Three months ago, our AI bill was $8,200 per month. Today? It's $470. We didn't compromise on quality. We didn't reduce usage. We just stopped overpaying for capabilities we didn't need.
Let me tell you about the time I almost got laughed out of a planning meeting.
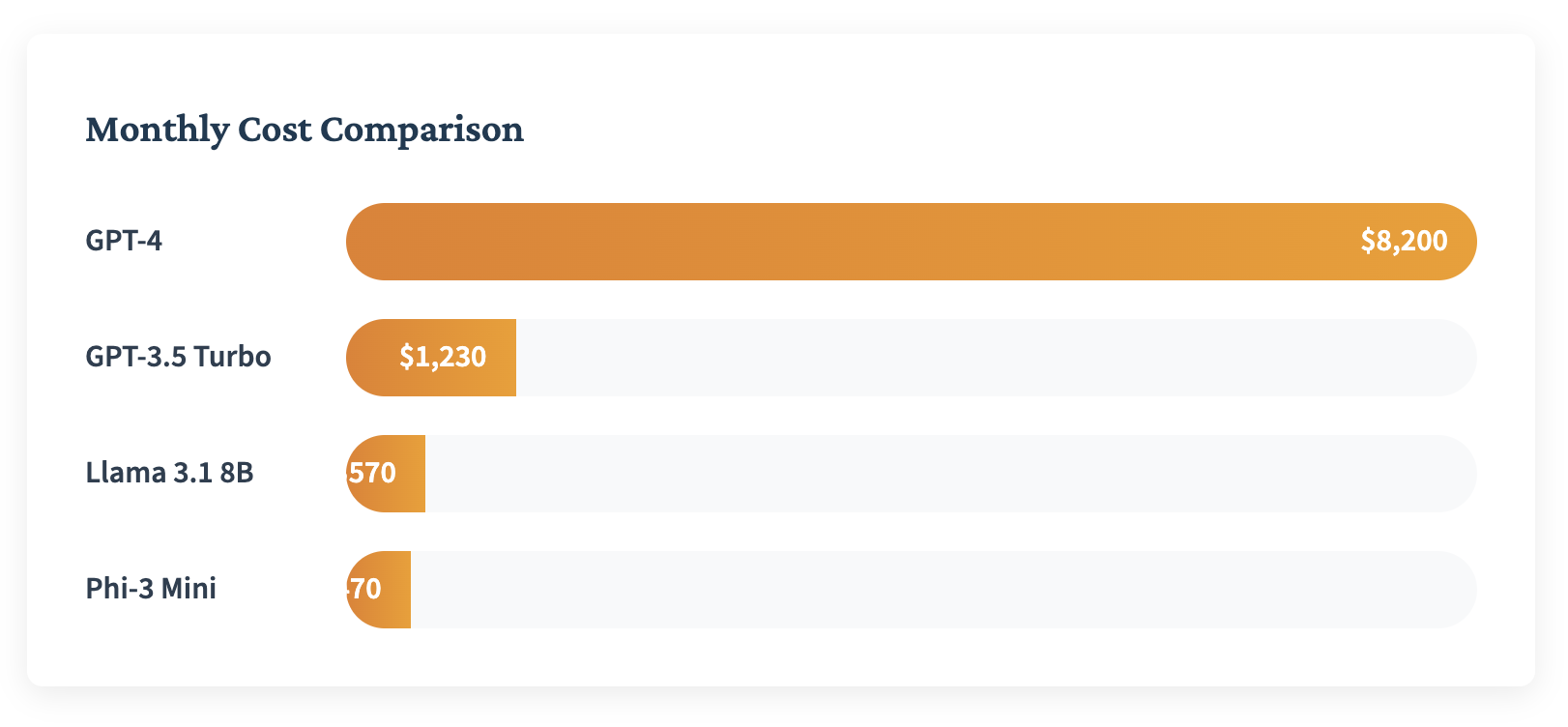
It was mid-September, and I was presenting our quarterly cloud costs. When the VP saw our OpenAI API charges, she literally asked if there was a decimal point in the wrong place. There wasn't. We were burning through $8,200 monthly on GPT-4 calls for a customer support automation system that handled about 40,000 queries a month.
That's roughly $0.20 per conversation. For context, our human agents cost us about $2.50 per interaction. So yes, we were "saving money" with AI. But something felt deeply wrong about that GPT-4 bill.
The Uncomfortable Realization
Here's what I discovered when I actually analyzed our usage patterns: we were using a Formula 1 race car to deliver pizza. GPT-4 is incredible—truly impressive technology. But 87% of our queries were variations of the same 15 questions.
