
What tools do you need to build an AI agent?
It goes well beyond just the LLM. While the AI takes center stage, the tooling to create robust agents is more about infrastructure than intelligence. You need databases that can keep up with agent workloads, orchestration to handle multi-step processes, ways to verify that agents aren’t making mistakes, and systems to monitor everything in production.
This stack can contain dozens of tools, each with its own trade-offs and integration requirements. Here, we want to go through each within the framework of how they’ll work within your agent.
The AI Agent framework
We could just list out all the tools you might need to build an AI agent, but that won’t be as helpful if you want to develop agents (or agent platforms) that work to a specific use case or production standard. Instead, we need to understand how these tools fit together into a coherent architecture.
AI agents operate in a
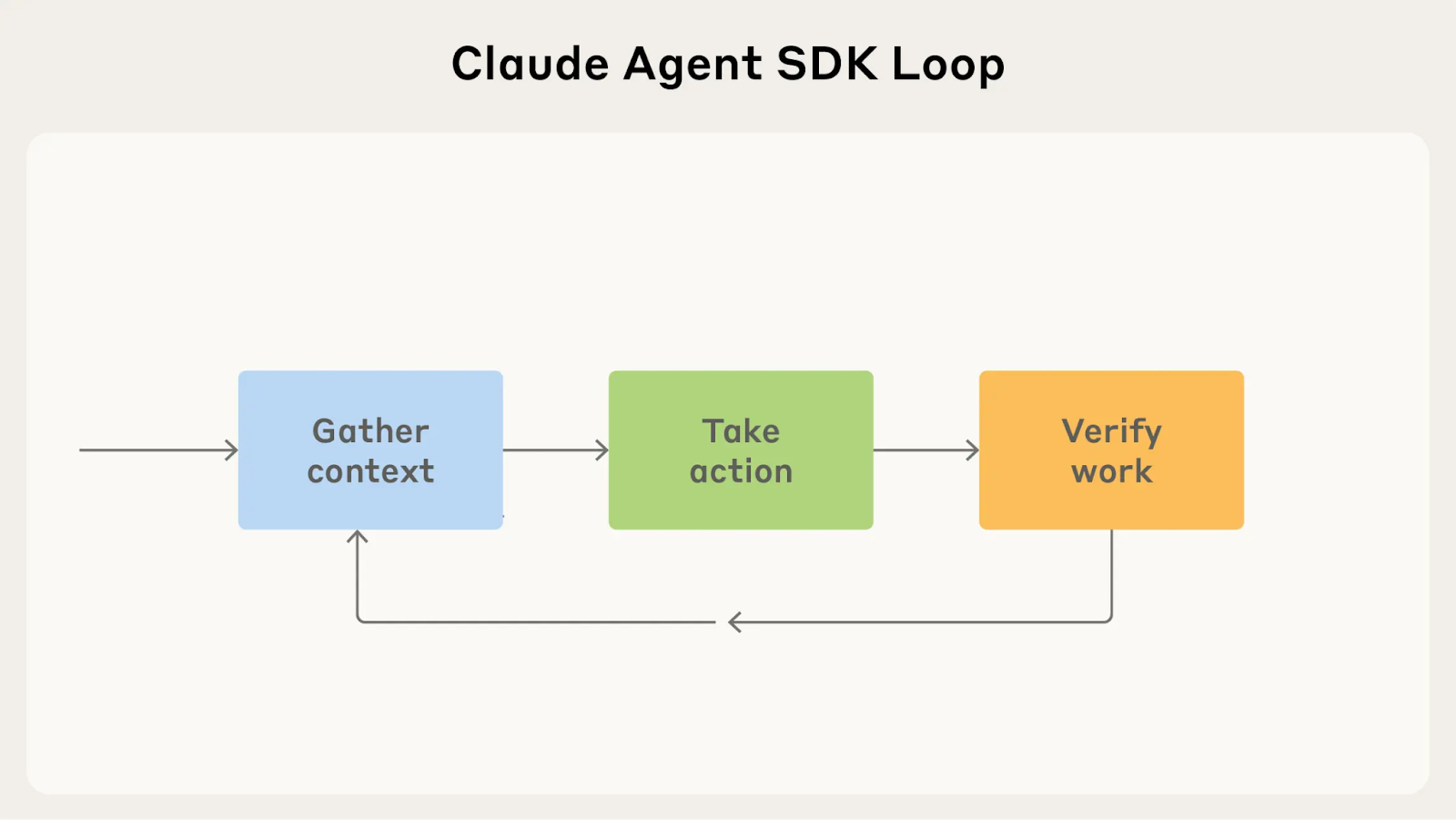
This pattern repeats until the agent completes its task or determines it needs human intervention.
