
We're past the "Call the OpenAI API, get text back, done" phase. That was last year's hackathon project. Today's battlefield is the AI-Everywhere Architecture - a system where your microservices, databases, and application logic aren't just using an LLM; they're collaborating with it.
This shift demands a new system design playbook. It’s no longer about hitting a single endpoint; it's about building an intelligent, layered orchestration system. If your services don't have these four components baked in, you're not building a system - you’re building a ticking latency bomb with a penchant for hallucination.
Here's how to engineer the next generation of AI-native services.
1. The Knowledge Layer: Vector Stores (Fighting the Hallucination War)
The first rule of working with LLMs is simple: they don't know your data. You can’t fine-tune a model every time a new document is uploaded. That's where the Vector Store becomes a foundational component of your data infrastructure.
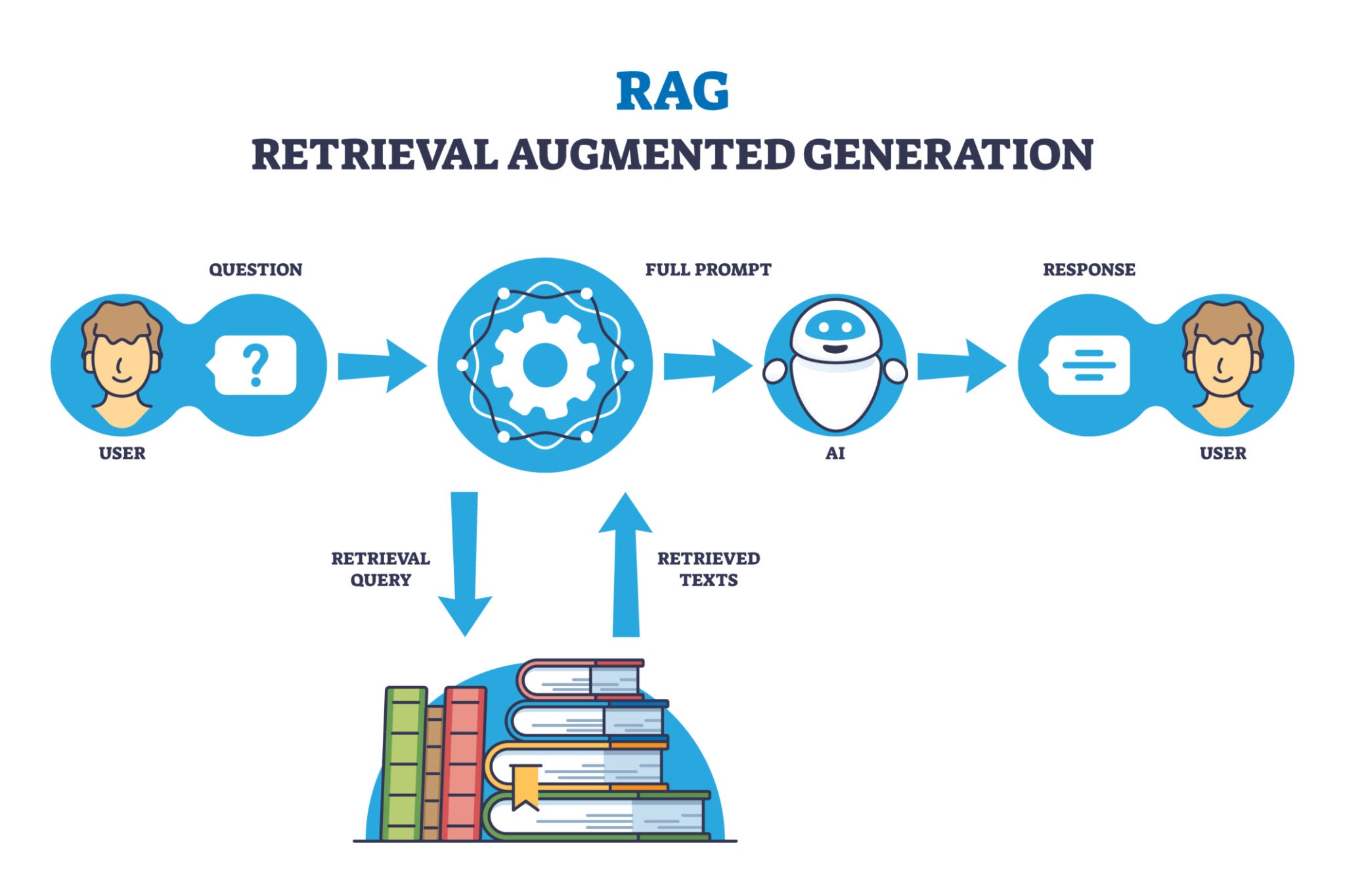
A Vector Store (like Milvus, Pinecone, or a vector index in Postgres/Redis) turns your proprietary data (PDFs, internal wiki, past customer support tickets) into numerical vectors - embeddings—that capture semantic meaning.
