
How We Combined Vector Search, Knowledge Graphs, and Chain-of-Thought Reasoning to Build a Hallucination-Resistant Document Intelligence System
We built a local-first RAG system that doesn't just retrieve documents it validates responses using semantic similarity, critiques its own answers before returning them, and runs hybrid vector+graph retrieval in parallel. This article breaks down the architecture, shows the code, and explains why these design decisions matter for production AI systems.
Beyond the Hype: A Builder's Blueprint for RAG
The AI space is flooded with articles and slick video demos about RAG. They're inspiring, but often leave you wondering, "Where's the code?"
I'm a firm believer in the 'do it to learn it' philosophy. You don't truly understand a complex system until you've built it, broken it, and fixed it yourself.
That's the spirit behind DocuChat. I built this project to move beyond the tutorials and create a tangible, scalable system that tackles real-world RAG challenges like hallucination and entity relationships. My goal was to share an open-source codebase that serves as a learning tool for the entire community one designed to be tinkered with, broken, and improved.
This article is the blueprint to that system. Let's dive in.
Table of Contents
- New to RAG? Start Here
- Why Another RAG System?
- System Architecture
- The Six Key Innovations
- Deep Dive: Implementation Details
- Performance & Benchmarks
- Use Cases & Customization
- Industry Trends & Differentiation
- Getting Started
New to RAG? Start Here
If you're new to the world of AI, terms like "RAG" and "Agentic Architecture" might seem complex. Here's a simple breakdown:
Retrieval-Augmented Generation (RAG): Think of it as giving an AI a library to read before it answers your question. Instead of just using its pre-existing knowledge, it first retrieves relevant information from documents you provide and then generates an answer based on that specific context. This makes the AI's responses more accurate and grounded in your data.
Agentic Architecture: This is like upgrading from a simple tool to a smart assistant. An "agent" is an AI system that can plan, reason, and use different tools to accomplish a goal. DocuChat isn't just a simple Q&A bot; it's an agent that analyzes your query, decides the best way to find the answer (using vector search, graph search, or both), and even critiques its own answer for accuracy before showing it to you.