Context layer
The context phase is where your agent gathers information. It needs to retrieve relevant data, load it efficiently into the model's context window, and decide what's important enough to keep. This shouldn’t be just passive data loading, but an active search process where the agent determines what information matters for the task at hand.
Action layer
The action phase is where your agent executes. It takes the context it's gathered and does something with it: calling APIs, writing code, transforming data, or triggering workflows. The key is giving your agent the right capabilities to solve problems flexibly rather than just following rigid scripts.
Verification layer
The verification phase closes the loop. Your agent checks its own work, catches errors, and decides whether to iterate or move forward. Agents that can self-correct are fundamentally more reliable because they catch mistakes before they compound.
This is all wrapped within an infrastructure that handles orchestration, monitoring, and scaling, ensuring your agent runs reliably in production.
Now, let's break down what you need at each layer.
Context layer tooling
The tools for the context layer are all about storing and retrieving information. The right tools depend on what kind of data you're working with and how your agent accesses it.
Databases for transactional data
Agents need OLTP databases that can provision instantly when spinning up new projects or user sessions, handle unpredictable bursty workloads that idle most of the time then spike suddenly, provide isolated environments for testing queries or schema changes, and support multi-agent architectures where each agent or domain gets its own database.
Full-stack agent platforms like
Vector databases
If your agent requires specialized vector workloads at massive scale with optimized indexing, you can lean on dedicated databases like:
Pinecone : Managed vector database with high performance at scaleWeaviate : Open-source vector search engine with GraphQL API and hybrid searchQdrant : Rust-based vector database with advanced filtering capabilitiesChroma : Lightweight embedding database optimized for development and prototyping
These make sense when you're working with billions of vectors or need advanced filtering. For most agents, keeping everything in a single database system wil reduce complexity and latency. A popular option is to skip the use of a specialized vector database altogether and instead opt for handling vector search alongside transactional data through the
Blob storage
If your agent needs access to large files, documents, logs, and media - i.e. reading PDFs for context, processing images, analyzing logs, or storing generated reports and visualization - you might need to integrate with object storage.
AWS S3 : Industry-standard with broad integration supportGoogle Cloud Storage : Multi-region with strong consistencyAzure Blob Storage : Enterprise storage with lifecycle managementCloudflare R2 : S3-compatible with zero egress fees
Your agent accesses these through APIs, retrieving files on demand and storing outputs. The challenge is managing permissions and costs, especially egress charges.
MCP servers
You’ll also need a standardize ways to connect your agent to external data without writing custom integrations for every service. The
- Filesystem MCP: Read and search local files
- Google Drive MCP: Search and retrieve cloud documents
GitHub MCP : Access issues, PRs, and codeNeon MCP : Query Neon databases through a standardized interface
The advantage is standardization. Once your agent knows MCP, it works with any MCP server without needing to learn service-specific APIs. Authentication and calls happen automatically.
For services without MCP servers, you fall back to direct REST APIs, webhooks, or custom connectors. More work, but complete control.
Action layer tooling
The action layer is where your agent executes tasks. Once it has context, it needs to reason about what to do and actually do it. This requires models for intelligence, frameworks for orchestration, and infrastructure for safe execution.
LLM providers
You need a language model as the reasoning engine for your agent. The model interprets context, decides what actions to take, generates responses, and calls tools. Your choice of model determines your agent's capabilities, cost, and latency.
