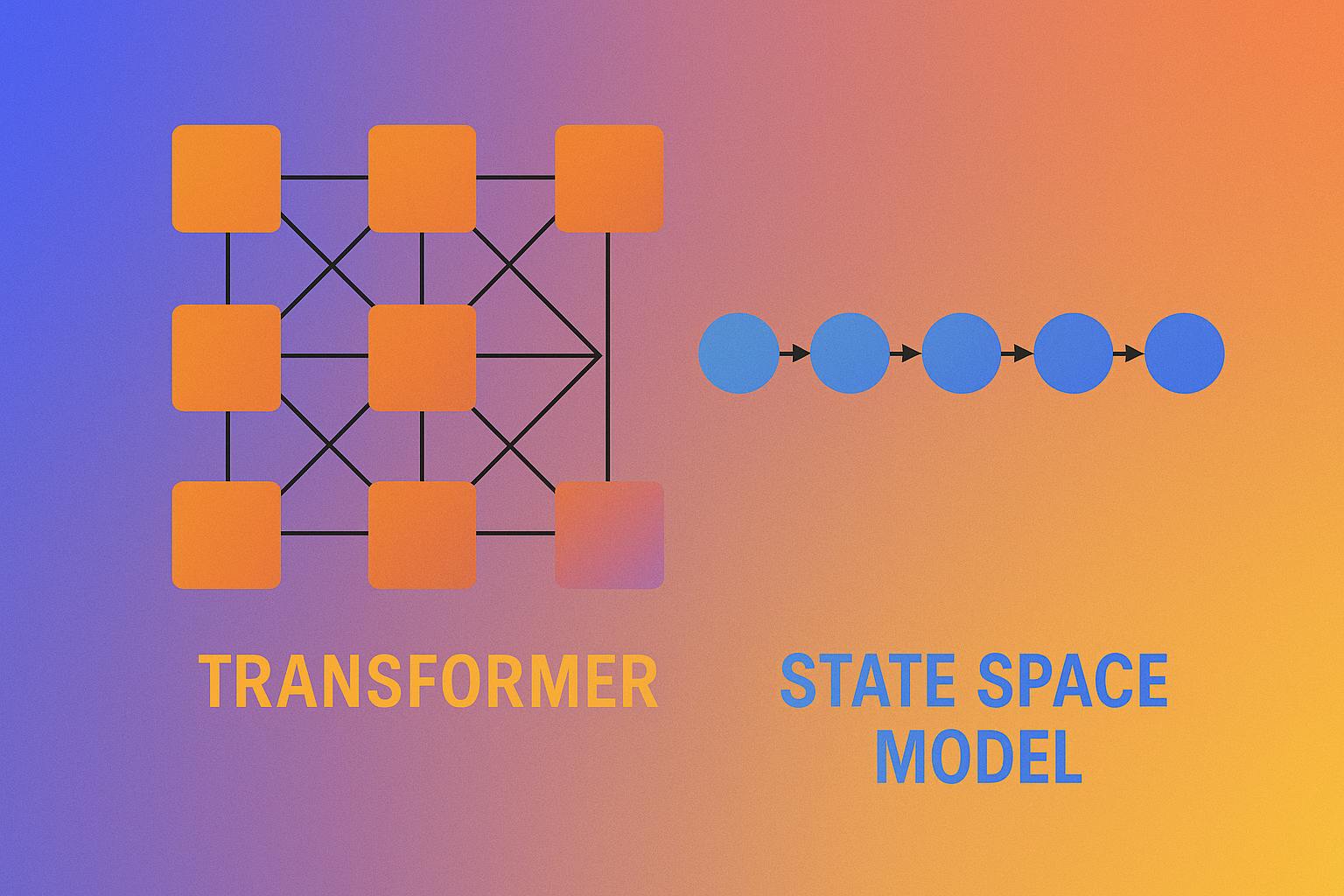
The AI industry's obsession with Transformers might finally be waning. While OpenAI and Google with their extensive language models capture the public attention, there is a more discreet change taking place in the way AI is implemented into production systems, or how it is AI is utilized within industry processes.
Among practitioners who are less concerned with competition metrics and more focused on speed, efficiency, and scalable solutions, newer versions such as Mamba of State Space Models (SSMs) appear to be winning some favor. The theoretical base for the SSM approach has existed for some time, but its practical application in competition against Transformers is relatively recent.
The Problematic Yet Powerful Legacy of Transformers
Every popular AI service like ChatGPT, GitHub Copilot, or Google Search still heavily rely on Transformers for AI capabilities. They’re flexible, well-documented, and backed by a huge ecosystem of open weights, tutorials, and deployment frameworks.
But teams trying to ship production AI know the catch: once your input gets long, the costs start piling up.
- The self-attention mechanism that gives Transformers their power also makes them scale poorly with input length.