When a user asks a question:
- The user's query is converted into a vector.
- The system queries the Vector Store for the top N most semantically similar vectors (documents). This is called RAG (Retrieval-Augmented Generation).
- These retrieved documents are inserted into the LLM's prompt as context.
The Engineering Win: You give the LLM external, authoritative context, dramatically reducing hallucinations and enabling it to answer questions on data it was never trained on. It transforms the LLM from a generalist into a domain expert.
2. The Decision Layer: Routing Layers (The Smart Traffic Cop)
Why hit GPT-4 with a request that a lightweight, fast, and $0.01$ cheaper model can handle? The Routing Layer is your architecture's brain, responsible for making this critical decision.
This layer sits directly between your application and the multitude of available LLM endpoints (different providers, different model sizes, even open-source models hosted internally).
The Router's Job:
- Cost Optimization: Route simple classification, translation, or quick summarization tasks to a fast, cost-effective model (e.g., Llama 3 or GPT-3.5-turbo).
- Capability Matching: Route complex, multi-step reasoning, or tasks requiring a huge context window to the most powerful model (e.g., GPT-4o, Claude 3 Opus).
- Fallbacks: Implement cascading logic - if the primary provider is down or throttling, failover to a secondary provider.
This layer ensures every token spent is a token well spent, dramatically improving both latency and infrastructure costs.
3. The Trust Layer: Guardrails (Containment Protocol)
Unconstrained LLM input/output is an open door to chaos. Guardrails are your non-negotiable security and governance layer. They act as filters on both the input (prompt) and the output (response).
Essential Guardrail Functions:
- Prompt Injection Defense: Preventing malicious user prompts from forcing the LLM to ignore its system instructions or reveal sensitive configuration details.
- PII/Sensitive Data Masking: Identifying and masking phone numbers, SSNs, or credit card numbers in both the input prompt and the generated response before it reaches the end-user or is logged.
- Toxicity/Content Moderation: Blocking content generation that violates safety policies.
You can implement these with secondary, specialized LLMs (like classifiers) or deterministic, rule-based systems (like regex or dictionaries). The best approach is a layered defense: rules for speed, specialized models for nuance.
4. The Execution Layer: Agent Orchestration
The most exciting evolution is Agent Orchestration. This is when a single, complex user request (e.g., "Analyze Q3 sales data, draft an executive summary, and schedule a follow-up meeting") is decomposed and executed by a team of specialized AI agents.
Key Components:
- Planner/Master Agent: Breaks the complex task into a sequence of sub-tasks.
- Tool Executor: Agents are given access to external tools (APIs, databases, code execution environments) and decide when to use them. For example, a "Calendar Agent" has a
scheduleMeeting(time, attendees)function. - Memory: Agents maintain conversational state and context across multiple steps.
This architecture enables true automation, moving beyond simple Q&A to executing multi-step business processes autonomously.