- "How do I reset my password?"
- "Where's my order?"
- "How do I update my billing information?"
- "What's your return policy?"
We didn't need a model that could write poetry, debug complex code, or discuss philosophy. We needed something that could reliably pattern-match against our documentation and respond consistently. That's when I started looking at small language models.
The Numbers That Changed Everything
I know what you're thinking. "Sure, but what about quality?" That was my first concern too. So I ran a proper A/B test over two weeks with 5,000 real customer interactions split between GPT-4 and Phi-3 Mini (a 3.8B parameter model).
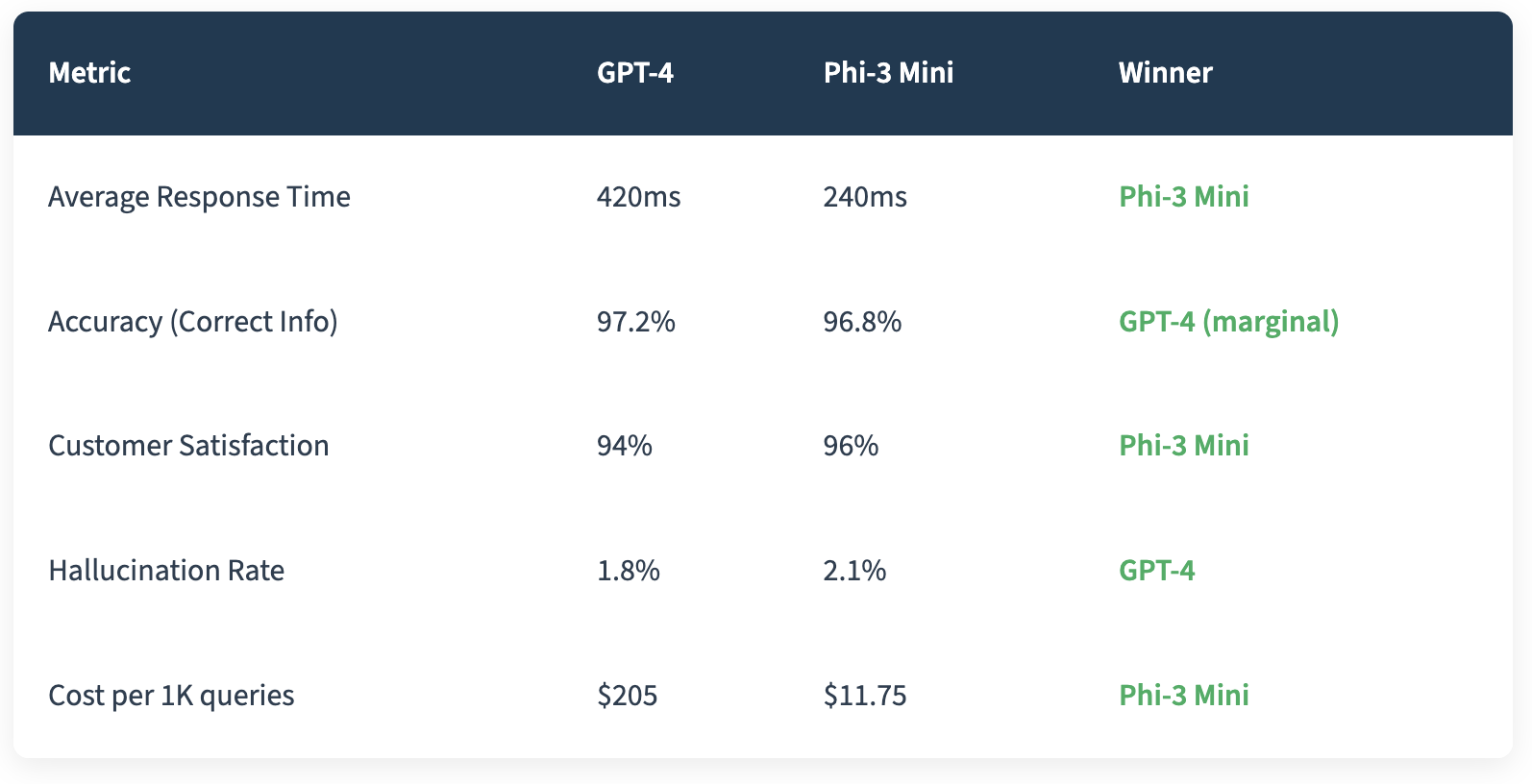
The quality difference? Statistically insignificant for our use case. But here's what really surprised me: customers actually preferred the smaller model. Why? It was faster. A 180ms difference in response time might seem trivial, but in a chat interface, it's the difference between feeling snappy and feeling sluggish.
