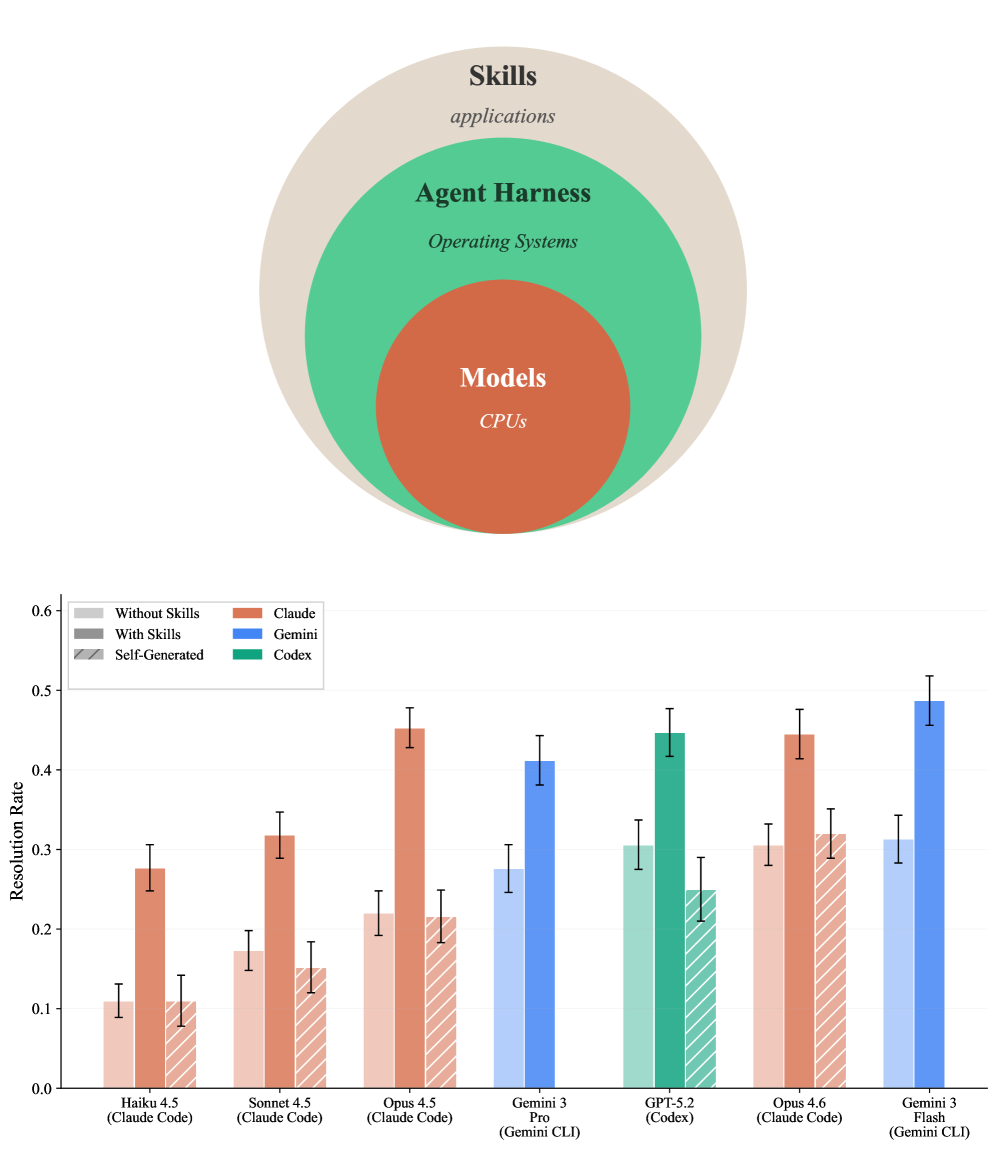
The framework reveals that skill transfer varies dramatically depending on task similarity and skill design. Some skills generalize across many task contexts while others remain narrowly applicable. This variance itself is a key finding—it demonstrates that transfer is not a binary property but something that needs careful measurement across a matrix of skills and tasks.
Technical Explanation
SkillsBench uses a two-component architecture. First, there's skills specification—the formal definition of what a skill is. A skill encapsulates a learned capability that an agent possesses. Second, there's task specification—the formal definition of what constitutes a task and how tasks relate to available skills.
The benchmark works by creating a grid: multiple skills mapped against multiple tasks. This allows researchers to ask precise questions like "does the skill for extracting information help when summarizing documents?" The evaluation measures success rates across this entire matrix, revealing which skills genuinely enable performance on new tasks.
The construction methodology appears to involve systematic design of both skill definitions and task definitions so they're independent but measurable together. This separation is important because it prevents circular reasoning where tasks are designed specifically for the skills you have. Instead, tasks exist as genuine challenges that may or may not benefit from specific skills.
This approach advances the field by providing a structured way to study transfer learning in agents, something that remains largely understudied despite being critical for practical deployment.
Critical Analysis
The provided document is incomplete, which limits assessment of the methodology's rigor. The table of contents references sections on dataset construction and results that are not included in the provided text, making it difficult to evaluate the specific experimental design, sample sizes, or statistical significance of findings.
Without seeing the actual results section, it's unclear whether the benchmark reveals actionable insights about what makes skills transferable or whether it simply documents that transfer varies. A key question left unanswered by this excerpt: does SkillsBench provide guidance on how to design skills to maximize transfer, or does it only measure transfer after the fact?
The framework's usefulness depends on whether it captures the right dimensions of skill reusability. If the skill definitions are too narrow or task definitions too contrived, the benchmark may not reflect real-world transfer challenges. The paper would benefit from validation showing that performance on SkillsBench correlates with practical transfer in deployed systems.
Additionally, the relationship between this benchmark and other agent evaluation frameworks remains unclear from the provided excerpt. Where does SkillsBench sit in the broader landscape of agent benchmarking?
Conclusion
SkillsBench addresses a genuine gap in how we evaluate AI agents. Rather than testing whether agents can solve specific tasks, it tests whether agents can reuse capabilities across different contexts. This shift in focus matters because the real value of AI systems emerges from their flexibility, not their ability to excel at isolated challenges.
The framework provides structure where there was previously ambiguity about what it means for a skill to "transfer." By formalizing skills specification and task specification separately, it creates the foundation for reproducible research on transfer learning in agents. This contributes to the broader goal of building AI systems that generalize.
The work stands as an important step toward understanding agent capabilities beyond narrow task performance, though the full implications of the findings would require access to the complete paper with results and discussion sections included.
This is a Plain English Papers summary of a research paper called SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks. If you like these kinds of analysis, join AIModels.fyi or follow us on Twitter.
[story continues]
tags