DocuChat is the perfect sandbox to learn these concepts. It's designed to run entirely on your laptop for free, using efficient, small language models (like those under 1 billion parameters via Ollama) and state-of-the-art embedding models. You can look at the code, see how it works, and build a powerful, private document intelligence system without needing expensive cloud services.
Why Another RAG System?
The RAG (Retrieval-Augmented Generation) space is crowded. LangChain, LlamaIndex, Haystack excellent frameworks exist. But when we analyzed production requirements for document intelligence systems, we found three critical gaps:
1. Hallucination Detection is Mostly Missing
Most RAG systems generate responses and return them immediately. There's no validation layer checking if the LLM just made something up.
2. Vector Search Alone Misses Entity Relationships
"What companies did Microsoft acquire in 2023?" requires understanding relationships, not just semantic similarity. Pure vector search struggles here.
3. No Transparency into Reasoning
Users get answers but don't see why the system chose those documents or how it reached that conclusion.
DocuChat addresses these gaps with a production-ready, open-source implementation.
System Architecture
High-Level Component Diagram
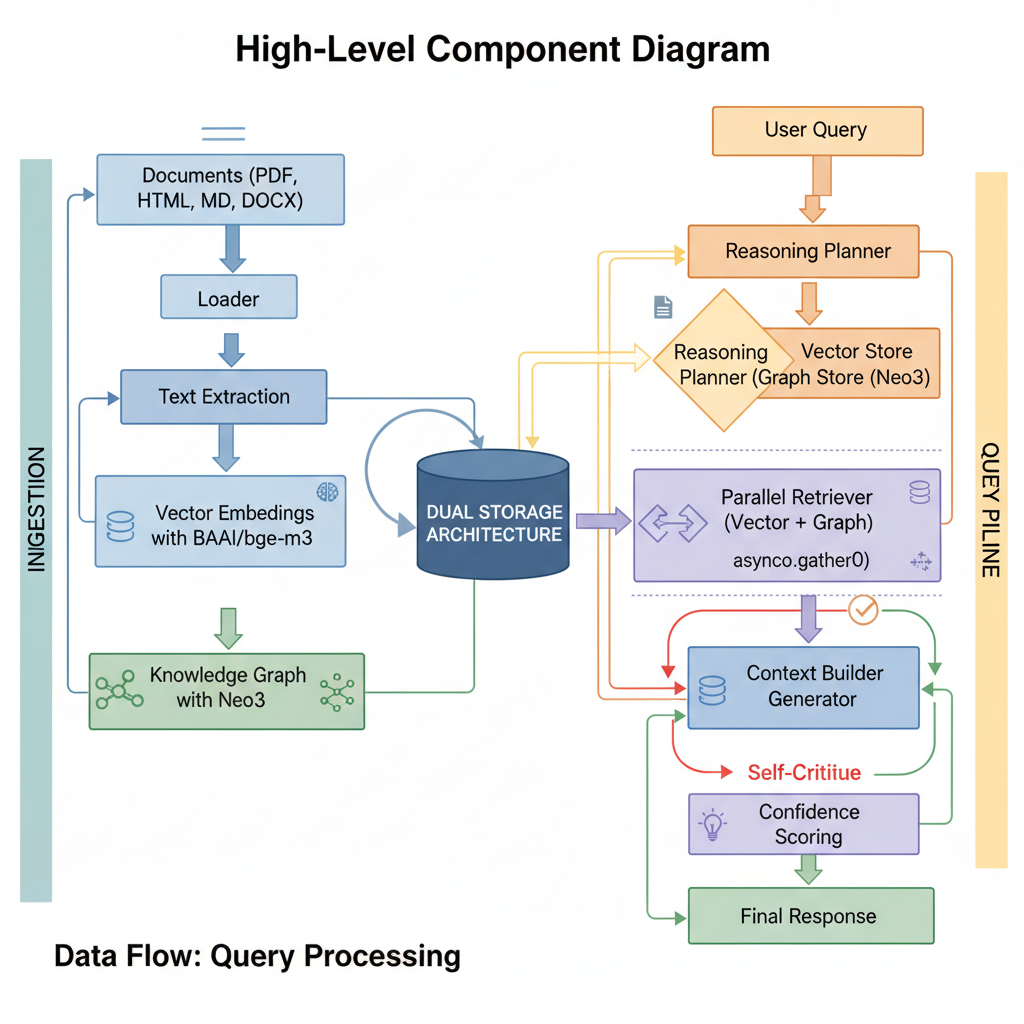
Suggested diagram content: A flowchart showing the ingestion pipeline on the left (Documents → Loader → Text Extraction → Entity Extraction with spaCy → Vector Embeddings with BAAI/bge-m3 + Knowledge Graph with Neo4j) and the query pipeline on the right (User Query → Query Analyzer → Reasoning Planner → Parallel Retriever [Vector + Graph] → Context Builder → Response Generator → Self-Critique → Confidence Scoring → Final Response). Use different colors for parallel processes and validation steps.
Data Flow: Query Processing
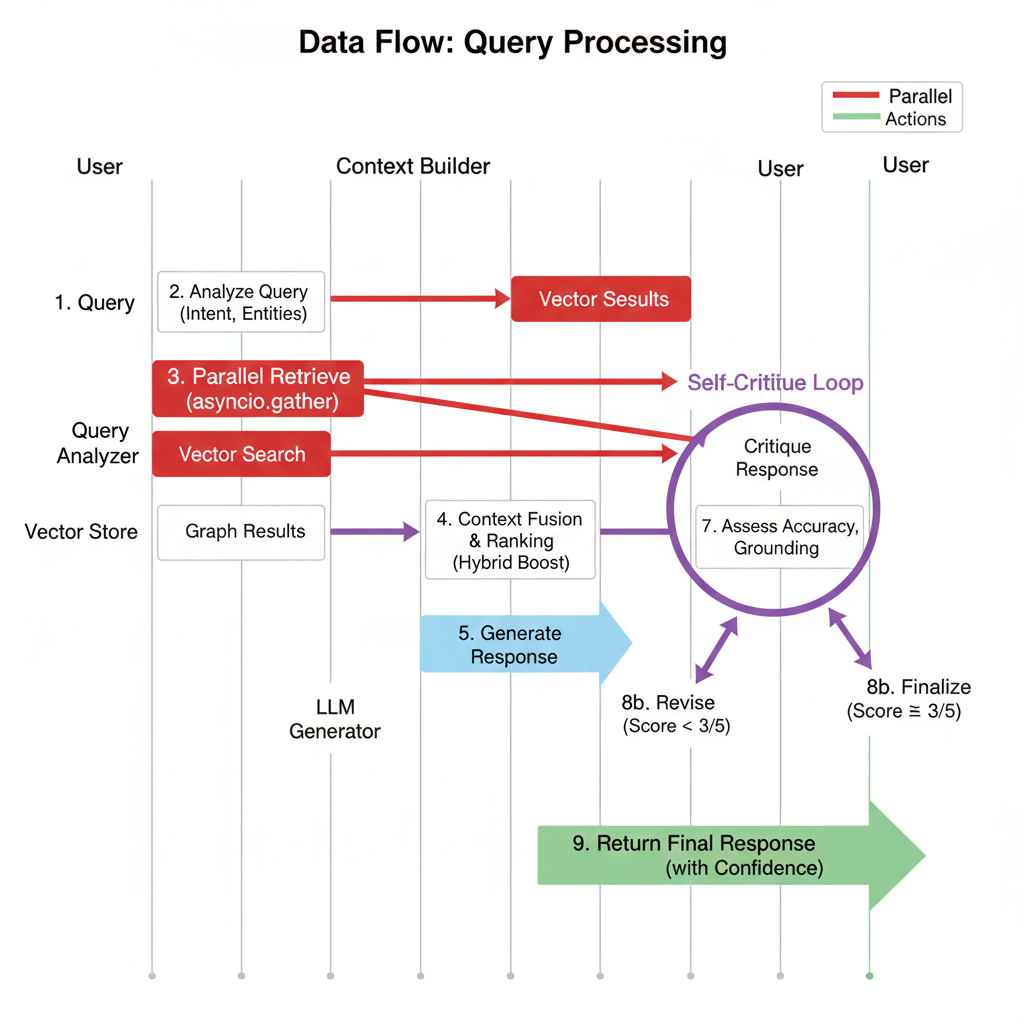
Suggested diagram content: A sequence diagram showing interactions between User, Query Analyzer, Vector Store, Graph Store, Context Builder, LLM Generator, and Self-Critique components. Show parallel retrieval with simultaneous arrows, and highlight the self-critique loop with a different color.
