
Data fuels AI. Yet the very thing that makes machine learning powerful is also one of its greatest bottlenecks. Legal restrictions prevent sensitive records from moving freely, security concerns limit data sharing, and the logistics of collecting and labeling at scale often become
prohibitive. But, as models expand, so do their appetites: a modern vision system can require millions of annotated images, while large language models consume terabytes of text.
The traditional playbook, i.e., scraping the web, storing what you can, and annotating by hand, no longer scales. This is where synthetic data enters the picture. At first, it may sound like a compromise, something “fake” that falls short of the real thing. But that framing misses the point. Synthetic data is less about substitution and more about extension. It protects sensitive information, fills in the gaps where reality is sparse, and, in many cases, offers improvements over the datasets it supplements.
In this article, I'll cover what synthetic data really is, dive into the techniques for creating it, highlight its advantages in privacy and scalability, and back it up with real-world examples and a simple implementation.
Why Synthetic Data Matters Now
Three forces are converging to make synthetic data a necessity rather than an option:
1. Privacy Regulations: The more sensitive the data, the harder it becomes to use. Hospitals cannot upload patient scans to a public cloud just to fuel model training. Banks cannot share transaction logs across teams and jurisdictions without running into compliance risks. By 2025, privacy laws will cover nearly 80% of the global population, and the cost of GDPR violations alone has already exceeded €5.9 billion.
Traditional anonymization techniques are not a perfect escape hatch—they often reduce data utility by 30–50% and still leave a measurable re-identification risk. Synthetic data offers a sharper solution: replicate the statistical signal of the dataset without reproducing any individual's identity.
2. Data Scarcity: AI systems rarely fail on the “ordinary” cases. They fail on the rare ones: a child darting into the road, a financial anomaly buried deep in transaction flows, a manufacturing defect that shows up once in a million cycles. These are precisely the cases most absent from real-world datasets. Synthetic generation gives us a way to deliberately create those edge cases at scale, rather than hoping they appear naturally.
3. Model Scale: GPT-4 trained on an estimated trillion tokens. That kind of scale makes it nearly impossible to continue relying solely on curated, real-world datasets without hitting privacy and availability limits. Analysts had already expected synthetic data to account for 60% of AI training data by 2024, climbing to 80% by 2028.
Early adopters already report faster proof-of-concept cycles and measurable boosts in model accuracy. NVIDIA has taken this further: with Nemotron-4, they are building large language models explicitly designed to generate synthetic datasets for training other LLMs (NVIDIA Blog)
In parallel, their work on simulation-based pipelines shows how synthetic environments can strengthen robotics, autonomous driving, and computer vision models without ever touching sensitive real-world data.
The Engineering Behind Synthetic Data
At its core, the engineering of synthetic data is about statistical fidelity: generating data that preserves the distributions and correlations of the real world without leaking individual records. The techniques vary by domain:
- Vision - Simulation engines such as CARLA produce photorealistic driving scenes with controllable lighting, weather, and traffic conditions.
- Tabular data - Generative models like GANs, VAEs, or diffusion networks learn feature distributions and produce new samples with a similar structure.
- Text - Domain-tuned language models generate synthetic logs, dialogues, or documents, filtered for identifiers and sensitive content.
- Time-series - Approaches such as TimeGAN capture temporal dependencies in financial or IoT streams, creating realistic synthetic traces.
The challenge lies in balancing two objectives: utility and privacy. Data must be useful enough to train performant models, but distinct enough to guarantee that no original record is inadvertently reconstructed. Differential privacy, membership inference testing, and distributional distance metrics all form part of the validation toolkit.
“Fake” vs. “Useful”: The Quality Question
The most common criticism is that synthetic data is “fake” and therefore unreliable. But the same argument was once leveled against physics simulations or synthetic benchmarks in computer architecture.
What ultimately matters is not whether a data point came from the real world, but whether it captures the properties needed for the task.
Take medical imaging: a synthetic MRI does not need to replicate a specific patient’s scan. What it must preserve are the distributions of tissue density, lesion variability, and signal noise that define the diagnostic space.