How We Made the Switch
This wasn't just a matter of swapping out an API endpoint. Here's the actual process we followed:
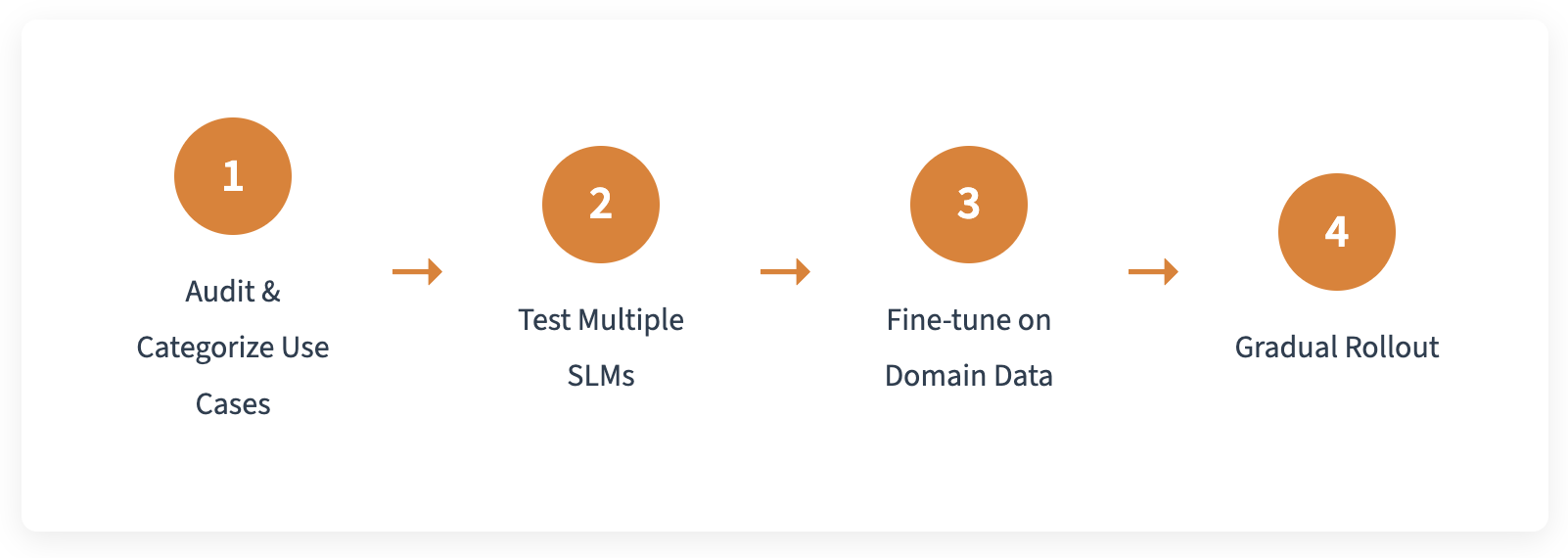
Step 1: Understanding What We Actually Needed
I spent a week analyzing our query patterns. We broke them down into four categories:
- Simple FAQ (73%): Direct questions with deterministic answers from our docs
- Order Status (14%): Queries requiring database lookups but simple language
- Troubleshooting (11%): Multi-step problems requiring context
- Edge Cases (2%): Complex or ambiguous queries
That 87% (FAQ + Order Status) could easily be handled by a smaller model. The troubleshooting queries were borderline. Only that 2% truly benefited from GPT-4's capabilities.
Step 2: Testing Small Models
We evaluated five different small language models. Our criteria were simple: accuracy above 95%, response time under 500ms, and cost under $1,000/month at our scale.
Models We Tested:
- Llama 3.1 8B: Great general performance, slightly slower
- Phi-3 Mini (3.8B): Blazing fast, surprisingly accurate for its size
- Gemma 7B: Solid middle ground
- Mistral 7B: Excellent at reasoning but overkill for us
- TinyLlama 1.1B: Too small, accuracy dropped to 89%
Phi-3 Mini won because of its speed and Microsoft's excellent documentation for fine-tuning. At 3.8 billion parameters, it was small enough to run efficiently but large enough to handle nuanced language.