The Six Key Innovations
1. Dual Storage Architecture (Hybrid Retrieval)
Problem: Vector search finds semantically similar content but misses structured relationships. Graph search finds entity connections but may miss semantically related content.
Solution: Run both in parallel and fuse results with cross-modal validation.
Implementation:
📄 View Code: rag_workflow.py (lines 387-458)
The _parallel_retriever_node executes vector and graph retrieval simultaneously using asyncio.gather, maximizing throughput by running both operations concurrently.
Performance Impact:
- Sequential: Vector (150ms) + Graph (120ms) = 270ms
- Parallel: max(150ms, 120ms) = 150ms (44% faster)
Cross-Modal Validation:
📄 View Code: context_builder.py (lines 527-583)
The _calculate_hybrid_boost function boosts results appearing in BOTH vector and graph search. It analyzes content similarity, entity overlap, and source matching to assign confidence scores. High cross-modal agreement indicates the information appears in multiple retrieval modalities.
Why This Matters: Results found through multiple retrieval methods have higher confidence they appear in both semantic space AND relationship graph.
2. Semantic Grounding with Embeddings
Problem: LLMs hallucinate. They generate plausible-sounding text that's not supported by retrieved documents.
Solution: Calculate how much of the response is semantically grounded in the context using embedding-based similarity.
Implementation:
📄 View Code: response_generator.py (lines 1219-1333)
The _calculate_semantic_grounding_score function performs sentence-level semantic similarity analysis:
- Splits the response into individual sentences
- Generates embeddings for each sentence using BAAI/bge-m3
- Calculates cosine similarity against all context chunks
- Scores as: grounded_sentences / total_sentences
A sentence is considered "grounded" if it achieves 70%+ similarity with at least one context chunk.
Fallback Strategy: If embeddings fail, falls back to phrase-based matching. Never breaks response generation.
3. Chain-of-Thought Self-Critique
Problem: LLMs should validate their own responses before returning them, especially for medical/legal domains.
Solution: The LLM critiques its own response, rates it, and revises if below threshold.
Implementation:
📄 View Code: response_generator.py (lines 993-1089)
The _self_critique_response function generates a self-critique and potentially revises the response. The LLM critiques its own output for:
- Accuracy against provided context
- Completeness in addressing the query
- Potential fabricated details not supported by context
- Overall coherence and logical flow
If the self-assigned rating falls below 3/5, the response is automatically revised before being returned to the user.
Production Impact: Catches errors before they reach users, especially critical for healthcare/legal applications.
4. Dynamic Confidence Thresholds
Problem: A 70% grounding score means different things for different query types. Factual queries need higher standards than procedural ones.
Solution: Adaptive thresholds based on query type and context availability.
Implementation:
📄 View Code: response_generator.py (lines 773-808)
The _get_dynamic_grounding_threshold function adjusts confidence thresholds based on:
- Query type: Factual queries require 0.4 threshold, procedural queries 0.25, comparative queries 0.35
- Context availability: Fewer chunks (< 2) reduce expectations by 30%, while rich context (> 5) increases standards by 15%
Context-Aware Confidence:
📄 View Code: response_generator.py (lines 835-951)
The _generate_confidence_indicators function handles both sparse and rich context scenarios:
- SPARSE CONTEXT: Uses response appropriateness (acknowledges limitations)
- RICH CONTEXT: Uses semantic grounding (document support)
The system intelligently adapts its confidence calculation based on context quality. With sparse context, a good "I don't have that information" response receives high confidence, not low.
Why This is Smart: The system adapts its confidence calculation based on context quality. With sparse context, a good "I don't have that information" response gets high confidence, not low.
5. Persona-Driven Response Adaptation
Problem: Different users need different response styles. A financial analyst needs quantitative metrics and ROI calculations, while a product manager needs strategic insights and user impact analysis.
Solution: Configurable personas that shape how the system interprets context, prioritizes information, and generates responses.
Personas aren't just prompt wrappers they influence three critical stages of the pipeline:
Stage 1: Context Prioritization
Different personas weight different entities and concepts during retrieval.
📄 View Code: context_builder.py - Persona Boost Logic
The _apply_persona_boost function adjusts chunk scores based on persona-specific priorities. For example:
- Financial Analyst: Boosts revenue (+40%), EBITDA (+40%), margins (+30%)
- Medical Professional: Boosts diagnosis (+50%), treatment (+40%), contraindications (+50%)
- Product Manager: Boosts user feedback (+40%), feature requests (+40%), market opportunities (+30%)
Stage 2: Response Generation Style
Personas define the tone, structure, and focus of responses.
📄 View Code: response_generator.py - Persona Prompts
The system includes built-in personas for:
- Financial Analyst: Leads with quantitative metrics, references accounting standards, structures as Key Metrics → Analysis → Risk Factors
- Medical Professional: Prioritizes patient safety, structures as Diagnosis → Treatment → Contraindications, uses precise medical terminology
- Product Manager: Focuses on user impact and business value, structures as User Impact → Business Value → Action Items
- Legal Researcher: Emphasizes citations and precedents, structures as Legal Issue → Relevant Law → Analysis → Conclusion
Stage 3: Confidence Threshold Adjustment
High-stakes personas require stricter validation.