In fact, synthetic datasets often outperform real ones by balancing class ratios, amplifying rare cases, and filtering annotation errors.
Evidence from self-driving research illustrates this well. Models trained on a mixture of synthetic and real driving data tend to generalize better than those trained purely on reality. By explicitly introducing edge cases, foggy conditions, sudden obstacles, and rare traffic maneuvers, synthetic generation helps reduce the brittleness of models exposed only to “average” roads.
Synthetic data, then, is not a weaker shadow of reality. It is an engineering tool: a way to bend data availability toward the needs of AI rather than waiting for the world to provide enough examples on its own.
Scaling AI With Synthetic Data
Synthetic data isn’t just about privacy—it’s about scale.
Consider three practical advantages:
1. Data Augmentation at Scale: Instead of waiting months to collect edge cases, researchers can generate thousands of variations in hours.
2. Rapid Iteration: Need to test a new model architecture? Generate a synthetic dataset tuned for the scenario rather than waiting for data collection cycles.
3. Cross-Domain Transfer: Companies often face “data silos”—one team has sensitive financial records, another has medical images. Synthetic data allows controlled sharing without direct exposure.
In this sense, synthetic data is a form of infrastructure, much like cloud computing was for storage and computing.
Techniques for Generating Synthetic Data
Let's get technical. The workhorses here are generative adversarial networks (GANs), variational autoencoders (VAEs), and, more recently, diffusion models. I'll focus on GANs and VAEs as they are foundational and work with tabular and image data, but the principles
extend.
In a GAN, two neural networks duke it out: a generator creates fake samples, and a discriminator tries to spot them as phony. Over-training, the generator improves until the discriminator can't tell real from synthetic. Mathematically, this is an optimization problem minimizing the Jensen-Shannon divergence between real and synthetic distributions.
The loss function for a basic GAN looks like this:
GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
Where G maps noise z to synthetic data, and estimates the probability that a sample is real. Suppose we have a dataset with two features that form three distinct clusters. We want to generate synthetic data that looks similar to the original data, preserving the cluster structure
and the spread of the data points.
A Variational Autoencoder (VAE) is a generative model that consists of an encoder and a decoder. The encoder maps the input data to a latent space (a probability distribution), and the decoder samples from this latent space to generate new data. The key idea is to learn the parameters of the latent distribution (mean and variance) such that the generated data is similar to the original data.
The VAE loss function has two parts:
- Reconstruction loss: Measures how well the decoder reconstructs the input data from the latent representation.
- KL divergence: Regularizes the latent distribution to be close to a standard normal distribution.
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import random
# -----------------------
# Step 1: Real Data Generator
# -----------------------
def data_generator(n=1000):
centers = [(-8,-6), (-2, 7), (6, 5)]
data = []
for _ in range(n):
point = np.random.randn(2) * 0.5
cx, cy = random.choice(centers)
point[0] += cx
point[1] += cy
data.append(point)
return np.array(data, dtype=np.float32)
real_data = data_generator(2000)
# -----------------------
# Step 2: Define a Simple VAE
# -----------------------
class VAE(nn.Module):
def __init__(self, latent_dim=2):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(2, 16), nn.ReLU(),
nn.Linear(16, 8), nn.ReLU()
)
self.fc_mu = nn.Linear(8, latent_dim)
self.fc_logvar = nn.Linear(8, latent_dim)
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 8), nn.ReLU(),
nn.Linear(8, 16), nn.ReLU(),
nn.Linear(16, 2)
)
def encode(self, x):
h = self.encoder(x)
return self.fc_mu(h), self.fc_logvar(h)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
return self.decoder(z)
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