Top-tier models for production agents:
Claude (Anthropic): Strong reasoning, long context windows, excellent at following complex instructionsGPT-5 (OpenAI): Powerful general-purpose model with broad capabilitiesGemini (Google): Multimodal model with strong performance on complex reasoning and long context
The advantage is capability. These models handle complex reasoning, understand nuanced instructions, and generate high-quality outputs. They support function calling for tool use and maintain coherence across long conversations.
The cost comes from API pricing and latency. Every agent decision requires a model call. High-volume agents can rack up significant token costs. Latency matters for real-time interactions, and these models typically have response times of 1-5 seconds.
For specific use cases, consider:
- Open-source models (
Llama ,Mixtral ,Qwen ): Self-hosted for data privacy or cost control at scale, but require GPU infrastructure - Specialized models (
Codex for coding, embedding models for retrieval): Optimized for specific tasks - Smaller models (GPT-3.5, Claude Haiku): Faster and cheaper for simpler tasks
Most production agents use a mix. Primary reasoning with top-tier models, routine tasks with faster models, and embeddings from specialized models.
Agent frameworks
You need orchestration to manage multi-step workflows, tool calling, and memory. Agent frameworks handle the loop of observing context, deciding on actions, executing tools, and updating state.
Popular frameworks for production:
Claude Agent SDK : Built on Claude Code, provides computer access, file operations, and tool execution with feedback loopsLangChain : Mature ecosystem with chains, agents, and memory abstractionsLangGraph : Built on LangChain, adds stateful workflows with cycles and control flow for complex agent logicAutoGen (Microsoft): Multi-agent systems with conversation-based orchestration
The advantage is speed. These frameworks handle the boilerplate of prompt construction, tool calling, error handling, and state management. They provide pre-built patterns for common agent workflows.
The problem is abstraction overhead. Frameworks can obscure what's actually happening, making debugging harder. They also introduce dependencies and API changes. Some teams find heavy frameworks too rigid for custom agent logic.
For complex multi-agent systems, consider
Workflow orchestration
You need durable execution for multi-step processes. Agents often run tasks that span minutes or hours, call multiple external services, and must handle failures gracefully without losing progress.
Vercel Workflows or
Code execution and sandboxing
Agents that write and run code need safe execution environments. You can't let agent-generated code access your production systems or run indefinitely. Sandboxing isolates execution and limits damage from bugs or malicious code.
Primary approaches:
- Docker containers: Isolated environments with resource limits, network restrictions, and filesystem boundaries
E2B : Managed sandboxes built explicitly for AI code execution with language runtimes pre-configuredModal : Serverless Python execution with built-in sandboxing, GPU access, and container orchestrationFirejail : Lightweight Linux sandboxing for process isolation- Isolated VMs: Full virtualization for maximum isolation but higher overhead
Docker is the standard. You run agent code in ephemeral containers that have no access to the host system, enforce CPU and memory limits, and tear down after execution. Set timeouts to prevent infinite loops. Use read-only filesystems where possible.
Modal and E2B provide managed sandboxing that removes infrastructure overhead. Modal excels at compute-intensive tasks with its serverless GPU access, while E2B focuses specifically on AI agent code execution with pre-configured runtimes.
For serverless environments,
Verification layer tooling
The verification layer ensures your agent isn't making mistakes. Agents can hallucinate, generate broken code, or make poor decisions. You need tools to monitor behavior, test outputs, and catch errors before they reach users.
Observability and evaluation
You need to monitor what your agent is doing and evaluate whether it's doing it well. This means tracing each decision, logging tool calls, measuring output quality, and detecting when performance degrades.
Testing frameworks
You need automated testing to verify agent behavior before deployment. This includes testing that agents handle expected inputs correctly, fail gracefully on edge cases, and maintain consistent quality across prompt or model changes.
Standard testing frameworks work for agents with some adaptation:
Pytest (Python): Write test cases that call your agent with sample inputs and assert on outputsJest (JavaScript): Test agent responses with expect assertions on content and format- Agent-specific assertions: Check not just the final output, but intermediate steps, like which tools were called
The approach is similar to traditional software testing. Create a test suite with representative queries, run your agent against them, and assert that outputs meet quality criteria. The difference is that agent outputs aren't deterministic, so tests often check for semantic correctness rather than exact matches.