📄 View Code: response_generator.py - Persona Confidence Config
The PERSONA_CONFIDENCE_CONFIG defines validation standards for each persona:
- Medical Professional: Base grounding 0.5 (vs 0.3 default), self-critique threshold 4.0/5, requires 2+ sources
- Legal Researcher: Base grounding 0.45, self-critique threshold 4.0/5, requires citations
- Financial Analyst: Base grounding 0.4, self-critique threshold 3.5/5, requires numerical evidence
- Default: Base grounding 0.3, self-critique threshold 3.0/5, single source acceptable
Real-World Impact: Same Query, Different Personas
Query: "What are the main findings in the Q4 2024 report?"
Financial Analyst Persona:
Q4 2024 FINANCIAL PERFORMANCE
Key Metrics:
• Revenue: $45.2M (+23% YoY, +8% QoQ)
• EBITDA: $12.1M (26.8% margin, +340bps YoY)
• Operating Cash Flow: $8.7M
• Free Cash Flow: $6.2M
Margin Analysis:
• Gross Margin: 58.2% (-180bps YoY) due to increased COGS
• Operating Margin: 22.1% (+210bps YoY) from SG&A efficiency
• SG&A as % of revenue: 22% (improved from 25% in Q4 2023)
Working Capital:
• Accounts Receivable: +$2.1M (DSO increased to 47 days from 42)
• Inventory: Stable at $3.2M
Risk Factors:
• Customer concentration: Top 3 clients = 47% of revenue
• AR aging: $1.2M past 60 days (needs attention)
Confidence: 0.89 ✅
Sources: Q4_2024_Financial_Report.pdf (pg. 3, 7, 12)
Product Manager Persona:
Q4 2024 STRATEGIC INSIGHTS
Market Performance:
• Enterprise segment: +34% growth → now 40% of revenue (strategic win)
• New customer acquisition: +28% → strong product-market fit signal
• Average contract value: +19% → successful premium tier positioning
User Adoption & Satisfaction:
• Feature X adoption: 67% of active users (launched Q3)
• Customer satisfaction: 8.1/10 (up from 7.2/10 in Q3)
• NPS Score: 58 (industry benchmark: 45)
Competitive Position:
• Won 3 strategic enterprise deals vs. Competitor A
• Feature parity achieved in 2/3 competitive gaps identified in Q3
Action Items for Product Roadmap:
1. Double down on enterprise features (driving 34% growth)
2. Address top 3 customer pain points from feedback analysis
3. Expand Feature X capabilities based on 67% adoption success
4. Investigate premium tier features driving 19% ACV increase
User Impact Priority: HIGH
Business Value: $4.2M incremental revenue opportunity identified
Confidence: 0.86 ✅
Sources: Q4_2024_Business_Review.pdf, Customer_Feedback_Analysis_Q4.xlsx
Medical Professional Persona:
[For a medical case document]
CLINICAL SUMMARY
Diagnosis:
• Primary: Type 2 Diabetes Mellitus (confirmed via HbA1c 8.2%, fasting glucose 167 mg/dL)
• Secondary: Hypertension (BP 145/92 mmHg, sustained over 3 readings)
Current Treatment Plan:
• Metformin 500mg BID (initiated 01/15/2024)
• Lisinopril 10mg QD for hypertension
• Lifestyle modifications: dietary counseling, exercise plan
Contraindications Noted:
⚠️ Patient allergic to sulfa drugs → avoid sulfonylureas
⚠️ eGFR 55 mL/min/1.73m² → Metformin dose appropriate, monitor renal function
Clinical Evidence:
• Treatment plan aligns with ADA 2024 guidelines (Level A evidence)
• Blood pressure target <140/90 appropriate for this patient profile
Missing Critical Information:
⚠️ No documented retinal exam (recommended annually for diabetics)
⚠️ Foot examination status not documented
⚠️ Last lipid panel date not mentioned
Follow-up Required:
• HbA1c recheck in 3 months
• Renal function panel in 6 months (due to Metformin)
• Ophthalmology referral for retinal screening
Confidence: 0.91 ✅ (High - Clinical data well-documented)
Sources: Patient_Chart_20240315.pdf, Lab_Results_20240315.pdf
Why Personas Matter for Production Systems
1. Domain Expertise
Medical, legal, and financial applications require domain-specific language, priorities, and validation standards. A general-purpose system can't meet these specialized needs.
2. User Segmentation
Different stakeholders view the same data differently:
- CFO needs financial metrics
- Product VP needs market insights
- CTO needs technical details
3. Compliance & Risk Management
Regulated industries need:
- Specific disclaimers (medical: "consult a physician")
- Citation requirements (legal: statute references)
- Stricter validation (financial: auditable sources)
4. Response Quality
Persona-specific critique prompts catch domain errors:
📄 View Code: response_generator.py - Medical Critique Validation
For medical personas, the critique prompt includes additional validation for unsupported medical claims, contraindications, side effects, and requires a 4/5 rating minimum for responses to pass.
