This is a Plain English Papers summary of a research paper called Recurrent-Depth VLA: Implicit Test-Time Compute Scaling of Vision-Language-Action Models via Latent Iterative Reasoning. If you like these kinds of analyses, join AIModels.fyi or follow us on Twitter.
Overview
- Vision-language-action models control robots by understanding images and text instructions, then outputting motor commands.
- Most current systems make their decisions in a single forward pass, like answering a question immediately without thinking it through.
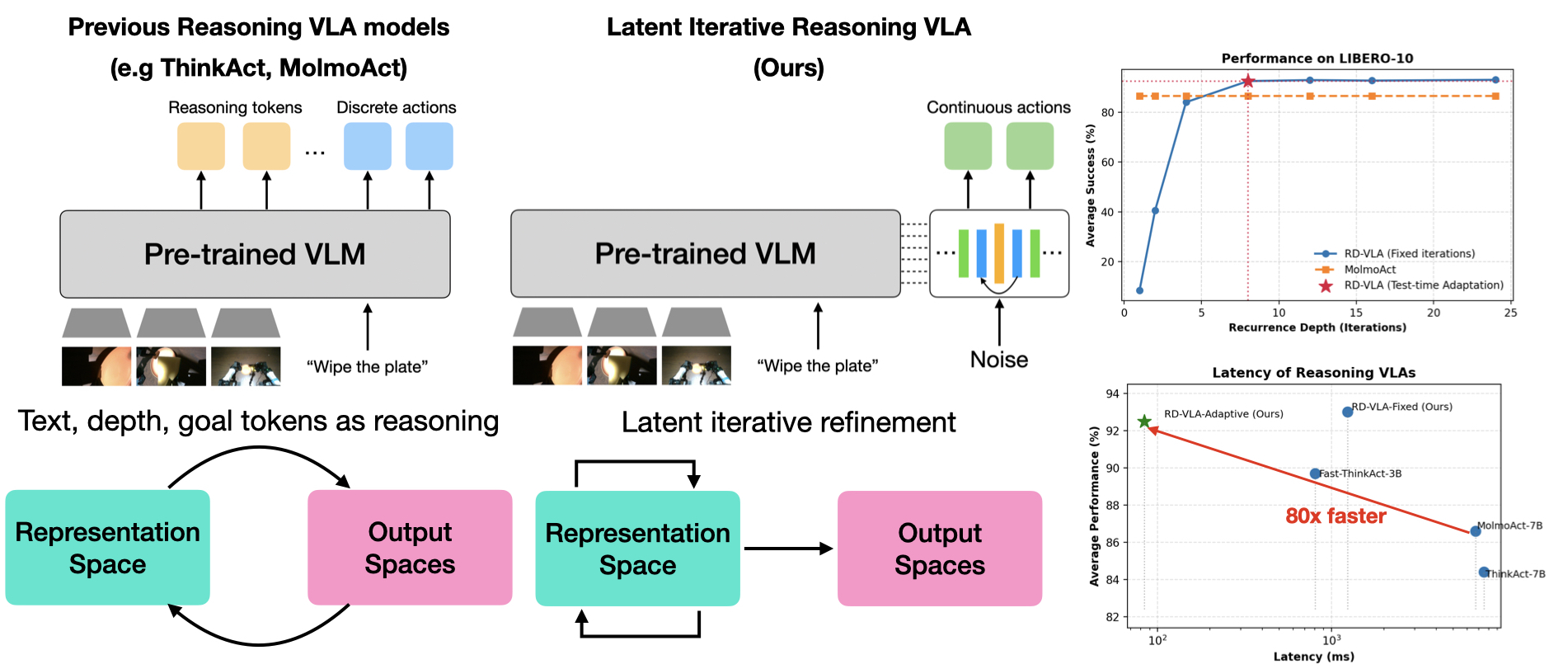
- This paper introduces a method where the model can iterate internally multiple times before deciding what action to take.
- The iterations happen in a hidden "latent" space rather than generating visible text reasoning.
- The approach allows the model to use more computation at test time without changing its core architecture.
- Early experiments show this iterative approach improves performance on robotic tasks.
Plain English Explanation
Think of current robot control systems as people who make snap decisions. They see a scene, instantly understand what's needed, and act. That works for simple tasks, but fails when the situation requires careful thought.