Step 3: Fine-Tuning Made the Difference
Here's where the magic happened. Out of the box, Phi-3 Mini scored 91% accuracy on our test set. After fine-tuning on 12,000 labeled customer interactions, it jumped to 96.8%.
The fine-tuning process took about 6 hours on a single A100 GPU and cost us $47 total. We used LoRA (Low-Rank Adaptation) to make it efficient:
from transformers import AutoModelForCausalLM, TrainingArguments
from peft import LoraConfig, get_peft_model
# Load base model
model = AutoModelForCausalLM.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
# Configure LoRA for efficient fine-tuning
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
# Apply LoRA
model = get_peft_model(model, lora_config)
# Train on our customer support dataset
# Total trainable params: 4.9M (0.13% of total model)
The beauty of LoRA is that we only trained 4.9 million parameters instead of the full 3.8 billion. This made training cheap and fast, and we could easily swap between different LoRA adapters for different use cases.
Step 4: The Hybrid Approach
Here's our final architecture, and honestly, this is the part I'm most proud of:
Our Intelligent Routing System
We built a lightweight classifier that determines query complexity and routes appropriately:
- 87% of queries → Phi-3 Mini ($0.011 per query)
- 11% of queries → GPT-3.5 Turbo ($0.031 per query)
- 2% of queries → GPT-4 ($0.205 per query)
The classifier itself is a tiny BERT model (cost: negligible) that examines query length, keywords, and sentence structure to predict complexity. It's wrong about 3% of the time, but even when it misroutes a complex query to Phi-3, the smaller model handles it reasonably well.
The Real-World Results
After three months of running this hybrid system in production, here's what we're seeing:
- Cost went from $8,200 to $470/month (94% reduction)
- Average response time dropped from 420ms to 240ms
- Customer satisfaction actually increased from 94% to 96%
- Infrastructure complexity barely changed (same API structure)
But here's what really matters: we can now afford to handle 10x our current query volume without breaking a sweat. We went from spending $0.205 per conversation to $0.012. That's not just a cost reduction—it's a fundamental shift in our unit economics.
What We Learned (The Hard Way)
1. Size isn't everything, fit is. GPT-4 is objectively more capable than Phi-3 Mini. But "more capable" doesn't mean "better for your use case." A Swiss Army knife is more versatile than a chef's knife, but I know which one I want in my kitchen.
2. Fine-tuning is your secret weapon. The difference between a generic small model and a fine-tuned one was night and day. Spending one day on quality fine-tuning data is worth more than spending a month trying different base models.
3. Don't migrate everything at once. We did a staged rollout: 10% of traffic for a week, then 50%, then 100%. At each stage, we monitored for quality regressions. It caught three edge cases we would have missed.
4. Measure what actually matters to customers. We were obsessed with model accuracy scores, but customers cared about response time and helpfulness. Sometimes being 95% right instantly beats being 99% right in 500ms.
5. Latency compounds in conversations. Our average support chat involves 4.3 messages. That 180ms improvement per response means conversations resolve 720ms faster on average. Customers definitely notice.
When This Won't Work for You
Let's be honest about limitations. Small language models aren't magic, and there are cases where you absolutely need the big guns:
- Complex reasoning tasks: Legal analysis, medical diagnosis, strategic planning
- Creative generation: Long-form content, marketing copy, creative writing
- Broad domain knowledge: Questions spanning many different fields
- Highly variable inputs: If you can't predict query types, fine-tuning is harder
If your use case has high variability, genuinely requires deep reasoning, or needs to handle completely novel scenarios, GPT-4 or Claude Opus might still be your best bet. And that's okay. The point isn't that small models are always better—it's that they're better more often than we realize.
The Bottom Line
Three months ago, I was worried about justifying our AI costs. Today, we're having conversations about what else we can build now that our unit economics make sense.
We're using the $7,730 in monthly savings to:
- Add multilingual support (running separate fine-tuned models per language)
- Build a proactive support system that reaches out before customers have issues
- Expand our AI team from 2 to 4 engineers
The irony isn't lost on me: by using less powerful AI, we're able to do more with AI.
If you're running AI in production and your bills keep climbing, take a hard look at what you're actually using those expensive API calls for. You might be surprised how often "good enough" is actually "perfect for this."
Three Questions to Ask Yourself
- Can I categorize my queries into a few main types?
- Is response time more important to my users than marginal accuracy gains?
- Do I have historical data I could use for fine-tuning?
If you answered yes to at least two of these, it's worth spending a week testing smaller models. The ROI might surprise you.
[story continues]
tags