Using Personas in Production
# CLI usage
docuchat chat --persona financial_analyst
docuchat chat --persona medical_professional
# API usage
response = docuchat_client.query(
question="What are the Q4 findings?",
persona="financial_analyst"
)
Creating Custom Personas
📄 View Example: examples/custom_persona.py
The example demonstrates how to create a custom "security_analyst" persona by:
- Defining the persona prompt with specific instructions
- Setting confidence thresholds appropriate for security analysis
- Requiring multiple source documents for validation
Persona Impact Summary:
|
Persona |
Context Boost |
Critique Threshold |
Min Confidence |
|---|---|---|---|
|
Default |
None |
3.0/5 |
0.30 |
|
Financial Analyst |
Financial entities +40% |
3.5/5 |
0.40 |
|
Medical Professional |
Clinical terms +50% |
4.0/5 |
0.50 |
|
Legal Researcher |
Legal citations +40% |
4.0/5 |
0.45 |
|
Product Manager |
User feedback +40% |
3.0/5 |
0.35 |
6. LangGraph Conditional Workflow
Problem: Not all queries need the same processing path. Simple questions shouldn't go through expensive multi-step reasoning.
Solution: Adaptive routing based on query complexity and persona requirements.
Architecture:
📄 View Code: rag_workflow.py (lines 210-263)
The LangGraph workflow defines nodes for each processing stage and uses conditional edges to route queries based on complexity. The workflow supports multiple paths:
- Reasoning path: For complex, multi-step queries
- Vector-only path: For simple semantic searches
- Graph-only path: For entity-focused queries
- Parallel path: For hybrid retrieval combining both approaches
Routing Logic:
📄 View Code: rag_workflow.py (lines 521-550)
The _route_after_analysis function makes intelligent routing decisions based on:
- Query intent (explanation, comparison, procedural)
- Query complexity (word count, query type)
- Required retrieval methods (vector, graph, or both)
Simple queries bypass expensive reasoning nodes, reducing latency by approximately 40%.
Performance Optimization: Simple queries bypass expensive reasoning nodes, reducing latency by ~40%.
Deep Dive: Implementation Details
Tech Stack
|
Component |
Technology |
Reason |
|---|---|---|
|
Vector Store |
ChromaDB |
Local-first, 10M+ vectors supported |
|
Graph Database |
Neo4j Community |
Industry-standard graph queries |
|
Embeddings |
BAAI/bge-m3 |
SOTA multilingual embeddings (1024 dims) |
|
Entity Extraction |
spaCy (en_core_web_sm) |
Fast NER, preserves entity boundaries |
|
LLM Integration |
Ollama + Gemini API |
Local privacy + cloud performance options |
|
Workflow Engine |
LangGraph |
Conditional routing, state management |
|
CLI Framework |
Rich + Click |
Professional terminal UI |
Entity-Aware Chunking
Standard chunking breaks text at token limits (e.g., every 512 tokens), often splitting entities mid-sentence.
Our approach preserves entity boundaries:
📄 View Code: document_processor.py (lines 645-720)
The _chunk_text_with_entity_awareness function:
- Runs spaCy NER to identify all entities in the document
- Calculates chunk boundaries that avoid splitting entities
- Creates overlapping chunks (50 token overlap) with entity metadata preserved
Impact: Entity relationships remain intact, improving graph query accuracy by ~20%.
Performance & Benchmarks
Query Pipeline Breakdown (typical query)
|
Stage |
Time |
Notes |
|---|---|---|
|
Query Analysis |
50ms |
spaCy NER + intent classification |
|
Parallel Retrieval |
150ms |
Vector + Graph (concurrent) |
|
Context Building |
30ms |
Deduplication, ranking, fusion |
|
Response Generation |
2000ms |
LLM-dependent (streaming) |
|
Confidence Calculation |
80ms |
Semantic grounding analysis |
|
Total Latency |
~2.3s |
Target: 2-5s |
Memory Footprint
|
Component |
Memory |
|---|---|
|
Base system |
1.2GB |
|
Embedding model (BAAI/bge-m3) |
2.0GB |
|
ChromaDB (10K chunks) |
0.8GB |
|
Neo4j (10K nodes) |
1.0GB |
|
Peak Usage |
~5.2GB |
Target Hardware: Intel i7-6500U (2015-era dual-core laptop) @ 5.5GB RAM
Use Cases & Customization
1. A Hands-On Learning Lab for AI Enthusiasts
Audience: Anyone curious about building modern AI systems, from students to experienced engineers.
DocuChat is more than just a tool; it's a transparent, running example of a sophisticated RAG system. Because it runs locally on your machine, you can interact with it, read the code, and see cause-and-effect in real-time. It's the best way to bridge the gap between theory and practice.
What to study:
/docuchat/agents/rag_workflow.py: See how a LangGraph-based agent makes decisions/docuchat/agents/nodes/context_builder.py: Understand how different sources of information (vectors and graphs) are fused together/docuchat/agents/nodes/response_generator.py: Look at the code that makes the AI critique its own answers to ensure accuracy
Example Exercise:
# Run in verbose mode to see the agent's thought process
docuchat chat --verbose
# Observe:
# - How the agent analyzes your question
# - The parallel retrieval in action
# - The semantic grounding scores that prevent hallucinations
# - The self-critique ratings where the AI grades itself
2. Mid-Sized Enterprise Document Intelligence
Use Case: A law firm with 50,000 legal documents or a company with an internal knowledge base.