The Recurrent-Depth VLA model works differently. Instead of deciding immediately, it lets the model think through the problem multiple times internally before committing to an action. The key twist is that this thinking happens invisibly—the model iterates within its own hidden representations rather than generating visible reasoning steps like writing out thoughts in words.
This matters because robots need to handle complex tasks where a single pass through the model isn't enough. A robot picking up an object in clutter might need to reason through occlusions and spatial relationships. By allowing internal iteration, the model gains the benefit of deeper reasoning without the computational overhead of generating and processing language.
The system essentially trades latency for accuracy during testing. You get better decisions by letting the model think longer, using what's called test-time compute scaling. The training process stays largely the same, but at test time, you can add more thinking steps as needed.
Key Findings
The research demonstrates that allowing vision-language-action models to iterate internally produces measurable improvements on robotic manipulation tasks. The experiments show that more iteration steps generally lead to better performance, though with diminishing returns. The method successfully scales computation at test time without requiring retraining, meaning practitioners can adjust the amount of thinking based on task difficulty and available time.
The findings suggest that implicit reasoning in latent spaces is an effective approach for robot control. Unlike systems that generate explicit step-by-step reasoning, the hidden iterative approach maintains efficiency while gaining reasoning capability.
Technical Explanation
The architecture builds on existing vision-language-action models but adds a recurrent component that operates in the hidden representation space. Rather than processing input once and outputting an action, the system feeds its internal state back through itself multiple times. Each iteration refines the representation before the final action prediction.
The model uses depth in latent reasoning by having multiple layers process information iteratively. The same processing layers execute repeatedly on increasingly refined internal states. This differs from simply stacking more layers, which would require more parameters and training time. Instead, the same computational components recur.
During training, the model learns to produce actions through standard supervised learning. At test time, you can vary the number of reasoning iterations. Run it once for fast decisions, or run it ten times for tasks requiring deep analysis. The model naturally learns what patterns benefit from iteration and which don't.
The experiments measure performance on robotic tasks requiring manipulation and spatial reasoning. The results confirm that additional iterations improve success rates on complex tasks while having minimal impact on already-simple problems. This selective benefit aligns with intuition—your brain spends more time thinking about hard problems.
Critical Analysis
The HTML provided contains only a table of contents and lacks the actual paper content, experimental results, and methodology details needed for thorough evaluation. Without seeing the full technical approach, specific performance numbers, and comparison baselines, a complete assessment of the work's validity and significance remains limited.
Some questions worth considering: Does the performance improvement justify the added latency? In real robotic applications, waiting longer for decisions may introduce risks if the environment changes during reasoning. The paper would need to show that gains outweigh delays for practical deployment. Additionally, the comparison to other test-time scaling approaches matters—existing methods like ensemble approaches or beam search might achieve similar improvements with different tradeoffs.
The choice to hide reasoning in latent space rather than making it explicit has tradeoffs. Interpretability suffers—you can't see what the model is thinking through, which matters for safety-critical applications. A human can't understand why the robot chose an action, only that more iterations led to it. For tasks involving humans or safety concerns, explicit reasoning might be necessary despite lower efficiency.
Training stability could present challenges. Recurrent systems sometimes develop training instabilities, and the paper would need to address how they ensure stable learning. The generalization question also remains open—does a model trained on one set of robotic tasks benefit from iteration on novel tasks, or does it overfit the reasoning style to training data?
Conclusion
The Recurrent-Depth VLA approach represents a meaningful direction for improving robotic decision-making. By allowing models to iterate internally on their representations, the system gains reasoning capability without fundamental architectural changes or retraining. The core insight—that test-time compute scaling in latent space can improve performance—has value across robot learning.
The method sits at an interesting intersection. Vision-language-action models provide the foundation, latent iterative reasoning adds the thinking mechanism, and the ability to vary iterations at test time provides practical flexibility. For roboticists building systems that must handle variable task complexity, this approach offers a tool to improve reliability when reasoning time is available.
The practical impact depends on factors not fully visible in the available information: how much improvement occurs, how much time each iteration requires, and whether gains persist across diverse task distributions. For the field to adopt this approach, researchers would need to demonstrate clear performance gains that justify implementation complexity and demonstrate reliability across different robotic platforms and task types.
Original post: Read on AIModels.fyi