Custom eval harnesses provide more sophistication. These run large test sets, use LLM-as-judge to score outputs on fuzzy criteria like helpfulness or tone, and track performance over time. Human review loops add a layer where people evaluate agent outputs, especially for subjective quality or edge cases that automated tests miss.
Linting and code quality
Agents that generate code need validation to catch syntax errors, security issues, and style problems. Running linters on agent-generated code provides immediate feedback that the agent can use to fix mistakes. Language-specific linters catch different issues:
-
ESLint (JavaScript): Detects syntax errors, undefined variables, and code style violations -
Ruff (Python): Fast Python linter that catches common bugs and enforces conventions -
Pylint /Flake8 (Python): More comprehensive checking with configurable rules -
RuboCop (Ruby): Style and correctness checking for Ruby codeType checkers add another layer of validation.
TypeScript for JavaScript,mypy for Python, and similar tools catch type errors that linters miss. Code formatters likePrettier orBlack ensure consistent style. Together, these tools give agents concrete feedback about code quality, turning subjective "is this good code?" into objective "does this pass these checks?"
Deployment platforms
You need somewhere to run your agent code that scales with demand, handles failures gracefully, and doesn't require constant babysitting. The platform choice depends on your agent's runtime requirements and usage patterns.
Container orchestration platforms provide the most flexibility:
Kubernetes : Industry standard for container orchestration with autoscaling, service discovery, and self-healingDocker Swarm : Simpler alternative for smaller deployments with basic orchestrationAWS ECS/EKS : Managed container services integrated with the AWS ecosystemGoogle Kubernetes Engine (GKE): Managed Kubernetes with Google Cloud integration
Serverless platforms remove infrastructure management:
- AWS Lambda: Run code without managing servers, pay per execution
Vercel : Deploy functions with automatic scaling and edge distributionGoogle Cloud Functions : Event-driven serverless executionAzure Functions : Serverless compute integrated with Azure services
Cloud VMs remain an option for agents that need long-running processes or specific system configurations. Services like
API gateways
You need a front door for your agent that handles authentication, rate limiting, request routing, and monitoring. API gateways sit between users and your agent, managing all incoming traffic.
Common gateway solutions:
-
AWS API Gateway : Managed service with built-in auth, throttling, and CloudWatch integration -
Kong : Open-source gateway with plugins for auth, logging, and transformation -
Nginx : Lightweight reverse proxy with flexible configuration -
Traefik : Modern proxy with automatic service discovery and Let's Encrypt supportCloudflare Workers provides an edge-based approach, running gateway logic close to users for lower latency. This works well for global agents that need fast response times regardless of user location.
Secrets management
You need secure storage for API keys, database credentials, and other sensitive data. Hardcoding secrets in code or environment variables creates security risks. Secrets management systems provide encrypted storage, access control, and audit logging.
Standard solutions:
AWS Secrets Manager : Managed service with automatic rotation and IAM integrationHashiCorp Vault : Open-source secrets management with dynamic credentials and encryption as a serviceAzure Key Vault : Managed vault integrated with Azure services and Active Directory
For development, environment variables work but aren't suitable for production. Tools like
The key is never committing secrets to version control and rotating them regularly. Secrets management systems enforce these practices through technical controls rather than relying on developer discipline.
Building your agent stack
Building production agents is less about finding the perfect tool and more about understanding what your agent actually needs at each layer. Start with the basics: a database that provisions fast, an LLM that can reason through your use cases, and observability so you know what's happening. Add complexity only when you need it.
Not every agent needs workflow orchestration or dedicated vector databases. A simple agent might just need Neon for data, Claude for reasoning, and basic logging. A complex multi-agent platform needs the whole stack with queues, sandboxing, and sophisticated monitoring.
The common thread is infrastructure that matches agent behavior. Traditional tools built for steady workloads break down when agents create unpredictable spikes, need instant provisioning, or operate across multiple isolated environments. Start simple, measure what matters, and add tools as your agent's requirements become clear.
[story continues]
tags