
Table of Links
Supplementary Material
-
Image matting
-
Video matting
5.2. Training on video data
Temporal consistency metrics. Following previous works [45, 48, 57], we extended our evaluation metrics to include dtSSD and MESSDdt to assess the temporal consistency of instance matting across frames.
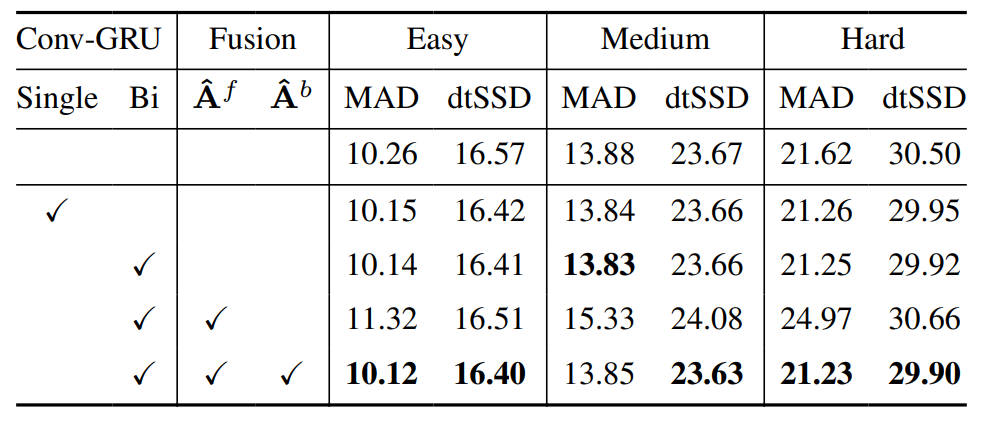
Ablation studies. Our tests, detailed in Table 6, show that each temporal module significantly impacts performance. Omitting these modules increased errors in all subsets. Single-direction Conv-GRU use improved outcomes, with further gains from adding backward pass fusion. Forward fusion alone was less effective, possibly due to error propagation. The optimal setup involved combining backward propagation to reduce errors, yielding the best results.
Performance evaluation. Our model was benchmarked

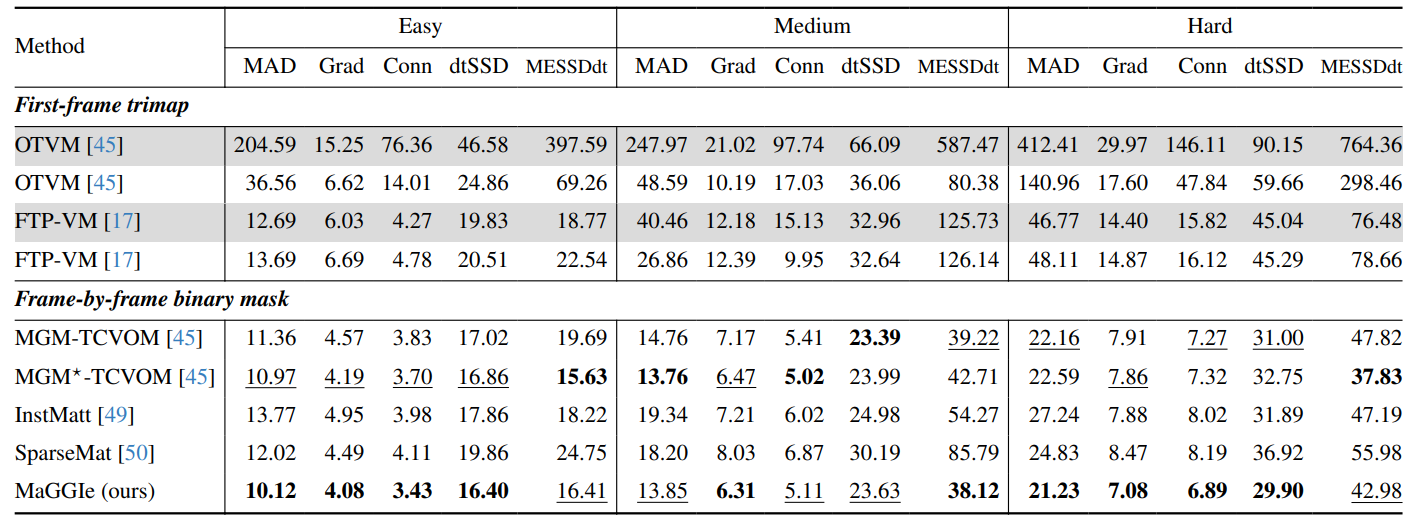
against leading methods in trimap video matting, mask-guided matting, and instance matting. For trimap video matting, we chose OTVM [45] and FTP-VM [17], finetuning them on our V-HIM2K5 dataset. In masked guided video matting, we compared our model with InstMatt [49], SparseMat [50], and MGM [56] which is combined with the TCVOM [57] module for temporal consistency. InstMatt, after being fine-tuned on I-HIM50K and subsequently on V-HIM2K5, processed each frame in the test set independently, without temporal awareness. SparseMat, featuring a temporal sparsity fusion module, was fine-tuned under the same conditions as our model. MGM and its variant, integrated with the TCVOM module, emerged as strong competitors in our experiments, demonstrating their robustness in maintaining temporal consistency across frames.