# -----------------------
# Step 3: Train the VAE
# -----------------------
device = "cuda" if torch.cuda.is_available() else "cpu"
vae = VAE().to(device)
optimizer = optim.Adam(vae.parameters(), lr=1e-3)
def loss_function(recon_x, x, mu, logvar):
recon_loss = nn.MSELoss()(recon_x, x)
kld =-0.5 * torch.mean(1 + logvar - mu.pow(2)- logvar.exp())
return recon_loss + kld
x_train = torch.from_numpy(real_data).to(device)
for epoch in range(2000):
optimizer.zero_grad()
recon, mu, logvar = vae(x_train)
loss = loss_function(recon, x_train, mu, logvar)
loss.backward()
optimizer.step()
if epoch % 500 == 0:
print(f"Epoch {epoch}, Loss: {loss.item():.4f}")
# -----------------------
# Step 4: Generate Synthetic Data
# -----------------------
z = torch.randn(2000, 2).to(device)
synthetic_data = vae.decode(z).cpu().detach().numpy()
# -----------------------
# Step 5: Plot Real vs Synthetic
# -----------------------
plt.scatter(real_data[:, 0], real_data[:, 1], label='Real', alpha=0.5)
plt.scatter(synthetic_data[:, 0], synthetic_data[:, 1], label='Synthetic', alpha=0.5)
plt.legend()
plt.show()
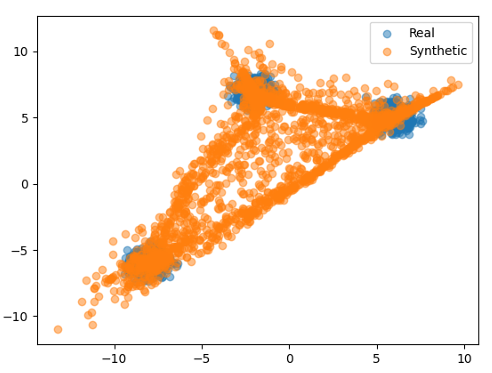
The plot shows that the VAE has learned to generate data that closely resembles the original data. The synthetic data also has three clusters, and the spread of the points is similar. However, note that the synthetic data might not perfectly match the real data because the
VAE is a probabilistic model and the generated data is subject to the randomness in the latent space.
Privacy: The Killer App
Regulations like the EU's AI Act demand high-risk systems prove data protection, and breaches cost billions. Remember Equifax? Synthetic data never touches personal info. Techniques like differentially private GANs (DP-GANs) add calibrated noise, guaranteeing that no individual's data leaks through.
Why does this work better than anonymization? K-anonymity can still allow re-identification via linkage attacks, whereas synthetic data breaks the link entirely.
Scalability: From Scarcity to Abundance
Data scarcity affects AI in domains like rare disease diagnosis or self-driving cars in snowy conditions. Collecting real data is slow and costly; labeling alone can run millions. Synthetic data scales effortlessly: Once your generator is trained, crank out terabytes.
Take Waymo's simulation engine: They generate synthetic driving scenarios, blending real sensor data with procedural generation, training models on billions of virtual miles. Results? Models generalize better to unseen events, reducing real-world testing needs.
Cost-wise, a McKinsey report estimates synthetic data could cut AI development expenses by 20-50% by accelerating prototyping. And with cloud tools like AWS SageMaker or Google Cloud's Vertex AI now offering synthetic data pipelines it's accessible to startups, not just
tech giants.
Where We Go From Here
Synthetic data should not be viewed as a replacement for real-world data but as a strategic complement. Things will likely be hybrid: small amounts of high-quality real data combined with vast and controllable synthetic datasets.
This approach unlocks two critical pathways:
- Private AI: Models can be trained without risking leakage of sensitive personal data.
- Scalable AI: Innovation is no longer bottlenecked by collection costs or rare-event scarcity.
In NLP, synthetic text from models like GPT variants (fine-tuned with privacy controls) has boosted low-resource language models.
But counterarguments exist: Synthetic data can amplify biases if the seed data is skewed; it's garbage in, garbage out. Overfitting to the generator's quirks is another risk, leading to models that perform well on synthetic but flop on real. Mitigation? Hybrid approaches: Mix synthetic with a small real subset, and rigorously validate with holdout tests.
Hallucinations in generators, especially for complex data like videos, remain a challenge. Diffusion models like Stable Diffusion help, but they're compute-intensive.
Conclusion
Calling synthetic data “fake” misses the point. What matters is not its origin but its utility. The next generation of AI systems will be built not just on what we have collected but on what we can generate responsibly.
[story continues]
tags