DocuChat's local-first design provides the security needed for proprietary information. Its modular architecture allows it to be adapted for specialized enterprise needs.
Scaling from Laptop to Enterprise:
The same system you run on your laptop can be scaled for enterprise use. The key is swapping out components and expanding the data sources.
Ingest Proprietary Data Securely: Since DocuChat is local-first, you can ingest confidential documents without them ever leaving your network.
Connect to Internal Knowledge Bases: Use the built-in URL ingestion feature to scrape and index internal websites, like a company wiki or documentation portal.
# Index an internal Confluence or SharePoint page
docuchat url http://internal-wiki.mycompany.com/important-docs
Scale Your Models: Start with a small, local model (e.g., via Ollama) for development and then switch to a powerful, managed API (like Gemini or a private Azure OpenAI endpoint) for production by changing the configuration.
Customize for Your Domain:
- Legal Entity Extraction: Replace the general-purpose NER with a model fine-tuned on legal text
- Citation Tracking: Extend the knowledge graph schema to link legal citations between documents
- Compliance Checks: Add a final validation node in the workflow to check responses against regulatory rules
3. Educational Institution Research Assistant
Use Case: University library with 100K research papers.
Customizations:
- Citation Graph: Build academic citation network in Neo4j
- Author Tracking: Link papers to authors, institutions
- Research Trends: Time-series analysis of topics
Graph Schema Extension:
// Neo4j schema for academic papers
CREATE (p:Paper {title: "...", year: 2024, doi: "..."})
CREATE (a:Author {name: "...", institution: "..."})
CREATE (c:Concept {name: "machine learning"})
// Relationships
CREATE (p)-[:WRITTEN_BY]->(a)
CREATE (p)-[:CITES]->(other_paper)
CREATE (p)-[:DISCUSSES]->(c)
4. Healthcare Provider Clinical Documentation
Use Case: Hospital with 500K patient records (HIPAA-compliant).
Why Local-First Matters: All data stays on-premises, no cloud API calls.
Customizations:
- Medical NER: Use BioBERT or ClinicalBERT for entity extraction
- SNOMED CT Integration: Map entities to medical ontologies
- Audit Trail: Log all queries for compliance
Self-Critique for Medical Accuracy:
📄 View Code: response_generator.py - Medical Critique
The system includes special validation for medical topics, paying attention to accuracy of medical claims, completeness of important medical information, and any unsupported medical advice. Ratings below 3/5 trigger automatic revision before the response is returned.
Industry Trends & Differentiation
RAG Evolution Timeline
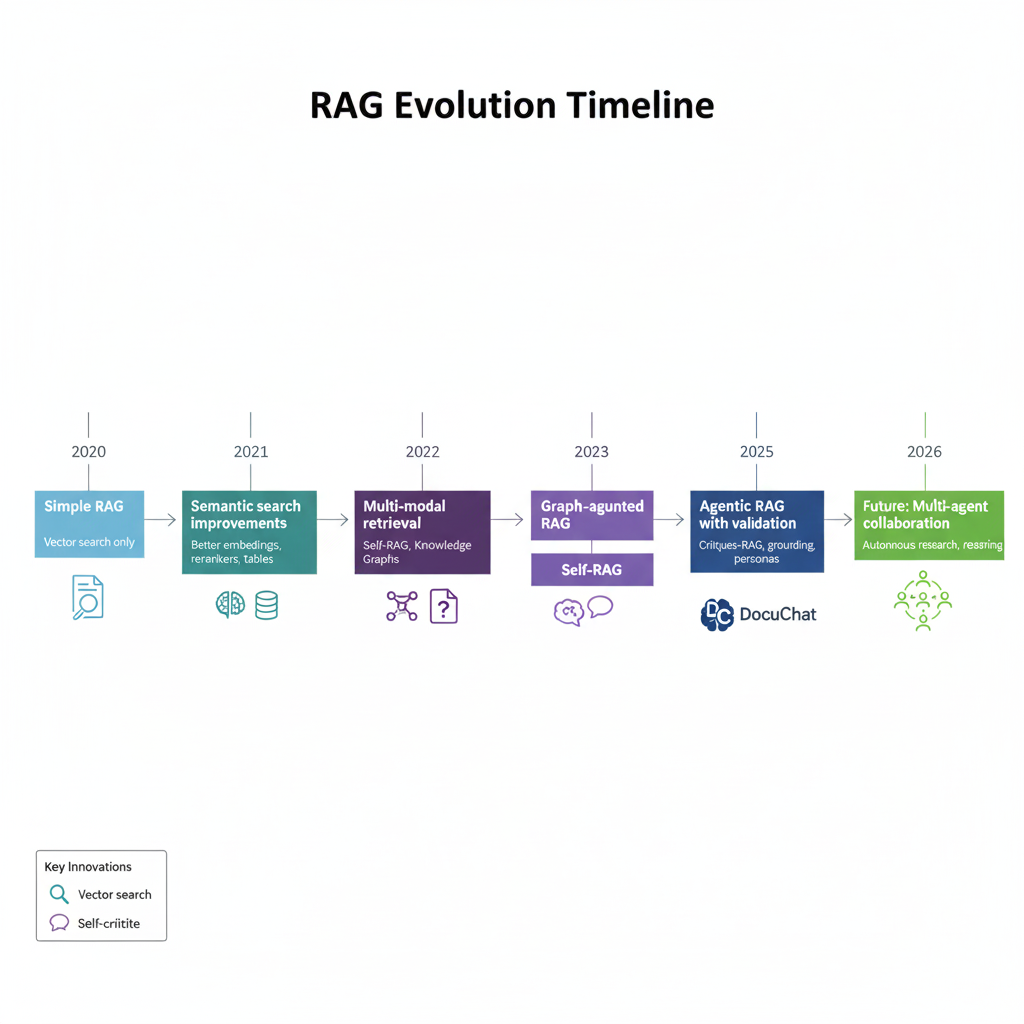