- Memory usage can spike unexpectedly.
- Latency becomes hard to control.
These aren’t theoretical concerns. When a user is stuck staring at a loading spinner while your model processes their 20-page contract, that’s not a “research problem.” It’s a product blocker.
SSMs: The Engineering-First Alternative
The State Space Models (SSMs) approach sequence modeling differently. Rather than computing attention across the entire input, they utilize state transitions to model dependencies. That gives them a number of advantages:
- Linear scaling with input length (versus quadratic in Transformers)
- Predictable memory usage that stays steady, even as context grows
- Faster inference, especially on long-form data
- Easier deployment on constrained or edge hardware
These features were integrated into a model architecture designable within Mamba that was released in late ‘23. For a lot of teams, it just clicked. Even as some of the researchers held on to their skepticism, engineers focused on what really mattered: it was faster, less memory intensive, and more permissive in during demand resource allocation.
Real-World Results from Deployment
In one recent project, I was tasked with building an AI system that handled freight documents like invoices, bills of lading, and customs entries. These documents were not in the form of simple prompts. They were chaotic, multi-page documents that exceeded 10,000 tokens per file.
We built and deployed a Transformer-based pipeline to address the issue. Although this strategy was successful, we encountered several common roadblocks quickly:
- Inference took over a second per document
- GPU memory requirements were excessive
- Scaling during peak load became a continual pain point.
While other structures such as Mamba were starting to emerge, we were looking at benchmarks, internal performance modeling, and other available open-source implementations. We noticed that switching to an SSM-based structure would likely:
- Decrease latency by close to 50% on long inputs
- Reduce memory overhead for better scaling
- Sustain or improve precision on most extraction tasks
Not only did they shift the product’s accuracy and performance, but this change improved previously impossible tasks due to performance restrictions.
Select An Architecture According to the Needs of the Product
Your product’s boundaries will determine whether you use Transformers or SSMs. Here’s a bird’s eye view comparison that matters for production value.
|
Product Constraint |
Transformer |
State Space Model (SSM) |
|---|---|---|
|
Short inputs (< 1K tokens) |
Strong performance |
May be unnecessary |
|
Long-form documents |
Struggles with scaling |
Handles efficiently |
|
Real-time interaction |
Often too slow |
Much better latency |
|
Limited compute |
Requires significant hardware |
Runs efficiently at scale |
|
Ecosystem maturity |
Extremely mature |
Catching up quickly |
Implementation Example: Document Processing Pipeline
Here’s a simplified example to illustrate the implementation differences
1. Shared Setup: Extract Text from PDF
import pdfplumber
from transformers import AutoTokenizer
def extract_text(path):
with pdfplumber.open(path) as pdf:
return "\n".join(
page.extract_text() for page in pdf.pages if page.extract_text()
)
pdf_text = extract_text("freight_invoice.pdf")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
inputs = tokenizer(pdf_text, return_tensors="pt", truncation=False)
2. Mamba-Based Inference
from mamba_ssm.models import Mamba, MambaConfig
import torch
mamba_config = MambaConfig(d_model=512, n_layers=4)
mamba_model = Mamba(mamba_config)
with torch.no_grad():
mamba_outputs = mamba_model(inputs["input_ids"])
3. Transformer-Based Inference
from transformers import BertModel, BertConfig
bert_config = BertConfig(hidden_size=512, num_hidden_layers=4)
bert_model = BertModel(bert_config)
with torch.no_grad():
transformer_outputs = bert_model(inputs["input_ids"])
The Transformer setup works; but on long documents, you’ll quickly notice the difference in latency and memory usage. With Mamba, the same task runs faster and scales more gracefully, especially in high-throughput environments.
Why This Matters in Practice
What is happening here is far more than selecting a new model. It indicates something else: the engineering teams perceived to have ‘grown up’ in how they reason and design AI infrastructure. Rather than mindlessly optimizing benchmark scores, there is more product-thinking in the room:
- What can we accomplish in terms of design if inference is significantly quicker and cheaper?
- What models could potentially enable us to ship with minimum impact to our infrastructure budget?
- How efficient will this system be after six months, and after six product updates down the line?
Not every team asking those questions will find SSMs compelling. But those that do, they absolutely will.
What This Means for Product Teams Moving Forward
Transformers won't be wiped out completely; SSMs don't have to. The right tool still depends on what you’re building. However, if the product handles lengthy documents, requires immediate feedback, and has to operate within moderate system requirements, SSMs should be considered.
This change in approach is not as simple as moving from one model to another. The one switch that is needed is from "research driven decisions" to "product driven decisions". This change has been overdue for some time now.
Amid the fast paced world of AI, these changes are not essential and desirable, for some of the most products that are beneficial and help you go live end up being overshadowed.
[story continues]
tags