The comprehensive results of our model across three test sets, using masks from XMem, are detailed in Table 7. All trimap propagation methods are underperform the maskguided solutions. When benchmarked against other masked guided matting methods, our approach consistently reduces error across most metrics. Notably, it excels in temporal consistency, evidenced by its top performance in dtSSD for both easy and hard test sets, and in MESSDdt for the medium set. Additionally, our model shows superior performance in capturing fine details, as indicated by its leading scores in the Grad metric across all test sets. These results underscore our model’s effectiveness in video instance matting, particularly in challenging scenarios requiring high temporal consistency and detail preservation.
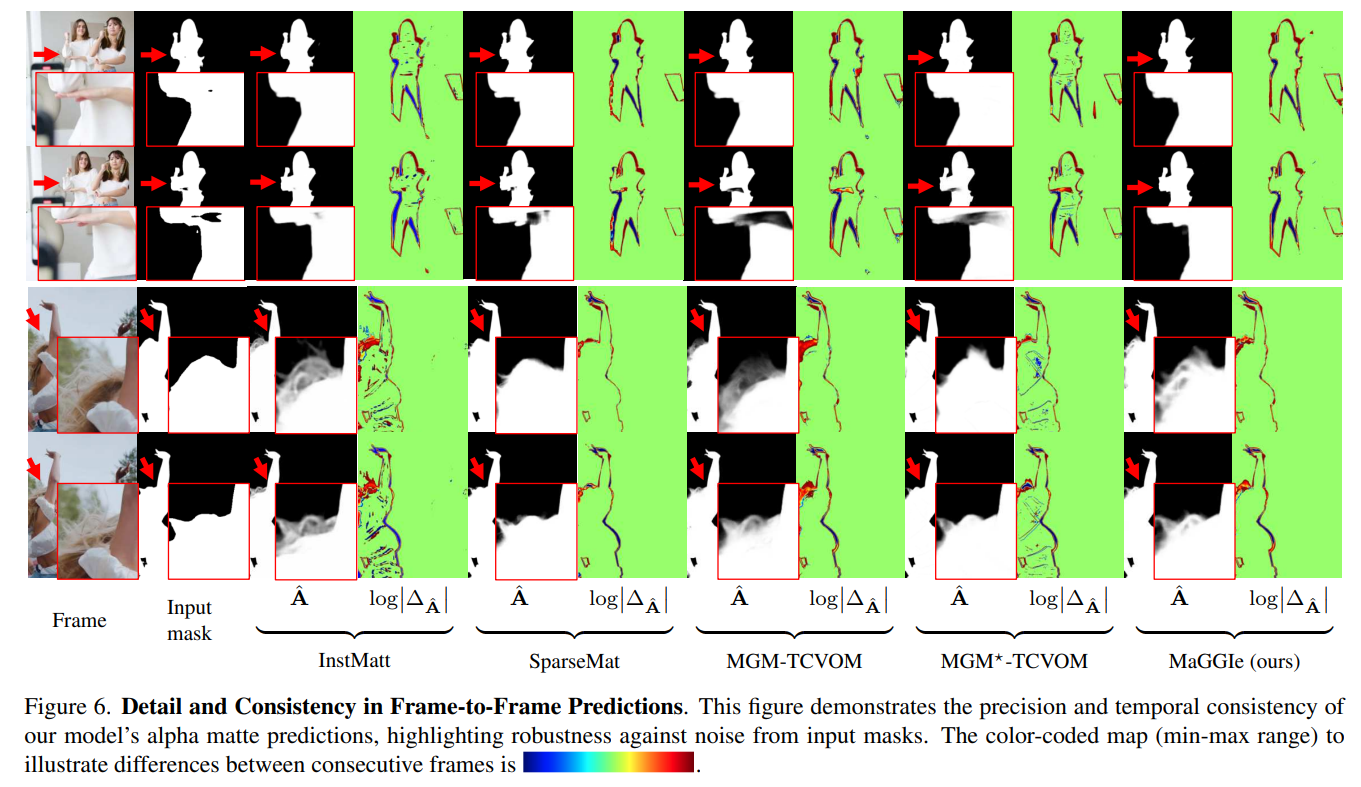
Temporal consistency and detail preservation. Our model’s effectiveness in video instance matting is evident in Fig. 6 with natural videos. Key highlights include:
• Handling of Random Noises: Our method effectively handles random noise in mask inputs, outperforming others that struggle with inconsistent input mask quality.
• Foreground/Background Region Consistency: We maintain consistent, accurate foreground predictions across frames, surpassing InstMatt and MGM⋆ -TCVOM.
• Detail Preservation: Our model retains intricate details, matching InstMatt’s quality and outperforming MGM variants in video inputs.
These aspects underscore MaGGIe’s robustness and effectiveness in video instance matting, particularly in maintaining temporal consistency and preserving fine details across frames.
Authors:
(1) Chuong Huynh, University of Maryland, College Park (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh, Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava, University of Maryland, College Park (abhinav@cs.umd.edu);
(4) Joon-Young Lee, Adobe Research (jolee@adobe.com).
This paper is
[story continues]
tags