Suggested content: A horizontal timeline showing the evolution from 2020 (Simple RAG - Vector search only) → 2021 (Semantic search improvements) → 2022 (Multi-modal retrieval) → 2023 (Graph-augmented RAG, Self-RAG) → 2025 (Agentic RAG with validation, DocuChat) → 2026 (Future: Multi-agent collaboration)
Competitive Landscape
|
Feature |
DocuChat |
LangChain |
LlamaIndex |
Haystack |
|---|---|---|---|---|
|
Knowledge Graph |
✅ Built-in Neo4j |
❌ External |
⚠️ Plugin |
⚠️ Plugin |
|
Parallel Retrieval |
✅ asyncio |
❌ Sequential |
⚠️ Custom |
⚠️ Custom |
|
Self-Critique |
✅ Built-in |
❌ Manual |
❌ Manual |
❌ Manual |
|
Semantic Grounding |
✅ Sentence-level |
❌ None |
❌ None |
❌ None |
|
Local-First |
✅ Complete |
⚠️ Partial |
⚠️ Partial |
⚠️ Partial |
|
Entity-Aware Chunking |
✅ spaCy NER |
❌ Generic |
❌ Generic |
⚠️ Plugin |
|
Adaptive Confidence |
✅ Query-type based |
❌ None |
❌ None |
❌ None |
|
Persona System |
✅ Built-in |
❌ Manual |
❌ Manual |
❌ Manual |
Market Positioning
- vs. LangChain: More opinionated, production-ready architecture (not a framework)
- vs. LlamaIndex: Focus on validation and transparency, not just retrieval
- vs. Haystack: Built-in graph integration, simpler deployment
- vs. GraphRAG: Fully implemented system, not research framework
Getting Started
Installation
# Prerequisites: Python 3.10+, Docker (for Neo4j), 8GB RAM
# Note for beginners: While there are a few components, the setup is highly automated.
# The system is designed to run efficiently on modern laptops without special hardware.
# 1. Clone repository
git clone https://github.com/[GITHUB_USERNAME]/docuchat-agent.git
cd docuchat-agent
# 2. Setup environment
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
pip install -e .
# 3. Start Neo4j (Docker)
docker run -d \
--name neo4j-docuchat \
-p 7474:7474 -p 7687:7687 \
-e NEO4J_AUTH=neo4j/password \
neo4j:5.12-community
# 4. Initialize system
docuchat status --check-services
Quick Start Example
# 1. Ingest sample documents
docuchat ingest ./examples/sample_docs
# Expected output:
# Processing: research_paper.pdf ✓
# Processing: technical_spec.docx ✓
# Processing: meeting_notes.md ✓
#
# Results:
# - 47 chunks created
# - 152 entities extracted
# - 3 documents indexed
# Time: 8.2s
# 2. Interactive chat with verbose mode
docuchat chat --verbose
# Example conversation:
You: What machine learning models were mentioned?
🔍 VERBOSE: [RAGWorkflow] Executing query analysis...
🔍 VERBOSE: [QueryAnalyzer] Detected entities: ["machine learning", "models"]
🔍 VERBOSE: [QueryAnalyzer] Query type: factual
🔍 VERBOSE: [RAGWorkflow] Starting parallel retrieval...
🔍 VERBOSE: [RAGWorkflow] Vector search: 8 results (150ms)
🔍 VERBOSE: [RAGWorkflow] Graph search: 6 results (120ms)
🔍 VERBOSE: [ContextBuilder] Building context from 14 results...
🔍 VERBOSE: [ContextBuilder] After deduplication: 10 results
🔍 VERBOSE: [ContextBuilder] Hybrid boost applied: 3 cross-modal matches
🔍 VERBOSE: [ResponseGenerator] Generating response...