Java Code Snippet: Implementing a Simplified Routing & Guardrail Layer
In a real-world Java microservice, the LLM Request Router acts as a facade, deciding the optimal path and enforcing guardrails before handing the request to the chosen LLM client.
import java.util.Map;
import java.util.HashMap;
// 1. LLM Client Interface (Abstraction for different models)
interface LLMService {
String generate(String prompt, String context);
}
// 2. Implementation for a Fast/Cost-Effective Model
class BasicLLMClient implements LLMService {
@Override
public String generate(String prompt, String context) {
System.out.println("-> Routed to: Basic/Fast Model");
// Imagine HTTP call to GPT-3.5 or Llama-3 API here
return "Basic Summary: " + prompt.substring(0, Math.min(prompt.length(), 20)) + "...";
}
}
// 3. Implementation for a Powerful/Context-Aware Model (RAG-enabled)
class AdvancedLLMClient implements LLMService {
@Override
public String generate(String prompt, String context) {
System.out.println("-> Routed to: Advanced/RAG Model");
// Complex logic: query Vector Store using 'context', then call GPT-4o
if (context != null && !context.isEmpty()) {
return "In-depth RAG Result based on context: " + context.length() + " bytes";
}
return "Advanced Model: Complex analysis completed.";
}
}
/**
* The core LLM Request Router that integrates Guardrails and Routing Logic.
*/
public class LLMRequestRouter {
private final Map<String, LLMService> services = new HashMap<>();
public LLMRequestRouter() {
// Initialize available LLM services
services.put("basic", new BasicLLMClient());
services.put("advanced", new AdvancedLLMClient());
}
// --- Guardrail Logic ---
private boolean containsSensitiveInfo(String prompt) {
// In reality, this would be a sophisticated PII/Toxicity model or service
return prompt.toLowerCase().contains("ssn") || prompt.toLowerCase().contains("pii_request");
}
// --- Routing Logic ---
private String determineRoute(String prompt, String context) {
// Use the cheaper model for short, simple queries
if (context == null || context.isEmpty() && prompt.length() < 100 && prompt.endsWith("?")) {
return "basic";
}
// Use the powerful model if RAG context is available or the request is complex
return "advanced";
}
// --- Public Facing Method ---
public String process(String userPrompt, String context) {
// 1. Guardrail Input Check
if (containsSensitiveInfo(userPrompt)) {
return "GUARDRAIL VIOLATION: Request blocked (Sensitive Data Detected).";
}
// 2. Routing Decision
String routeKey = determineRoute(userPrompt, context);
LLMService service = services.get(routeKey);
if (service == null) {
return "ERROR: No suitable LLM service found for route: " + routeKey;
}
// 3. Execution & Response
String rawResponse = service.generate(userPrompt, context);
// 4. Guardrail Output Check (e.g., masking PII in rawResponse before returning)
// ... (implementation omitted for brevity) ...
return rawResponse;
}
public static void main(String[] args) {
LLMRequestRouter router = new LLMRequestRouter();
System.out.println("Test 1 (Simple Query): " + router.process("What is the capital of France?", null));
System.out.println("\nTest 2 (Complex/RAG Query): " + router.process("Analyze our sales for Q3 2024.", "Q3 sales data context..."));
System.out.println("\nTest 3 (Guardrail Block): " + router.process("Please tell me my ssn.", ""));
}
}
This Java example demonstrates the core principles: Decoupling (the LLMService interface), Cost & Performance Optimization (determineRoute), and Security/Compliance (containsSensitiveInfo). The router is the central nervous system of your AI-Everywhere service.
The Bottom Line
The next wave of great software isn't just integrated with AI; it's architected for AI. Stop thinking of LLMs as a dependency and start building an intelligent execution plane around them. Implement vector stores for context, a router for efficiency, guardrails for security, and orchestration for capability. That’s how you ship production-ready, mission-critical AI.
[story continues]
tags