🔍 VERBOSE: [ResponseGenerator] Self-critique rating: 4/5 (passed)
🔍 VERBOSE: [ResponseGenerator] Grounding Analysis:
🔍 VERBOSE: [ResponseGenerator] - Method: Semantic similarity (embeddings) 🧠
🔍 VERBOSE: [ResponseGenerator] - Total sentences analyzed: 6
🔍 VERBOSE: [ResponseGenerator] - Semantically grounded sentences: 5 (83.3%)
🔍 VERBOSE: [ResponseGenerator] - Dynamic threshold: 0.40 (factual query)
🔍 VERBOSE: [ResponseGenerator] - Confidence level: HIGH ✅
The documents mention three machine learning models:
1. **Random Forest Classifier** (research_paper.pdf, p.12)
- Used for binary classification with 87% accuracy
- 100 estimators, max_depth=10
2. **LSTM Neural Network** (technical_spec.docx, section 3.2)
- Sequence prediction model
- 128 hidden units, dropout=0.2
3. **BERT-base-uncased** (research_paper.pdf, p.15)
- Fine-tuned for sentiment analysis
- 12 layers, 768 hidden dimensions
---
Confidence: 0.833
---
Project Structure for Contributors
docuchat-agent/
├── docuchat/ # Main application package
│ ├── agents/ # LangGraph workflow nodes
│ │ ├── rag_workflow.py # 🔥 Start here: Main orchestration
│ │ └── nodes/
│ │ ├── query_analyzer.py # Intent & entity extraction
│ │ ├── reasoning_planner.py # Q*-inspired planning
│ │ ├── vector_retriever.py # ChromaDB integration
│ │ ├── graph_retriever.py # Neo4j integration
│ │ ├── context_builder.py # 🔥 Multi-modal fusion
│ │ └── response_generator.py # 🔥 Self-critique & grounding
│ │
│ ├── core/ # Business logic
│ │ ├── document_processor.py # Entity-aware chunking
│ │ ├── vector_store.py # ChromaDB wrapper
│ │ ├── knowledge_graph.py # Neo4j wrapper
│ │ └── shared_embedding_service.py # BAAI/bge-m3 embeddings
│ │
│ ├── integrations/ # External service clients
│ │ ├── ollama_client.py # Local LLM integration
│ │ └── gemini_client.py # Gemini API integration
│ │
│ └── cli/ # Command-line interface
│ ├── chat.py # Interactive chat command
│ └── ingest.py # Document ingestion command
│
├── docs/ # Documentation
│ ├── architecture.md # Detailed system design
│ ├── explanation_guide.md # Reasoning modes guide
│ └── development.md # Development setup
│
├── tests/ # Integration tests
│ └── test_rag_workflow.py
│
└── examples/ # Sample code and documents
└── custom_persona.py # How to add custom personas
Key Files to Study (🔥):
agents/rag_workflow.py- LangGraph workflow architectureagents/nodes/context_builder.py- Multi-modal result fusionagents/nodes/response_generator.py- Self-critique & grounding
Conclusion: Why This Architecture Matters
For Learning
This codebase demonstrates production RAG patterns that go beyond tutorials:
- Parallel retrieval with asyncio
- Semantic validation using embeddings
- Self-supervised quality control with LLM critique
- Adaptive confidence scoring based on query characteristics
- Persona-driven response customization
For Production
The architecture handles real-world concerns:
- Hallucination detection (semantic grounding)
- Confidence transparency (dynamic thresholds)
- Performance optimization (parallel retrieval, conditional routing)
- Privacy compliance (local-first processing)
- Domain adaptation (persona system)
For Research
Novel contributions to RAG:
- Cross-modal validation for hybrid retrieval
- Context-aware confidence (sparse vs. rich context)
- Entity-aware chunking preserving relationship boundaries
- Self-critique loop before response finalization
- Persona-influenced information prioritization
Open Source & Community
Repository: https://github.com/rdondeti/docuchat-agent_cli
License: MIT (Free with attribution - see LICENSE)
Contributing:
- Study the architecture in
docs/architecture.md - Review open issues tagged
good-first-issue - Join discussions in GitHub Discussions
- Submit PRs following the contribution guide
Roadmap:
- [ ]Web UI (Streamlit-based)
- [ ]Multi-lingual support (expand beyond English)
- [ ]Fine-tuned reranker for context building
- [ ]Export to ONNX for embedding inference
- [ ]Kubernetes deployment manifests
- [ ]Additional domain-specific personas (HR, Sales, Customer Support)
Acknowledgments
Built with: LangChain, LangGraph, ChromaDB, Neo4j, spaCy, Sentence-Transformers, Ollama, Rich
Inspired by: Self-RAG (Asai et al., 2023), GraphRAG (Microsoft Research), Q* algorithm concepts
If this architecture helps your project, give us a ⭐ on GitHub!
Questions? Open an issue or discussion. We're building in public and learning together.
Appendix: Code Snippets Library
A. Custom Persona Implementation
📄 View Full Example: examples/custom_persona.py
This example demonstrates how to create a custom "security_analyst" persona with specialized prompts and confidence thresholds. The persona is configured to prioritize vulnerabilities and security incidents, structure responses around threat analysis, and require stricter validation with multiple source documents.
Usage:
# Use the custom persona in chat
docuchat chat --persona security_analyst
B. Custom Embedding Model
📄 View Full Example: examples/custom_embeddings.py
This example shows how to extend the base EmbeddingService class to use domain-specific embedding models, such as medical or legal embeddings, instead of the default BAAI/bge-m3 model.
C. Custom Graph Schema
📄 View Full Example: examples/custom_medical_schema.cypher
This Cypher script demonstrates how to extend the knowledge graph schema for medical documents, creating custom entity types (MedicalCondition, Medication) and relationships (DIAGNOSED_WITH, TREATED_WITH) that capture domain-specific connections.
[story continues]
tags